春の入門祭り2026の9日目の記事です。
はじめに
製造エネルギー事業部の辻です。ここ数年は PostgreSQL を中心に開発していましたが、最近 SQL Server(Azure SQL Database)を利用する機会がありました。
細かいところで、いくつか PostgreSQL と SQL Server で挙動が異なる点がありました。本記事では実運用を見据えた開発で役に立ちそうな少しディープなTipsをまとめました。
1. 照合順序は後から直せない
SQL Server では、並び順・比較ルール・非 Unicode のコードページが照合順序に含まれます1。たとえば Japanese_CI_AS_KS_WS のように、名前そのものが比較の挙動を表します。
CI/CS: 大文字小文字を区別しない/するAI/AS: 濁点・半濁点を区別しない/するKS: ひらがな/カタカナを区別するWS: 全角/半角を区別する
SQL Serverにおける照合順序は、一度運用を始めてしまうと実質的に後から変更できず、変更時はデータベースの再作成になると考えておくべきです。これは、PostgreSQL の lc_collate や lc_ctype の変更に多大なコストがかかるのと同じです。どちらのDBであっても、照合順序は最初の設計段階で完全に確定させるべき項目です。
2. varchar/nvarchar の違いを意識し、適切に使い分ける
PostgreSQL では文字列型を UTF-8 前提で扱えるため、文字コードを意識する場面は多くありません。SQL Server では varchar(非 Unicode 系)と nvarchar(Unicode, UTF-16)の2種類があり、これらを区別して扱うよう意識する必要があります。
特に、アプリから接続する際のドライバ設定に気をつける必要があります。Java から Microsoft JDBC Driver for SQL Server を使う場合、sendStringParametersAsUnicode=true(デフォルト)2により、パラメータが nvarchar として送られます。この状態でテーブル列が varchar だと、クエリごとに型変換が発生し、インデックスが効きにくくなります。プロジェクト初期に文字列型を統一すること(日本語を扱うなら原則 nvarchar など)、ドライバ設定と DB 定義をセットで設計レビューすることを考慮しておくことが重要です。
なお、nvarchar は UTF-16 でデータを保持するため、基本的には1文字あたり2バイトを消費します。varchar と比べてデータ容量やインデックスのサイズが大きくなるというトレードオフがある点には留意が必要です。
3. varchar(n) の n は文字数ではなくバイト数である
PostgreSQL における varchar(n) の n は「文字数」を意味し、全角・半角を問わず n 文字格納できます。
一方、SQL Server の varchar(n) における n はバイト数です3。そのため SQL Server の varchar(10) には 10 バイト分しか格納できず、Shift_JIS 環境であれば全角 5 文字、SQL Server 2019 以降で利用できる UTF-8 照合順序環境であれば全角 3 文字で上限に達します。なお、同じ SQL Server でも nvarchar(n) の n は文字数(文字列長)ベースとなります。nvarchar(10) と定義した場合は、全角・半角を問わず最大 10 文字まで格納できます。
PostgreSQL の感覚で varchar を用いてテーブル設計すると、予期せぬ文字数超過によるエラーを招きやすくなります。日本語を扱う場合は、前述したとおり文字数ベースで直感的に扱える nvarchar を原則として利用するのが望ましいです。
4. search_path がない
PostgreSQL の search_path は複数のスキーマを順番に探索する仕組みです。たとえば myapp, public のように設定しておけば、スキーマ名を省略したときにその順番でスキーマが解決されます。
一方、SQL Server にはこれに相当する複数スキーマ探索の仕組みはありません。代わりにあるのは、ユーザーごとに 1 つだけ設定されるデフォルトスキーマです。スキーマ名を省略した場合は、まずそのデフォルトスキーマが参照され、見つからなければSQL Server のデフォルトスキーマである dbo が参照されます。
SQL Server の dbo は PostgreSQL の public に相当します。原則として public と同様に、ユーザーが業務用オブジェクトを dbo に直接作成することは避け、アプリケーション用のスキーマを別途作成してそこに配置するのが望ましいです。
複数のスキーマを扱う場合は、スキーマをまたいだ参照が増えるほど管理が煩雑になるため、スキーマ間の依存関係を最小化する設計を意識することが重要です。スキーマをまたいだ参照が必要な場合は、シノニム(CREATE SYNONYM)を使ってアプリ側の SQL からスキーマを意識させない構成にする方法はよくあるナレッジです。
