秋のブログ週間の5本目です。
3年前の秋のブログ週間でデータベースと向き合う決意というエントリーを書きました。3年経ちましたが、多少ベクトルは変わりましたが今も基本的な気持ちは変わっていません。むしろ、「生成AIによって自然言語で気軽に作れるようになった」ことで、SQLの敷居は大きく下がりました。
DFDのガイドライン作りを始めた
今年はDFDの本が出ました。5月にブログも書きました。
本書を読んだことで、フューチャー社内のDFDが何を工夫してどのように活用してきたのか、というのを相対的に見れるようになりました。フューチャースタイルも有志で公開しているガイドライン集にいつか入れられたらいいな、ということを思いました。そして、いつか他社のDFD図の発展がどのようになっているのかとかも世の中に出てきて、50年分の図の進化が行われると良いな、という気持ちを新たにしました。
言ったからにはきちんとやろうということでざっとGoogle Docsで20ページぐらい書いて社内の有識者からコメントもらったりしているところです。年内にはある程度目処をつけたいところです。DFD本の表紙にも「いにしえの技術」と書かれているぐらいなので、オリジナルのものをそのまま使っている人はレアかと思います。だいたい各社の中で独自の進化を遂げたDFDを使っているのではないかと思っています。今のガイドラインも社内のDFDの知見のガイドライン化ですし、他社の人が触れる場合には「どこがオリジナルか」というのを明示するのは大事かな、と思い、
DFDの原典とされる本も買って読み始めました。

構造化分析の本は初めて読みましたが、自分がこの手の勉強をした、UMLやらオブジェクト指向分析よりも実は筋がいいのでは、と読みながら思ったり。2000年ごろのアジャイルブームはUMLの複雑なモデリングへのアンチテーゼだったと思いますが、あのときにUML(を売りたいベンダー)が否定してきた過去のシンプルな手法に目をもっと向けられていたらなぁ、というのはちょっと思いました。
