はじめに
ランニングにハマって、Garmin デバイスを使って走っている。走り終わったあと、Garmin Connect のアプリを開いてデータを眺めるのが楽しい。
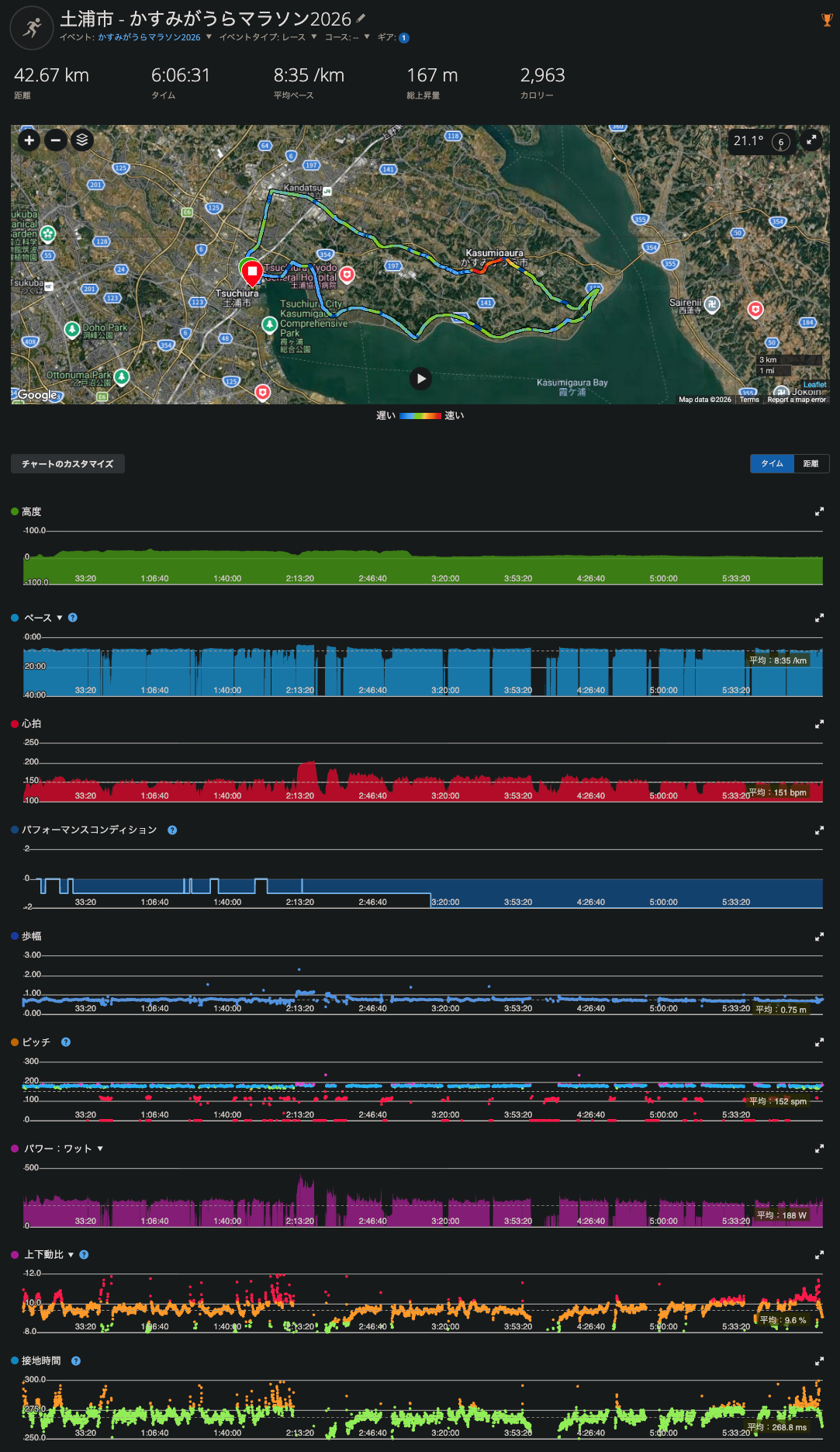
ただ、毎日眺めているうちに、どこか使い切れていない感覚が残る。Garminは膨大な数字を出してくれるのに、「結局どこが悪かったのか」には踏み込んでくれない。
直近の土浦かすみがうらマラソンがまさにそれだった。前半をゆっくり入りすぎて17km関門をギリギリ通過、焦って残り15kmを急激に上げたら腹痛が来て後半は完全に崩れた。ペース配分の問題なのか、スタミナなのか、フォームなのか。感覚ではなんとなくわかるが、数値で裏付けられない。
アプリに表示されるのは「完走おめでとう!」という通知と、距離・タイム・ペースのサマリーくらい。より詳細な分析を見るには Garmin Connect+ というサブスクリプションが必要らしい。内容を見る限り、AIによる分析やアドバイス、トレーニングガイダンスなどは用意されているが、レース単位でどこが問題だったかを掘り下げるようなフィードバックまでは踏み込まない印象だった。
そこで思った。手元にはすでにデータがある。それなら自分で作ったほうが早い。
Garmin が記録しているデータの話
まず、Garmin がどれだけのデータを記録しているかを知ってほしい。これがこのプロジェクトの出発点だ。
Garminはアクティビティを.fitというバイナリ形式で保存している。Garmin Connect の「アクティビティ」画面からダウンロードできるこのファイルに、以下のすべての指標が詰まっている。デバイスでマラソンを走ると、1秒ごとに次の指標が同時に記録される。
1秒毎レコード(record メッセージ)— 本体内蔵
| カテゴリ | FIT フィールド名 | 単位 | 説明 |
|---|---|---|---|
| GPS | position_lat / position_long |
semicircle → 度 | 緯度・経度(独自単位 → × 180/2³¹ で変換) |
| 距離 | distance |
m | 累積走行距離 |
| 速度 | speed / enhanced_speed |
m/s | 瞬間速度(新デバイスは enhanced 優先) |
| 標高 | altitude / enhanced_altitude |
m | GPS + 気圧補正標高 |
| 心拍 | heart_rate |
bpm | 光学心拍センサー値 |
| ケイデンス | cadence |
片足 spm(× 2 が実値) | 歩数/分(片足) |
| ケイデンス小数部 | fractional_cadence |
— | cadence の小数部(精度向上用) |
| 上下動 | vertical_oscillation |
mm | 体の上下動幅 |
| 接地時間 | stance_time |
ms | 足が地面に接触している時間 |
| 垂直比 | vertical_ratio |
% | 上下動 ÷ ストライド長 |
| ストライド長 | step_length |
mm | 1 歩の長さ |
| パワー | power |
W | ランニングパワー(瞬間値) |
| 累積パワー | accumulated_power |
W | 累積パワー合計 |
| 温度 | temperature |
℃ | 気温(デバイス周辺温度) |
| カロリー | calories |
kcal | 累積消費カロリー |
セッション・ラップ集計(session / lap メッセージ)
FIT ファイルにはレース全体のサマリー(session)と、ラップごとの集計(lap)も格納されている。
| カテゴリ | FIT フィールド名 | 単位 | 説明 |
|---|---|---|---|
| 距離・時間 | total_distance |
