こんにちは。TIGの伊藤です。
9/2に開催された「Grafana Meetup Japan #6|どうする?Grafanaする!」にLTで登壇してきたので、参加レポートも含めて記事にします。当日のYouTubeもアーカイブ公開されているのでそちらと合わせて読んでいただけると幸いです。

自身のLT: Grafana Alloyのconfig運用
今回、私が登壇したネタになります。資料は以下です。
Grafana Alloyの利用経緯
私が今所属しているチームでは、従来EC2で動かしていたアプリケーションをECS on Fargateで稼働するようにリアーキを実施しました。また、合わせて利用していた監視やジョブについても再選定の対象とし、コンテナとの相性、今後の展開性も含めてGrafanaを利用しました。
その時、コンテナから様々なメトリクスデータを収集する時に利用するツールとしてGrafanaと合わせてAlloyを選定しました。
Alloyの導入の時に考えたこと
AlloyはHCL(HashiCorp Configuration Language)に近い記法で書くことができ、個人的には馴染みが良かったのですが、実際の環境や運用を考えてみると
- アプリケーション
- Java
- Go
- ミドルウェア
- 稼働環境
- EC2(VM)
- ECS on Fargate(コンテナ)
- 環境面
- 本番
- ステージング
- 開発
と様々な要因で統合は厳しいと判断しました。
しかし、なるべく省力化を図るために、以下の2つを検討し、実践しました。
環境変数で吸収
Alloyにはsys.envという形で環境変数の値を取得できるライブラリがあります。
このライブラリを以下の形で使うと、環境変数の値が取得でき、例示している (LOKI_PUSH_URLに向けて)ような収集したデータのプッシュ先を変えることができます。
loki.write "loki_destination" { endpoint { url = sys.env("LOKI_PUSH_URL") } } |
起動時にファイルを取得する方法
環境変数で環境面に対応することはできましたが、もう一つ、Alloyが収集する対象のアプリ、ミドルに対しての適用です。
様々なログのパス、メトリクスのパスなどはどうしても環境変数で吸収することは難しいので、ファイルごと分離を行い、Alloyコンテナが起動する時にファイルを取得する形式としました。
