PostgreSQL 18がリリースされました。気になる新機能やパフォーマンスアップなどが盛りだくさんです。当ブログでは今回のアップデートに限らずデータベース一般ネタも含めた連載記事を執筆します。
| 日付 | 執筆者 | タイトル |
|---|---|---|
| 10/6(月) | 澁川喜規 | v18で対応したUUIDv7とv4の比較(この記事です) |
| 10/7(火) | 山本竜玄 | explainをマスターするぜ |
| 10/8(水) | 真野隼記 | 仮想生成列 |
| 10/9(木) | 岩堀敦 | pg_dump |
| 10/10(金) | 市川裕也 | 現場で行った性能チューニング |
| 10/14(火) | 村田 靖拓 | B-treeインデックスのスキップスキャン |
UUID v7
PostgreSQL 18ではUUIDv7生成に対応しました。今までのUUID v4(完全ランダム)は主キーとして使うと、ソート順で扱おうとするPostgreSQLの内部構造のB-Treeと相性が悪く、さまざまなノードへのアクセスが必要になるため、相性が悪いとされていました。RFC-9562で標準化されたUUID v7は先頭がタイムスタンプであり、キーをソートすると、必ず作成した順序になります。そのため、生成順にデータを挿入したとしてもパフォーマンスが落ちにくくなる、だからいいんだ、ということのようです。
0 1 2 3 |
B-Treeはその名の通り木構造です。ソート順でデータが並ぶため、近いデータへのアクセスであればキャッシュ効率も上がります。
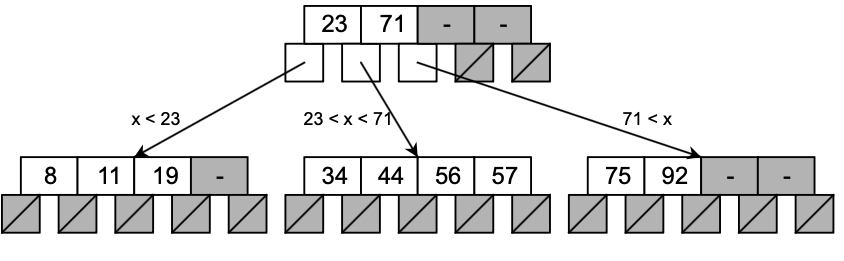
- Wikpedia B木より引用
実際に検証してみる
実際に速度が変わるかをプログラムを作って検証しました。Dockerのpostgres:18-trixieイメージに対して検証プログラムから100万行ほどのレコードを投入しています。
- 通信自体の往復が支配的にならないように(I/Oの差が出やすいように)、100件ずつ入れるようにした
- UUIDはローカルで生成して送る方式と、DBの関数で生成する方式の両方を試した。ローカル生成は生成時間を抜いた時間で計測した
検証コードはこちらに置いてあります。検証コードはアイコンが可愛いと話題のKiroで作成しています。
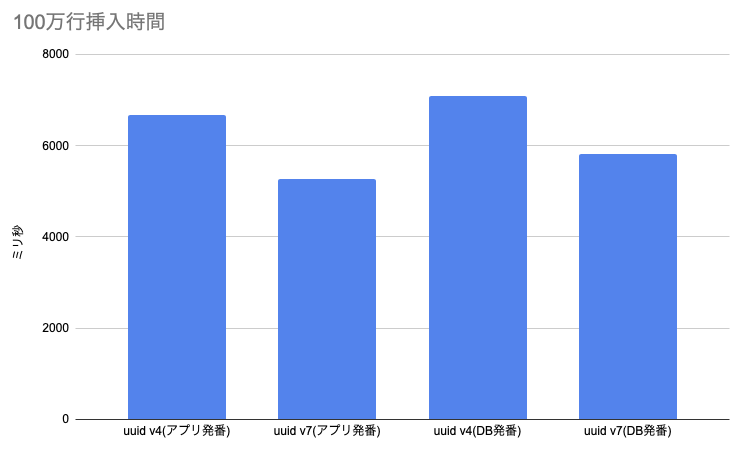
こちらが結果です。アプリで生成してから送る方式だと20%ぐらい時間が短くなりました。DB側で発番する場合はそのぶんちょっと時間が伸びるのでアプリ発番のものと同じグラフに載せない方が良いかもしれませんが、まあだいたい傾向としてはv7の方が早そう、というところが見えました。
Macbook AirのM3で計測しましたが、ファンがなく温度が上がると目に見えて性能が変わるので、条件違いのケースを1通り実行して、また繰り返して、というのを3回行って平均しました。まあそんな感じなのであまり細かいスコアは気にしないでください。
時間順のデータの範囲アクセスとか、直近のデータを頻繁にアクセスする場合にデータが一部のツリーに集まるので変更したい箇所のディスクキャッシュが効きやすくなりI/Oパフォーマンスがあがります。これは書き込みのときだけではなく、読み込みにも効きます。