m | 総走行距離 |
total_elapsed_time |
s | 総経過時間(停止時間込み) | |
total_timer_time |
s | アクティブ計測時間(停止除く) | |
total_moving_time |
s | 実際の移動時間 | |
| 速度 | avg_speed / max_speed |
m/s | 平均・最高速度 |
enhanced_avg_speed / enhanced_max_speed |
m/s | 精度向上版 | |
| 心拍 | avg_heart_rate / max_heart_rate |
bpm | 平均・最高心拍 |
min_heart_rate |
bpm | 最低心拍 | |
time_in_hr_zone[0–4] |
s | ゾーン 1〜5 の滞在秒数(配列) | |
| ケイデンス | avg_running_cadence / max_running_cadence |
片足 spm | 平均・最高ケイデンス |
| フォーム | avg_vertical_oscillation |
mm | 平均上下動 |
avg_stance_time |
ms | 平均接地時間 | |
avg_stance_time_balance |
% | 平均接地バランス(HRM 接続時) | |
avg_vertical_ratio |
% | 平均垂直比 | |
avg_step_length |
mm | 平均ストライド長 | |
total_strides |
回 | 総ストライド数 | |
| パワー | avg_power / max_power |
W | 平均・最高パワー |
normalized_power |
W | 正規化パワー(NP) | |
time_in_power_zone |
s | パワーゾーン別滞在時間(配列) | |
| カロリー | total_calories |
kcal | 総消費カロリー |
total_fat_calories |
kcal | 脂肪由来カロリー | |
| 標高 | total_ascent / total_descent |
m | 累積獲得・下降標高 |
avg_altitude / max_altitude / min_altitude |
m | 平均・最高・最低標高 | |
| トレーニング効果 | total_training_effect |
1–5 | 有酸素トレーニング効果 |
total_anaerobic_training_effect |
1–5 | 無酸素トレーニング効果 | |
training_load_peak |
— | トレーニング負荷スコア | |
| 気温 | avg_temperature / max_temperature |
℃ | 平均・最高気温 |
| メタ | sport / sub_sport |
— | 種目(running / generic 等) |
start_time |
— | アクティビティ開始時刻 |
フルマラソンを走ると、1秒1行 × 15指標以上のタイムシリーズが生成される。4時間台なら約1万5千行、6〜7時間なら約2万5千行以上。数値の総量は軽く30万件を超える。さらにラップ集計・セッションサマリーが加わる。走者の体の状態を1秒単位で切り取った、まさにデータの宝箱だ。
そして、それらを統計したものが Garmin Connect で見られる。以下は同じレースの統計画面だ。
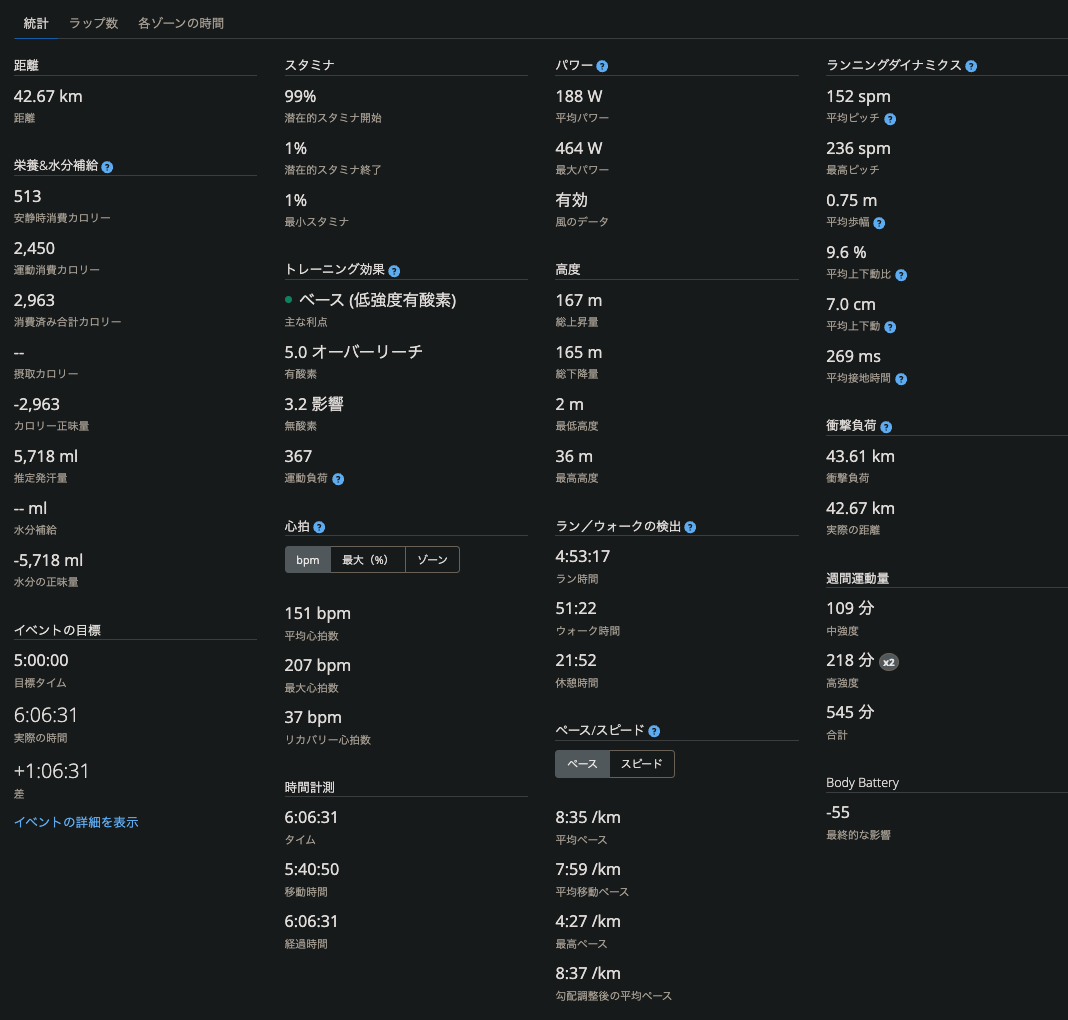
一般的な指標に加えて、ランニングダイナミクスのセクションには、ケイデンス・上下動・接地時間といったフォーム指標もある。
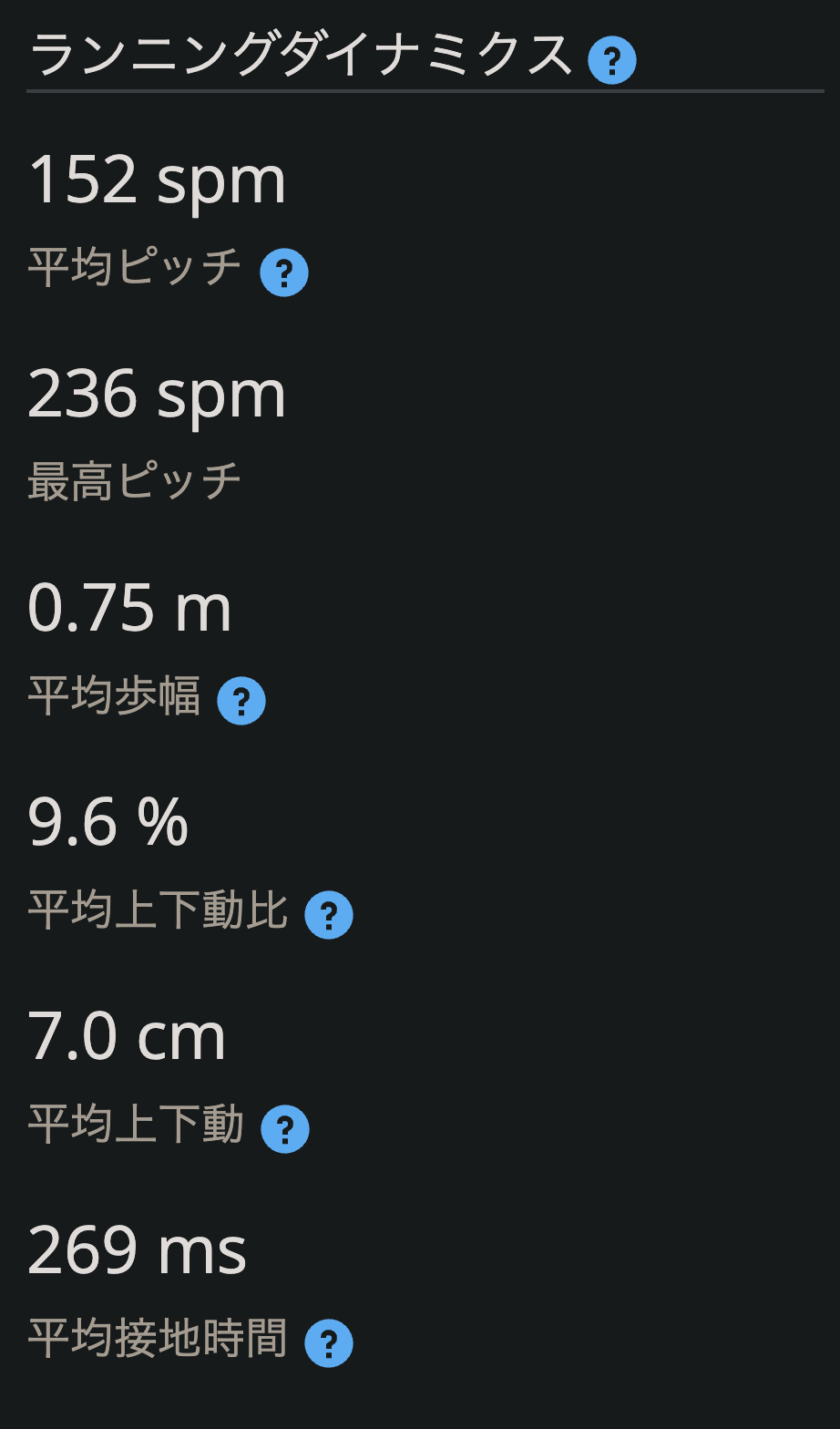
特に面白いのがこの「フォーム」系の指標だ。
- ケイデンス:1 分間に何歩踏んでいるか。一般的に 170〜180 歩/分