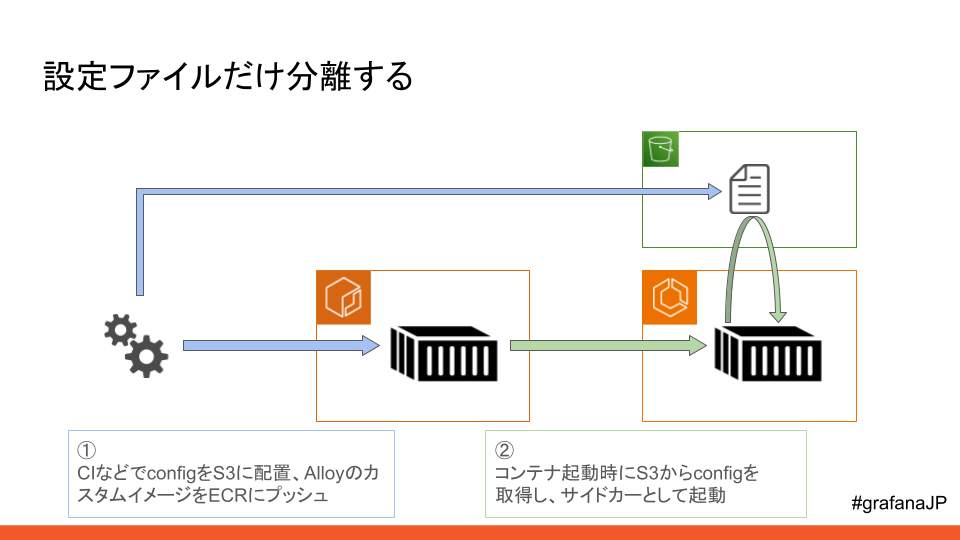
この2つの方法を織り込むことで、複数の環境面、複数の収集対象に適用することができました。
いただいた質問
当日、質問を募集するslidoにていただいた質問について、当日で回答できなかったので、こちらで回答します。
Q. Alloyを運用していて、パフォーマンスの問題はありましたか?Otelのcollectorだと、必要なパッケージだけ入れてビルドする、という運用ですが、Alloyはデフォルトで全部盛りと聞いていて、ナレッジあればお願いいたします
A. 全部盛りであると理解しています。私のチームでも実際にAlloyからMimir、Lokiへ転送しているため、このほかGrafanaのスタックに対しても使えます。
Q. Alloyは1つのコンテナでメトリクスとログ全て送信していますか?それとも用途によってコンテナを分けていますか?
A. 今回は1つのコンテナで全てメトリクスもログも収集、送信しています。
Q. Remotecfgを使っていないという認識で合っていますか?もし使わなかった理由などあればご享受頂けば幸いです。
A. remotecfgは知らなかったです。ドキュメントを見てみたのですが、その過程としてremote.s3というコンポーネントがあるらしく、これを使うと以下のように書けそうです(未検証のため確認が必要です)。
remote.s3 "external_config" { path = "s3://bucket-name/alloy/config.alloy" } |
他にもアクセスキーなどについても設定できそうでした。今回のユースケースであればFargateにタスクロールがついているので、そちらで賄えるのではないかと考えています。
そのほかのセッション、LT
Grafanaスタックをフル活用したオブザーバビリティ基盤の紹介
今回のメインセッションであるGO株式会社のQuentinさんによるセッションでした。
GOでは100を超えるマイクロサービスをAWS、およびGoogle Cloud上のKubernetes基盤で稼働させており、これを「Kenos」と呼称しているそうです。
この大きなクラスターを稼働させる上でオブザーバビリティがより重要になってきていましたが、SaaS監視ツールの料金高騰や問い合わせ対応時にツールが分散している煩雑さから、Grafanaのスタックを徐々に自前で導入しています。
規模感は日々ログがTBオーダー、メトリクスやトレースでもGBオーダーと、私も自前で構築をしているものの桁が違いすぎて非常に驚いたこともありますし、さらにその規模を安定して運用されているところが興味深かったです。個人的に改めて納得したポイントではありますが、同じツールでも自前で運用するか、SaaSで展開するかは扱っているデータサイズにも依存していると思いました。ただ、Grafana Cloudもあるので、ある程度運用負荷が高いなどがあれば切り替えることができるのもGrafanaの良さだと感じました。
また、Grafanaの自前運用での振り返りとして話されていたのは、初期の設定の躓きであったり、運用の安定性などについて自身でも気をつけたいところでした。例えば、Grafanaでの障害切り分けをする際に、Grafana自体が過負荷になりサービスダウンしてしまうといったことがあったようで、ここはGrafana自体のチューニングであったり、Loki, Mimirまで含めて設定を洗っておこうと思います。
そのほかの話については以下のブログにも公開されており、見返してみると私もだいぶお世話になったブログでした。
Grafanaをリバプロ配下で動かすときにやること ~ Grafana Liveってなんだ ~
Grafanaがサクサク、ヌルヌル動く秘密の部分を解説してくれるセッションでした。Grafanaにはストリーミングの機能があり、ここではWebSocketを使っていますが、これをNginxなどのリバースプロキシ経由でどう使うか、使えるようにするか解説されました。
私自身は過去、複数の環境を束ねているNginx越しでGrafanaを触ろうとして方式を変えた記憶があったので、改めてトライしてみようと思いました。
Grafana MCPサーバーによるAIエージェント経由でのGrafanaダッシュボード動的生成
Grafana MCPサーバを実際に使って利用できるダッシュボードを作成するセッションでした。今回はClaudeに対して自然言語で入力、対話を続けていき、最後は
OSS版でも対応している限りMCPサーバは使えるようですので、また試したいものが増えてしまいました。
イベント中の小話
今回ははGrafana Labsの方もいらっしゃったのですが、なんとついに立ち上がった日本法人の入社初日だったらしく、日本のGrafanaのコミュニティが大きく変わりそうな予感がしました。そんなタイミングであることはもちろん知らなかったのですが、LTをここでできたのは個人的には良かったなと思いました。
まとめ
今回はLTという形で登壇をしつつイベントに参加しましたが、課題を持って、感じてイベントに参加するとイベント後の懇親会も含めてより有意義になることを改めて感じたので、ちゃんと話題としても持っていこうと思いました。
また、今回は実際にto C向けサービスを運用している立場の声を聞くことができたので、よりどう活かそうか、取り込もうかと考えられたことも大きかったので、自身で取り組んでいる構成も見直そうと思います。
今後の日本におけるGrafanaのコミュニティがより盛り上がるように微力ながら頑張っていけたらと思います。