あと、この本で強調されていることは「DFDではコントロールの流れは書かない」ということです。これはDFDのガイドラインでも触れていましたが、この特性は2つの点で大事だな、と思いました。
1つは以前書いたReactのDFDがなぜうまくいったのかという点です。コントロールフロー≒手続きは、いわゆる条件式とかループです。これらはDFDの1つ1つのプロセスの中に閉じ込められているものです。一方、今時のウェブフロントエンドは手続きではなく、宣言的に書くという思想で作られています。どちらもコントロールフローを見せない仕組みなので相性が良いのは自然なことだったんだな、と思いました。
もう1つはコントロールをかかない、そのままソフトウェアに落ちたりしないという点ですね。2000年初頭はCASEツールとかその手のツールで設計することでソフトウェアの自動生成などを行って効率アップ、というのがやたら喧伝されていました。その手のツールからすると、書いてもそこから生成できなければ描くだけ無駄ということで、DFDが2000年代に冷遇された理由はこれだったのかもな、というということです。
2Way SQLを作り始めた
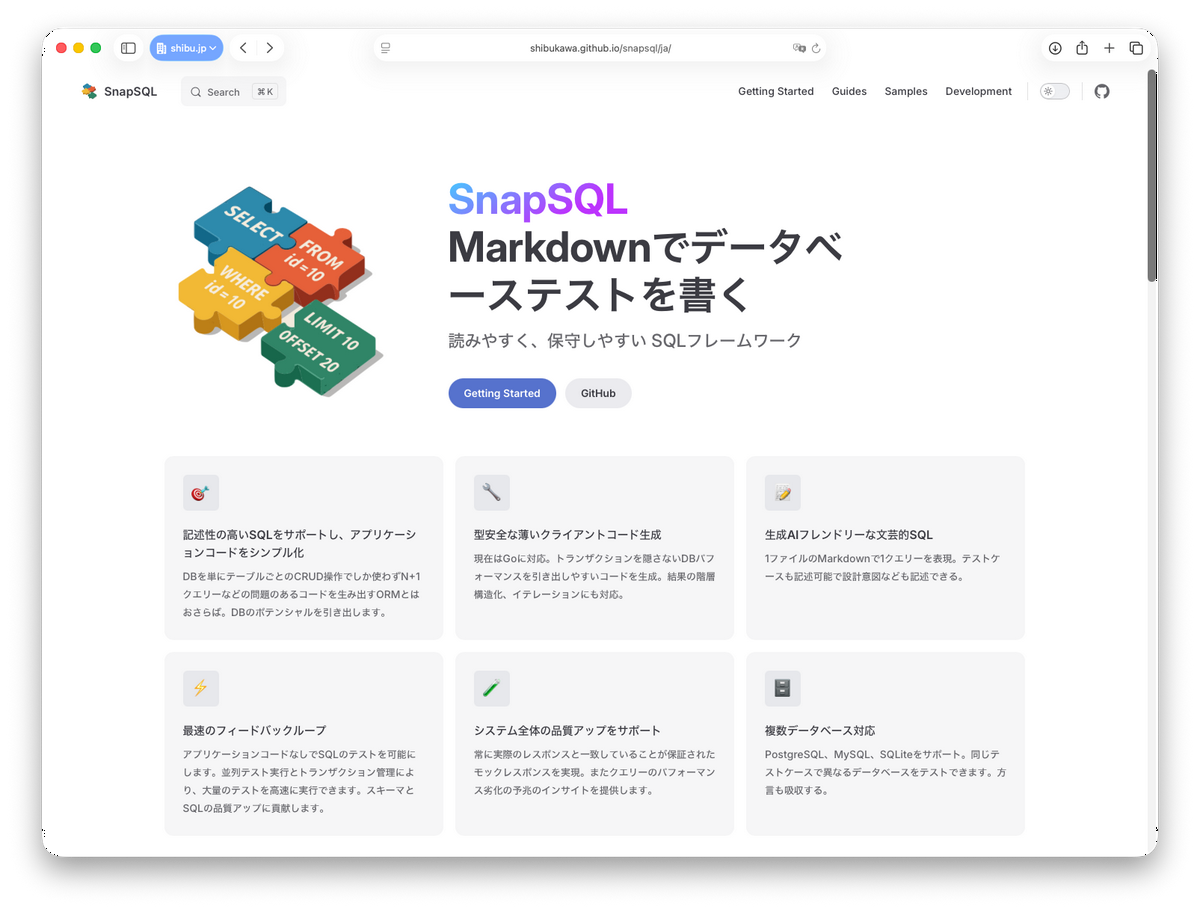
今年ちょくちょく生成AI使ってみた外部発表をしていますが、その題材として作っているのが2Way SQLのライブラリです。Goで作っていますが、ランタイムはGoに引き続き、Pythonとかも実装しようとしています。これも、3年前のエントリーでも作っていると書いていましたが、まあ何度目かのチャレンジ。だいたいこの手のやつは3回ぐらい作って初めて納得いくものができるというのが実感ですが、実際、3回目ぐらいですかね。これまでで一番コード行数は多いかも。5ヶ月ぐらいで11万行ぐらい?