が効率的とされている - 上下動:体が上下に動く幅。前に進むために使えるエネルギーが、上下動に無駄遣いさ
れていないかがわかる - 垂直比:「前進方向のストライド長に対して上下動がどれだけあるか」の比率。これが
高いほど非効率 - 接地時間:足が地面についている時間。短いほどバネのような反発力が使えている
- ランニングパワー:自転車でいうパワーメーターと同じ概念。出力の安定性や疲労によ
る低下が数値でわかる
ただ、それを見ても「良いのか悪いのか」「どう直せばいいのか」まではわからない。それがこのプロジェクトを作った動機だ。
作ったものとできること
Pythonで.fitを読み込み、AIで分析し、HTMLレポートとして出力するCLIツールにした。Garmin から入手できる .fit ファイルを渡すと、ブラウザで見られる HTML レポートが生成される。
使い方はシンプル
python3 cli.py analyze-race \ |
コマンド一つでレースデータを渡すと、ブラウザで見られるレポートが生成される。
レポートの中身
サマリーバー
ページ上部に、レース名とともに全体の数字がずらっと並ぶ。右上にはスプリット判定バッジ(ポジティブ/ネガティブ/イーブン)が自動で付く。
距離・タイム・全体ペース・平均心拍・最大心拍・平均パワー・正規化パワー・獲得標高・消費カロリーが一覧できる。
Plotly によるインタラクティブなグラフ群
以下のグラフが Plotly で生成される。ブラウザ上でホバーすると詳細な数値が表示され、ズームや範囲選択もできる。
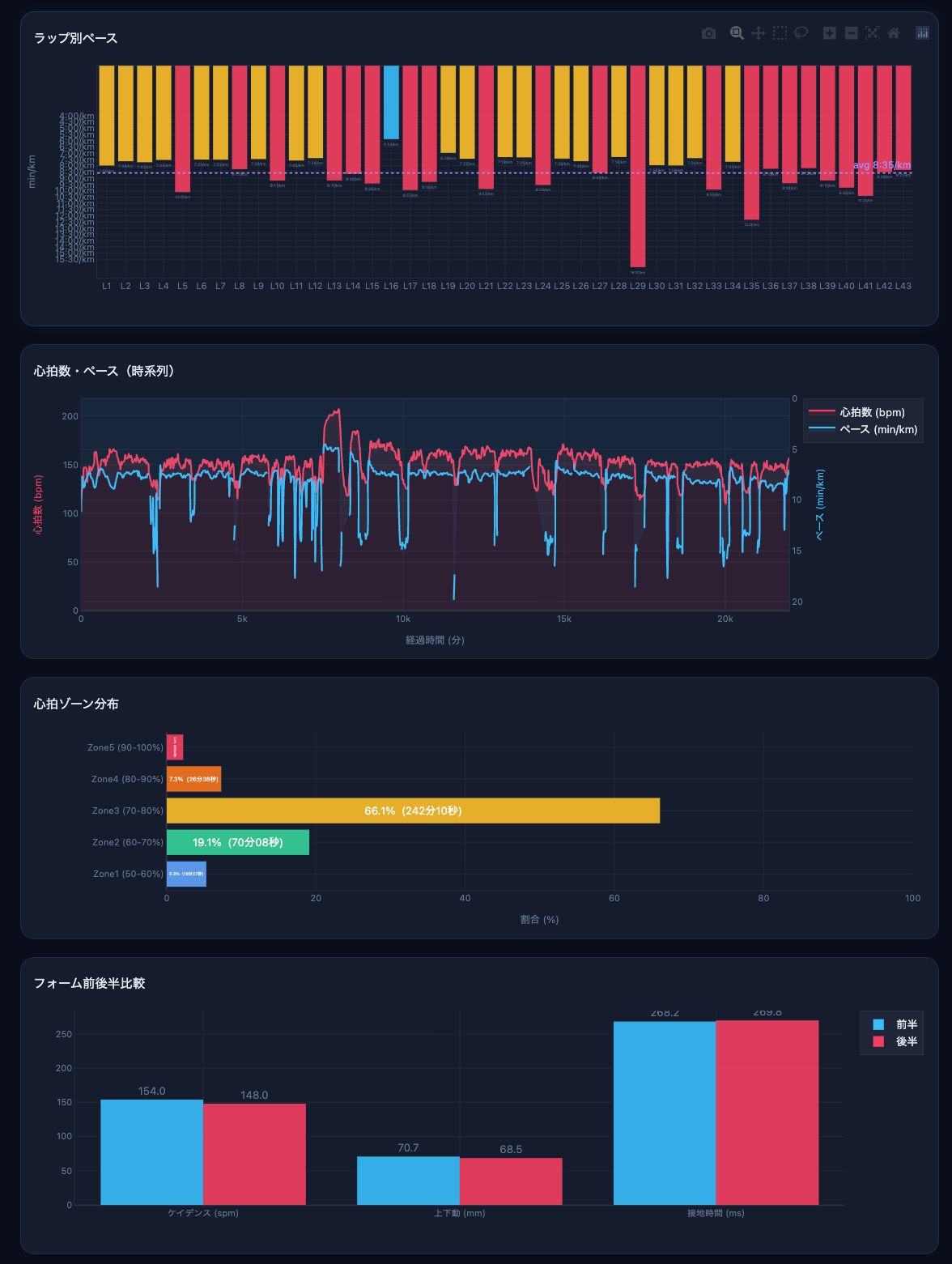
グラフ(平均ラインと色分け付き)
- 心拍数・ペース時系列チャート(2 軸で同時表示)
- 心拍ゾーン分布 横棒グラフ(Zone1〜5の時間・割合)
- フォーム前後半比較グラフ(ケイデンス・上下動・接地時間の変化)
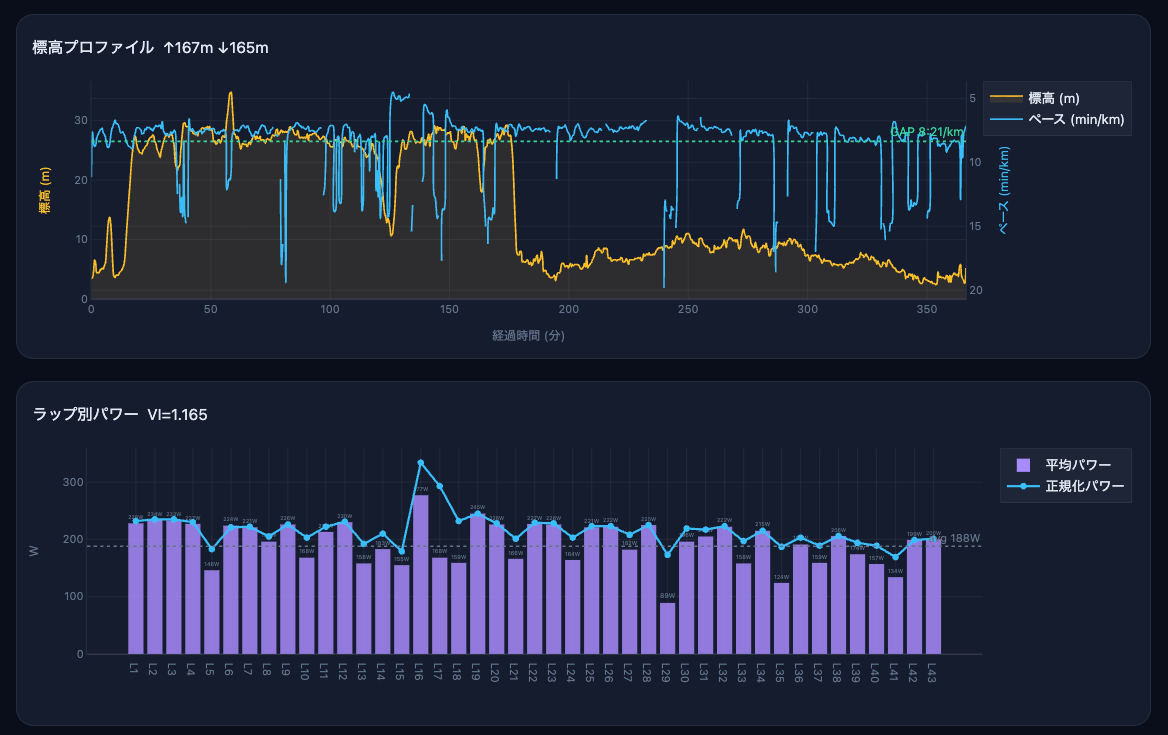
- 標高プロファイル(GAP オーバーレイ付き)
- ラップ別パワーグラフ(平均パワーと正規化パワーの比較)
AI コーチングレポート(実例)
ほしかったのはグラフではなく、これだ。
Claude が生成した日本語のコーチングレポートが表示される。以下が実際のレポートの全文だ。
1. レース総評
フルマラソン完走:42.672 km / 6時間06分31秒(ネットタイム) / 平均ペース 8:35/km
まず、フルマラソンを最後まで走り切ったことを評価します。6時間台での完走は、42.195kmという距離に対して身体が最後まで「動き続けた」ことの証明です。
しかしデータは、心肺系には余裕があったにもかかわらず、脚の筋持久力が先に限界を迎えたことを明確に示しています。心拍ドリフトはわずか-3.1 bpmと心肺系は安定していた一方、ペースは前半8:13/kmから後半8:56/kmへ+43秒/km(8.7%)失速し、パワー出力も30〜40W低下しました。
今回のレースを一言で:「心肺に余力を残して脚が止まったレース」
2. ペース戦略の分析
スプリット評価
| 平均ペース | 平均HR | 平均パワー(推定) | |
|---|---|---|---|
| 前半(1–21km) | 8:13/km | 152.8 bpm | ~220W台 |
| 後半(22–42km) | 8:56/km | 149.7 bpm | ~170–190W台 |
| 差 | +43秒/km | -3.1 bpm | -30〜40W |
ポジティブスプリット(後半失速型) です。後半の心拍が下がっているのにペースも下がっている点が重要で、これは「心肺が追い込めなくなった」のではなく「脚が動かなくなった」ことを意味します。
ペース変動の深刻さ
ペース変動係数(CV)28.01% — これはマラソンとして極めて高い数値です。理想は5%以下、10%でも「不安定」と評価されるレベルに対し、約6倍です。
具体的なラップ推移を見る。