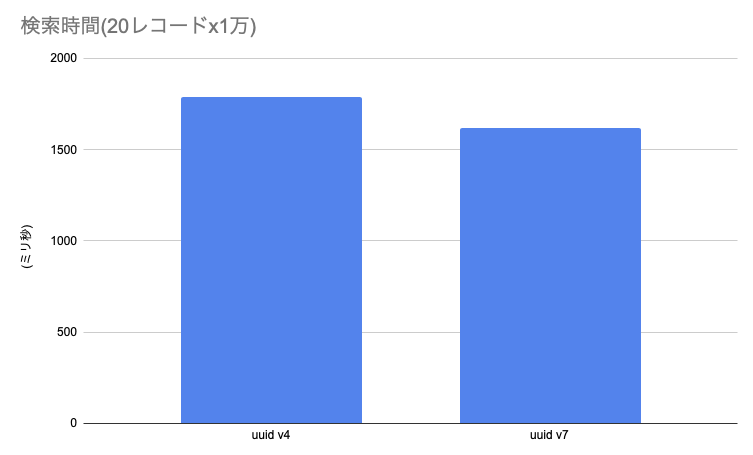
20レコードを検索するクエリーを1万回投げた時の処理時間の結果が以下のグラフです。100万行のデータのうち直近の5%(5万件)の範囲のIDをランダムに20個ピックアップし、SELECTで探すテストになっています。10%ほどUUID v7を使った方が高速にはなっています。なお、直近1%(1万件)の範囲で探索するとさらに10%ほど早くなりそうでした。
なお、「IDがランダムでも、範囲アクセスするキーがインデックスされていれば問題ないのでは?」と思われるかもしれません。たしかに「どのデータがマッチするか」はインデックスが作成されていれば高速にアクセスできるはずですが、インデックスを元に実際のデータを参照する場合にB-Treeをたどって参照するはずで、配置場所が集中していたらそこの部分が高速になる、ということのはずです。
実はPostgreSQL 18以前でもUUIDv7は使える
上記の検証プログラムはPostgreSQL 17でもuuid v7のDB発番以外は使えます。
UUIDを使うメリットというのは、極めて重複しにくいキーをデータベース以外で作れるという点にあります。SERIALを使う場合、かならずデータベースへのアクセスが必要になります。ウェブフロントエンドから何かデータを登録する、それも一度にコミットできずに何回かに分けてデータ登録を行って完成させるようなケースを考えてみると、フロントエンドでキーを発番してもらい、それを使うのか、フロントエンドだけで発番し、仮データとして登録して最後にまとめてコミット、みたいな方式にするか、という違いが出ます。特に親子関係があり、親のキーを子供に渡さなければならないみたいなケースでやりとりが増えると大変です。
UUIDv7を使うケースで、今回のベンチマークアプリのようにv7形式のUUIDを事前に発行してそれをUUID型の主キーのデータのコミットに使うというやり方で、UUIDのメリットを受けつつ、パフォーマンスも劣化を減らすということが可能です。あくまでも、今回v18でできるようになったは「DB側での発番」であって、事前発番なら前のバージョンでも使えます。ここ大事です。
なお、今回は非同期I/O対応で高速になったというのも見かけたのですが、同じプログラムで17と18で比べたところ、そこまで大きな差はなかったです。気持ち10%ぐらいは早くなった?
まとめ
UUID v7のパフォーマンスの検証を行いました。v18の目玉機能的に言われることが多いのですが、前節で書いた通り、アプリ側で発番するのであればv18でなく使えます。今回増えたのはあくまでもDB側での発番です。
もちろん「v18になったら主キーはどんどんUUID v7にしていこう」というのは早計です。
- 人間が目で見て扱う場合にはUUIDはユーザーフレンドリーとは言い難いのでSERIALが良いケースもある
- 型番や社員番号などのビジネス的に意味のあるナチュラルキーがユニーク性が担保できるのであればマスターデータなどではそちらを使うべき
- セキュリティ的に日付でキーの範囲がだいぶ下がってしまうのでIDの推測可能性や絞り込みがだいぶ簡単になってしまうため、挿入や検索が多少劣化してもUUID v4が良いケースもある