5. パーティションは子テーブルではない
PostgreSQL のパーティションは子テーブルとして独立しており、子テーブル名を直接指定してクエリ実行もできます。一方、SQL Server のパーティションはあくまでテーブル内部の分割であり、外からは 1 つのテーブルとしか見えません。パーティションを個別に参照したい場合は $PARTITION 関数4を使う必要があり、子テーブルを直接クエリする感覚では扱えません。
6. 文字列比較で値の末尾空白が無視される
SQL Server(T-SQL)の = 比較では末尾空白が無視されるため、'abc' = 'abc ' が真になります5。一方 PostgreSQL では別文字列として扱われます。SQL Serverの仕様によるものですが、初見では驚きました。また、ややこしいのは、= では末尾空白が無視される一方、LIKE では末尾空白が区別される点です。
外部取り込みデータやユーザー入力データの末尾に空白が含まれる場合の挙動に注意が必要です。
7. ロック挙動が PostgreSQL と異なる
SQL Server の悲観ロックは PostgreSQL よりもロックされる範囲が広くなりやすいため注意が必要です。
PostgreSQL の SELECT ... FOR UPDATE は、最終的に条件に一致した行だけをロックします。対して SQL Server で WITH (UPDLOCK) を用いた場合、条件に合う行をスキャンする途中で読み込んだ行にもロックが及ぶことがあります6。そのため、PostgreSQL と同じ感覚で使うと、更新対象ではない行までブロックしてしまい、システム全体の並行性を下げるリスクがあります。
Azure SQL Database のデフォルト分離レベル (RCSI)
Azure SQL Database では、デフォルトで READ_COMMITTED_SNAPSHOT (RCSI) が有効になっています7。これは PostgreSQL の MVCC と同様に読込が書込をブロックしない挙動です。Azure SQL Database ではこの設定により並行性が確保されています。ただし、明示的に WITH (UPDLOCK) を使用して悲観的ロックを行う場合は、上述のスキャン範囲によるロックの特性に留意する必要があります。
8. ロックエスカレーションで突然テーブル全体が詰まる
SQL Server には PostgreSQL にない概念として「ロックエスカレーション8」があります。SQL Server では、行単位のロックを管理するためにメモリを消費します。1 つのトランザクションで大量の行ロックを取得すると、メモリ効率を保つためにロックを行単位からテーブル単位に自動的に昇格させる仕組みがあり、これがロックエスカレーションです。デフォルトの閾値は約 5,000 行で、これを超えるとテーブル全体がロックされます。
テーブルロックが取得されると、そのテーブルへのすべての読み書きがブロックされるため、バッチ処理中に他のクエリが一切通らなくなる、という事象が起きます。そのため、大量の更新処理を行う場合は、エスカレーションの閾値を超えないよう小さなバッチに分割するなどの工夫が必要です。またロックエスカレーションそのものを無効化したい場合は、テーブル単位で LOCK_ESCALATION オプションを DISABLE に設定する方法があります。
9. WITH 句はマテリアライズされず、複数回参照すると都度計算される
PostgreSQL では、WITH 句を定義してメインクエリ内で同じ CTE を複数回参照した場合、デフォルトではマテリアライズされるため 1 回しか計算されません9。そのため、重い処理を WITH 句に切り出して再利用するテクニックが有効な場面があります。
一方 SQL Server における WITH 句はインラインビューとして扱われます。結果セットは物理的に保持されないため、メインクエリ内で複数回参照すると、その回数分だけ元テーブルへのスキャンや再計算が行われます10。
PostgreSQL の感覚で重い処理を 1 回で済ませる目的で WITH 句を多用すると、SQL Server ではかえって遅くなることがあります。複数回参照する重い処理がある場合は、WITH 句ではなく一時テーブル(#temp テーブル)に結果を格納するなどの代替アプローチを検討するのが安全です。
10. スロークエリの実行計画をクエリストアで確認できる
PostgreSQL では EXPLAIN ANALYZE で任意のクエリの実行計画を確認できますが、スロークエリが発生したクエリの実行計画を確認したいことがよくあります。スロークエリの実行計画をログに残す場合は auto_explain.log_min_duration を設定し、閾値を超えたクエリの実行計画を PostgreSQL のログに出力する運用が一般的です。