- 走行区間: Lap 2(7:39)、Lap 4(7:32)、Lap 9(7:28)、Lap 12(7:24)→ 7分半前後
- 歩行/停止区間: Lap 5(10:07)、Lap 10(9:11)、Lap 29(16:07)、Lap 35(12:20)
2〜3kmごとに9分/km以上のラップが出現しており、非計画的なRun-Walkのパターンです。計画的なジェフ・ギャロウェイ方式であれば均等間隔になるはずですが、疲労に応じて歩行が入っている形です。
Lap 16の異常サージ — レースのターニングポイント
Lap 16: 5:53/km(HR 176, パワー277W) は、直前のLap 15(9:26/km)から突然3分30秒以上の急加速です。下り坂か折り返し地点での興奮によるものと推測されますが、VO2max強度のスパイクが筋グリコーゲンの急速な枯渇を招き、直後のLap 17で9:57/kmに急減速。このサージ以降、ペースの安定性がさらに悪化しています。
GAP(グレード調整ペース)
GAP 8:21/km(実ペース8:35/km、差-14秒/km)。累積標高167mのコースに対して大きなペースロスなく対応できており、コース起伏への適応自体は問題ありません。
3. 心拍数とエネルギーシステムの分析
ゾーン分布
| ゾーン | 時間 | 割合 | 意味 |
|---|---|---|---|
| Z1(50–60%: 104–124 bpm) | 19分27秒 | 5.3% | 回復・歩行区間 |
| Z2(60–70%: 124–145 bpm) | 1時間10分 | 19.1% | 軽い有酸素 |
| Z3(70–80%: 145–166 bpm) | 4時間02分 | 66.1% | 有酸素の中核帯 |
| Z4(80–90%: 166–186 bpm) | 26分38秒 | 7.3% | 閾値付近 |
| Z5(90–100%: 186–207 bpm) | 8分04秒 | 2.2% | 無酸素域 |
心拍ベースでは理想的な分布です。Z3に66%、Z2+Z3で85%はマラソンとして適切な有酸素強度帯です。心肺系のコントロールは良好と評価できます。
心拍ドリフトと疲労パターン
- 心拍ドリフト: -3.1 bpm(前半152.8→後半149.7) — 通常、マラソン後半は脱水や体温上昇で心拍が上がる(カーディアックドリフト)のが一般的ですが、本レースでは逆に低下しています。これは後半にペースが落ちて(歩行区間が増えて)心拍が上がりきらなかったことを示します。
- ペース-心拍相関: r = -0.461(逆相関) — 通常はペースが速い=心拍が高いで正の相関になるはずが、負の相関です。これは「歩行で心拍が下がりきる前に走行を再開→高い心拍のまま走り始める」というRun-Walkの非効率なパターンを反映しています。歩行区間での回復が不十分なまま走行を再開することで、心拍の制御が乱れています。
重要な示唆
心拍Z3に66%滞在できる有酸素ベースがあるにもかかわらず完走タイムが6時間を超えている事実は、制限因子が心肺系ではなく筋骨格系にあることを強く示唆しています。
4. ランニングフォームの評価
フォームスコア: 65点(「改善の余地あり」)
| 指標 | 値 | 評価 | 前半→後半 |
|---|---|---|---|
| ケイデンス | 150 spm | 大幅に不足(-20点) | 154→148 spm |
| 上下動 | 69.7 mm | 良好 | 70.7→68.5 mm |
| 垂直比 | 9.55% | 高い(-15点) | 9.47→9.66% |
| 接地時間 | 268.8 ms | 許容範囲 | 268.2→269.8 ms |
| ストライド長 | 74.6 cm | 極端に短い | — |
ケイデンス(150 spm)— 最大の改善ポイント
推奨値170〜180 spmに対して20 spm以上不足しています。後半はさらに148 spmまで低下。低ケイデンスは1歩あたりの衝撃荷重を増大させ、筋疲労を加速させます。