生のSQLに制御コメントを入れることでそのままDBにも投げられるし、アプリケーションコードの中でSQLのテンプレートとしても使える、というのが2Way SQLです。2Way SQL自体はたくさん実装が世の中にはあるのですが、だいたい式言語が組み込まれていて、それがJava依存のライブラリで、Java以外ではマイナーな存在となってしまっています。そこも、GoogleのCELを採用することでいろんな言語で使えるようにしたいなと思っているところです。
- ソースは、SQLもしくは、文芸的プログラミングスタイルのSQLが書かれたMarkdown
- SQLはユーザーが作るが、レスポンスの型と呼び出しコードは自動生成
- BlogPost -> Commentのように、親子関係がある要素群を子スライス(配列)にまとめて返す
- テスト機能内蔵。テストのレスポンスを使ったモック機能も内蔵
- UPDATE/DELETEでWHERE句がない(条件なしで前適用」場合にオプトアウトでエラーチェックを追加
だいたい、どのライブラリも「クエリービルダー」として生SQLを元にWHERE句の条件を足したり減らしたりしたSQLを組み立てる感じです。だいたいの2Way SQLのライブラリは呼び出すところぐらいですが、Goのsqlcのように、型がしっかりついた関数を生成します。クエリー情報を元にサブクエリとかCTEの中も追いかけて型推論しています。WHERE句の条件でレスポンスが単数になるか複数になるかとかも静的解析しています。
// 結果のオブジェクト |
トランザクションは隠さないようにしており、2つ目の引数はsql.Connかsql.DB, sql.Tx何でも受けられるようにしています。3つめ以降はテンプレートにパラメータがあればそれが入り、型安全な関数となっています。
他にもPlaywright Lightnings #1で発表した、E2EテストのFixtureやリクエスト後のDBの状態をテストするツールであるgithub.com/shibukawa/dbtestifyの機能も取り込み、アプリケーションコードを実装しなくてもSQLだけでユニットテストできる機能なども入っています。このテストの期待されるレスポンスをモックとして返せるようにもしています。「モックを使うと実装とずれても気づけない」という問題があったりしますが、その問題を解消できるかな、と。
このツールでやっているのは、SQLをトークン分割して構文解析をしてASTを組み立てて、エラーチェックなどをしつつシンプルな命令列に変換してから、最適化を行なって最終的にGoなどのコードを生成する、という動きをします。生成時に文字列結合(CONCAT, ||)、キャスト(CAST( AS type), ::type)や日付関数などは生成先に合わせて吸収するとかもしてます。まあコンパイラですね。パーサコンビネータから自作してます。ツール自体は結構なロジックの量になっていますが、静的なコードを生成するようにしており、アプリケーションが太らないようにランタイムの依存はほとんどないという思想でやっています。最後のコード生成部分はなるべく薄くしているので、いろんな言語に対応させたいです。
サンプルコードを作って動かしてみたりしていますが、Goに関しては大体できてきたかなというところです。ドキュメントも昨日、今日でだいぶブラッシュアップしました。生成AIにお願いすると無い機能まであると説明を書き出すのでなかなか大変ですね。
実際にプロジェクトで使えるものを、という意識で作っていますが作ること自体が勉強になりますね。DBMSごとに書けるSQLの違いとかを意識することになりますし。生成AIにきくとぱっとまとめを作ってくれるけど間違っていることがあるのでまた調べますし。昔は使えなかったけど今は使えるSQLiteのRETURNINGとかそういう感じで。
次のステップ
だいぶデータベースへの苦手意識も減りデータベースのモデルの議論も積極的に行えるようになってきました。
2Way SQLも「しっかりしたのを作りたい」というのをずっと思っていたところ、生成AIが重い腰を上げてくれてパッと走り出すことができました。この手の盆栽的な目標があると、生成AIの無料枠が降ってきたときに「お、機能追加するぞ!」というネタになっていいですね。ぼちぼち、Python、Java、TypeScriptあたりのコード生成は追加していこうと思っています。Pythonはasyncioにきっちり対応(むしろそれ以外サポートしない)勢いでやろうかと思っています。
開発環境の変化、生成AI活用という点で、GitHubやGitLabでプレビューしやすくて生成AIフレンドリーなツール群、というのが今後は求められていく流れは変わらないと思います。生成AIは同じ入力に対して同じ結果を確実に返すのは苦手ですし、そこは何かしらのツールが必要です。論物変換をきちんとこなせるデータベース系のツールはまだまだ少ないなと思うし、その手のツールは今後も作っていきたいなと思っています。
物理モデルが作られると概念モデルがメンテされなくて放置される問題とかそういうのをいつか改善できないかな、と思ったりしています。