Azure SQL Database では、クエリストア(Query Store)に実行計画が自動的に蓄積されます11。Azure SQL Database でも診断設定(Azure Monitor / Log Analytics)や拡張イベントを使えばログ出力は可能ですが、日常的な調査ではクエリストア起点のほうが扱いやすいです。Azure SQL Database ではクエリストアがデフォルトで有効となっています。クエリストアは非常に便利です12。
たとえば、以下のようにして平均 CPU 時間の高いクエリをクエリストアから取得できます。
SELECT TOP 10 |
補足ですが、各ビューの役割は以下の通りです。
| ビュー | 内容 |
|---|---|
sys.query_store_runtime_stats |
クエリごとの実行統計(CPU時間・実行回数・経過時間など) |
sys.query_store_plan |
クエリに紐づく実行計画(XML形式) |
sys.query_store_query |
クエリの識別情報(クエリIDとクエリテキストIDの対応) |
sys.query_store_query_text |
クエリの SQL テキスト本文 |
また SQL Server Management Studio (SSMS) のGUIツールを使用すると、グラフで直感的に遅いクエリや実行計画の推移を確認できるため、システムカタログへのクエリとあわせて活用するのがおすすめです。
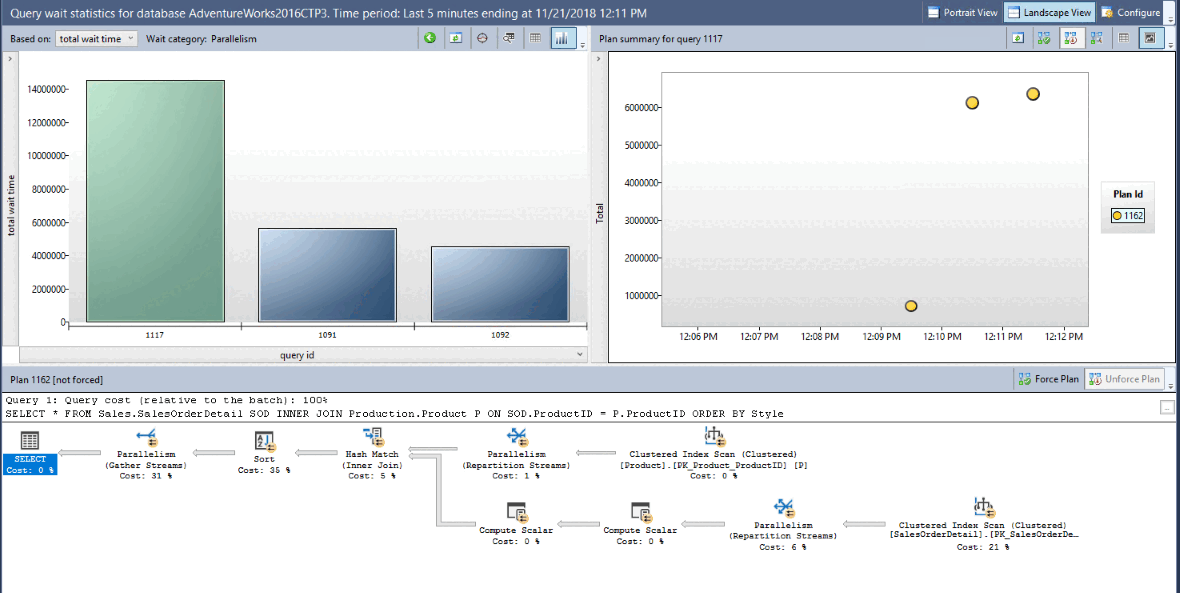
出典:クエリ ストアを使用したパフォーマンスの監視 より引用
まとめ
PostgreSQL ユーザーが SQL Server へ入門した際に、事前に知っておくと嬉しい設計開発 Tips を紹介しました。基本的な考え方は共通する部分もありますが、ロック挙動の思想の違いや、後から変更が難しい照合順序などの初期設計には注意が必要だと感じています。クエリストアなどの強力な機能も活かしつつ、これから SQL Server(Azure SQL Database) 環境での開発に臨む方の参考になれば嬉しいです。
- 1.https://learn.microsoft.com/ja-jp/sql/relational-databases/collations/collation-and-unicode-support ↩
- 2.https://learn.microsoft.com/ja-jp/sql/connect/jdbc/reference/setsendstringparametersasunicode-method-sqlserverdatasource ↩
- 3.https://learn.microsoft.com/ja-jp/sql/t-sql/data-types/char-and-varchar-transact-sql?view=sql-server-ver17 ↩
- 4.https://learn.microsoft.com/ja-jp/sql/t-sql/functions/partition-transact-sql ↩
- 5.https://learn.microsoft.com/ja-jp/sql/t-sql/language-elements/string-comparison-assignment ↩
- 6.https://learn.microsoft.com/ja-jp/sql/relational-databases/sql-server-transaction-locking-and-row-versioning-guide?view=sql-server-ver17 ↩
- 7.https://learn.microsoft.com/ja-jp/sql/t-sql/statements/set-transaction-isolation-level-transact-sql?view=sql-server-ver17 ↩
- 8.https://learn.microsoft.com/ja-jp/troubleshoot/sql/database-engine/performance/resolve-blocking-problems-caused-lock-escalation ↩
- 9.https://www.postgresql.org/docs/current/queries-with.html ↩
- 10.https://learn.microsoft.com/ja-jp/sql/t-sql/queries/with-common-table-expression-transact-sql?view=sql-server-ver17 ↩
- 11.https://learn.microsoft.com/ja-jp/sql/relational-databases/performance/monitoring-performance-by-using-the-query-store?view=sql-server-ver17 ↩
- 12.なお、PostgreSQL でもサードパーティ製の拡張機能(pg_store_plans など)を利用することで、システムカタログから実行計画を確認できます。 ↩