垂直比(9.55%)— エネルギー漏れの指標
推奨値6〜8%に対して高く、推進(前方移動)に対して上下動のコストが大きいことを意味します。上下動の絶対値(69.7mm)は良好なのに垂直比が高いのは、ストライドが極端に短い(74.6cm)ことが原因です。つまり「1歩で前に進む距離が短いのに、上下には同じだけ跳ねている」状態です。
ストライド長(74.6 cm)
一般的なマラソンランナーの100〜120cmと比較して極端に短い値です。低ケイデンス × 短ストライド がペース8:35/kmの直接的な算術的原因です(150歩/分 × 0.746m = 111.9m/分 ≒ 8:56/km相当)。
フォームの後半変化
後半の垂直比9.47%→9.66%への悪化は、筋疲労により骨盤の安定性が低下し、推進効率がさらに落ちたことを示しています。ケイデンスも6 spm低下しており、シャッフル(すり足)気味の走りへ移行した可能性があります。
5. ランニングパワーの分析
基本データ
| 指標 | 値 |
|---|---|
| 平均パワー | 188W |
| ノーマライズドパワー(NP) | 219W |
| 最大パワー | 464W |
| 変動指数(VI = NP/Avg) | 1.165 |
| パワー/心拍デカップリング | -7.2% |
| 総消費カロリー | 2,963 kcal(69.4 kcal/km) |
変動指数(VI)1.165 — ペーシングの不安定さを数値化
理想は1.05以下。1.165は「同じ平均パワーを一定出力で走った場合と比べ、16.5%多くの代謝コストがかかった」ことを意味します。ラップ別で見る。
- Lap 16: avg 277W / NP 334W(スパイク)
- Lap 17: avg 168W / NP 293W(スパイク直後の急変動)
- Lap 29: avg 89W / NP 173W(長時間歩行/停止)
このような急激なパワー変動の繰り返しが、エネルギーコストを大幅に押し上げています。
パワー/心拍デカップリング -7.2%
後半で同じ心拍数に対するパワー出力が7.2%低下。これは筋疲労による効率劣化の明確な指標です。5%以内が良好とされる中で、7.2%は有酸素効率が後半で明らかに悪化したことを示します。
パワーゾーン設定について
Z5(VO2max以上)に83.2%という分布は現実的ではありません。ウォッチのFTP/CP設定がデフォルト値のままか、実力に対して低すぎる可能性が高いです。パワーの絶対値よりもラップ間の相対変化(前半220W台→後半170W台への低下)を重視して解釈すべきです。
6. 次のレースへの具体的アドバイス
アドバイス1: ケイデンスを段階的に引き上げる
目標: 現在150 spm → まず160 spm、最終的に170 spm
- 週2回、メトロノームアプリ(160 BPM設定)に合わせて20〜30分のイージーランを行う
- 最初の4週間は160 spmに慣れることに集中し、その後4週間で165 spm、さらに170 spmへ
- ケイデンスを上げる際、ストライドを意識的に伸ばそうとしないこと。ケイデンスが上がれば自然にペースは速くなる
- 練習メニュー: 100m流し(ストライド)× 6本を週2回。腕振りを小さく速くすることで脚の回転を誘導する
アドバイス2: 筋持久力トレーニングを最優先で導入する
目標: 30km以降のペース低下を現在の+43秒/kmから+20秒/km以内に
- 心肺系は十分なベースがあるため(Z3に66%滞在)、ボトルネックは脚の筋持久力
- 週1回のロングラン: 現在の走力では25km〜30kmを8:30〜9:00/kmペースで。歩かずに走り続けることを最優先
- 週1回のテンポ走: 7:00〜7:30/kmで30〜40分の持続走。現在の走行区間ペース(7:30前後)を「楽に」感じられるようにする
- 補強運動: スクワット(自重)30回×3セット、カーフレイズ20回×3セット、ランジウォーク20歩×3セットを週3回
アドバイス3: レース中の歩行戦略を「計画的」に変える
目標: ペースCV 28% → 15%以下(計画的Run-Walkなら10%前後が可能)
- 現状の非計画的な歩行(疲れたら歩く)を、計画的なRun-Walk方式に切り替える
- 具体的プラン: 「4分走って1分歩く」を序盤から一貫して実行。歩行区間でも完全に止まらず、6:30/km程度の早歩きを維持
- 走行区間のペースを7:30/km、歩行区間を10:00/kmとすると、加重平均で約8:00/kmとなり、ネガティブスプリットが狙える
- 練習で試す: 月1回の20km走で必ずRun-Walk方式を試し、最適な走行:歩行比率を見つける
アドバイス4: Lap 16型のサージを絶対に出さない
目標: レース中の最速ラップと最遅ラップ(歩行除く)の差を2分/km以内に
- Lap 16の5:53/km(HR 176, 277W)は、直前ラップから3分30秒/kmの急加速。このVO2max強度のスパイクが筋グリコーゲンの急速な枯渇を招き、以降のペース崩壊を加速させた可能性が高い
- レースルール: 「どんなに下りでも、どんなに気持ちよくても、走行区間のペースは7:00/km以上にしない」と決める
- 練習方法: ペース走の際にGPSウォッチのペースアラート機能を使い、設定ペース±30秒/kmを超えたら振動で通知するよう設定
アドバイス5: 垂直比を改善するドリルを導入する
目標: 垂直比9.55% → 8.5%以下
- 垂直比が高い原因は「ストライドが短いのに上下動は同じ」こと。骨盤の前傾を意識し、重心を前方に送る感覚を養う
- Aスキップ: 20m × 6本を週2回。膝を高く引き上げて前方への推進を意識
- 壁ドリル: 壁に手をつき、片脚ずつ膝を引き上げる動作を30回×左右。股関節の屈曲力を鍛える
- 緩い下り坂(2〜3%勾配)での流し: 100m × 4本。重力を利用して前方への推進感覚を身体に覚えさせる
アドバイス6: パワーメーターの校正とFTP設定を行う
目標: パワーゾーンが実力を正しく反映する状態にする
- 現在のパワーゾーン設定ではZ5に83%となり、トレーニング指標として機能していない
- FTPテスト: 30分間の全力走(キロ7分を維持できるペース)を行い、その平均パワーの95%をFTPとして設定
- おそらくFTP 200〜210W前後になると推測。これを基準にゾーンを再設定すれば、Z2〜Z3中心の分布になるはず
- 校正後、毎回のランでNP/VI をチェックする習慣をつけ、VI 1.05以下を目指す
アドバイス7: レース当日の補給戦略を見直す
目標: 総消費2,963 kcalに対して、レース中に600〜800 kcal以上を補給
- 6時間超のレースでは筋グリコーゲン枯渇が不可避。Lap 29(16:07/km)やLap 35(12:20/km)の大減速はエネルギー切れの可能性
- 具体策: 30分ごとにジェル1本(約100 kcal)を摂取。6時間で12本、計1,200 kcal
- エイドステーションでの長時間停止を避け、歩きながら補給する練習をロングランで行う
まとめ: あなたの最大の強みは心肺系の安定性(Z3に66%滞在、ドリフト-3.1 bpm)です。心肺はすでにサブ5.5を狙えるベースがあります。課題は明確で、ケイデンス改善(150→170 spm)と筋持久力の強化の2点に集中すれば、次回のフルマラソンで大幅なタイム短縮が期待できます。まずは3ヶ月間、ケイデンスドリルと筋力補強を継続してください。次のレースでは5時間30分以内を現実的な目標として設定できます。
数値を根拠に「なぜ後半失速したのか」「次に何をすべきか」が具体的に出てくる。「次はこの練習をしよう」と思えるのは、暗闇を走る初心者ランナーにとって、 何よりの「羅針盤」 になりそうだ。
ここからは技術的な実装の話をする。
システム構成
FIT ファイル(バイナリ) |
依存ライブラリ: fitparse, pandas, plotly, click
FIT ファイルのパース
Garmin デバイスが保存するデータ形式は .fit はバイナリフォーマットのため、テキストエディタでは読めない。fitparse というライブラリを使えば、これを数行で読み込める。このファイルは Garmin Connect の「アクティビティ」画面から手動でダウンロードできる(エクスポート → オリジナル形式)。
fitparse というライブラリを使えば、これを数行で読み込める。
from fitparse import FitFile |
ただし、Garmin 固有の仕様にいくつかハマりポイントがある。
GPS 座標はセミサークル単位
Garmin は GPS 座標を「度(degrees)」ではなく「セミサークル」という独自単位で保存している。そのまま使うと全く違う座標になってしまう。
# 変換が必要 |
ケイデンスは片足 SPM
Garmin のケイデンスデータは「両足」ではなく「片足」の歩数で記録されている。実際のケイデンスを得るには 2 倍が必要だ。
# セッションデータの場合 |
enhanced_speed と speed の使い分け
新しいデバイスでは speed と enhanced_speed の両方のカラムが存在することがある。精度の高い enhanced_speed を優先して使う必要がある。
speed_col = "enhanced_speed" if "enhanced_speed" in records_df.columns else "speed" |
5 種類の分析ツール
各ツールは RaceData(DataFrameのラッパー)を受け取り、JSON を返す純粋関数として実装している。
1. ペース分析(pace_analyzer.py)
ラップ毎ペース・前後半スプリット判定・ペース変動係数(CV)を計算する。
# ペース変動係数: レースがどれだけ均一に走れたかの指標 |
先ほどの実例レポートでは CV が 28.01% と算出された。理想の 5% 以下どころか 6 倍近い値で、「非常にペースが不安定なレースだった」という事実を数値として示している。
2. 心拍数分析(hr_analyzer.py)
Garmin の 5 ゾーン基準(最大心拍の 50/60/70/80/90/100%)に従ってゾーン分布を算出する。加えて、前後半の平均心拍差(心拍ドリフト)とペースとの相関係数も計算する。
HR_ZONE_BOUNDS = [0.50, 0.60, 0.70, 0.80, 0.90, 1.00] |
3. フォーム分析(form_analyzer.py)
ケイデンス・上下動・接地時間・垂直比を前後半で比較する。さらに、独自の フォームスコア(100 点満点) を算出して「どこをどう改善すべきか」を定量化している。閾値はランニングエコノミー研究で一般的に参照される市民ランナー向けの目安値(ケイデンス 170〜180 spm、垂直比 8% 以下、接地時間 250ms 以下が効率的とされる)をもとに設定した。
score = 100 |
4. 高低差・GAP 分析(elevation_analyzer.py)
コースの起伏を補正した「グレード調整ペース(Grade Adjusted Pace)」を計算する。「実際のペースが遅かったのはコースのせいか、実力のせいか」を分離できる。
5. ランニングパワー分析(power_analyzer.py)
変動指数(Variability Index = 正規化パワー ÷ 平均パワー)とパワー/心拍デカップリングを計算する。VI が 1.05 以上だと、ペースの不均一によるエネルギーコストの増加を意味する。
Claude Code CLI をスクリプトから呼び出す
AIの呼び出しはAPIではなくCLIを使った。
最初の実装では Claude API Python SDK を直接使っていた。
# 最初の実装(APIキー方式) |
しかし問題があった。5 つの分析ツールの出力(合計で数千トークン)をプロンプトに詰め込むため、フルマラソン 1 本を分析するたびに無視できない API 料金が発生する。しかも Claude Code のサブスクには既に加入していた。二重コストだ。
そこで思いついたのが、Claude Code CLI(claude コマンド)を subprocess で呼び出す方式に切り替えることだった。
import subprocess |
ポイントは ANTHROPIC_API_KEY を環境変数から除いて claude CLI を呼ぶこと。こうすると CLI はサブスクリプション経由の認証を使うため、API の従量課金が発生しない。
Claude Code CLIはパイプやスクリプトからの呼び出しを前提に設計されており、公式ドキュメントにも以下のような使用例が掲載されている。
tail -f app.log | claude -p "alert me if you see anomalies" |
subprocessからの呼び出しはこの延長線上にある。
個人利用の範囲であれば、Claude Codeサブスク加入者は追加費用なしで使える。
2 パス AI コーチング設計
最初は 1 回の API 呼び出しで「データ解析 + コーチング文章の生成」をまとめてやらせていた。しかし品質が安定しなかった。データの読み取りに気を取られて文章が散漫になったり、逆に文章を意識しすぎて数値の読み違いが起きたりする。
そこで 2 パスに分離した。
Pass 1: データアナリスト
5 ツールの生 JSON をまとめて渡し、「コーチングレポートを書く前段階として重要な知見を構造化して抽出してください」とだけ指示する。文章生成はしない。
## 出力形式(必ずこの構造で) |
Pass 2: エキスパートコーチ
Pass 1 の出力(構造化された知見)と生データの両方を渡し、「実践的な日本語コーチングレポートを作成してください」と指示する。
pass2_prompt = ( |
この分離によって、Pass 2 のコーチは「既に整理された知見」を受け取った上で文章を書ける。結果として「数値を積極的に引用した、明日から何をすればいいかがわかるレポート」が安定して生成されるようになった。
まとめと今後
ソースコードはGitHubで公開しています。
技術スタックは Python + fitparse + pandas + Plotly + Claude CLI だけ。特別なインフラも不要で、ローカルで完結する。
このツールを作る前と後では、レースの振り返り方が変わった。「なんとなく後半きつかった」が「CV 28%・心拍ドリフト +12bpm・接地時間後半+18ms」という数値に変わり、次の練習で何を優先すべきかが具体的になる。土浦のレースも、ペース急変→腹痛という因果がデータ上ではっきり見えた。
FIT ファイルのパースや Garmin 独自単位の変換、2 パス設計といった地味な実装の積み重ねが、実用レベルのツールを作る上での本質だった。
今後やりたいこと
現状はレース1本ずつの単発分析だが、次のステップとして 複数レースの蓄積・横断分析 を実装したい。レースごとの HTML レポートを SQLite などに集約し、「前回と比べてケイデンスは改善されたか」「ペース CV の推移はどうか」をグラフで追えるようにすることで、単なるレビューツールから成長トラッキングツールへと発展できる。
また現在の AI コーチングは1回のレースデータしか参照できないが、過去レースの傾向を踏まえた「あなたの慢性的な課題はここです」という長期視点のアドバイスも面白そうだ。ランナーの個人データが蓄積されるほど分析の解像度が上がる、という構造はこのツールの本質的な強みになりうる。
同じようにGarminのデータをこねくり回している方や、FITファイルのパースで詰まった経験がある方はコメントで教えてください。あと「こういう分析も欲しい」というアイデアも歓迎です。