コーディングエージェントの様々なツール横断で使えるハーネスといえば、skillsという雰囲気になってきました。AGENTS.mdやMCPもありますが、作りやすさや小回りが効く点、プロジェクトやチーム単位で気軽に改善していける点など、人気になるのはうなづけます。もちろん、MCPが全てにおいて劣っているというわけではないので、必要に応じて使い分けることになると思います。
| 項目 | AGENTS.md / CLAUDE.md | MCP | Skills |
|---|---|---|---|
| 主な役割 | プロジェクト全体の方針・ルール共有 | 外部データや外部システム連携 | 特定タスクのノウハウ・手順共有 |
| 読み込みタイミング | 常時 | 必要時 | 必要時 |
| コンテキスト消費 | 大 | 中〜大 | 小 |
| 配布方法 | Gitリポジトリ | MCPサーバー | Gitリポジトリ |
| 更新反映 | Git更新が必要 | サーバー更新のみ | Git更新が必要 |
| 動的データ対応 | × | ◎ | △ |
| 巨大データ対応 | × | ◎ | × |
| 外部システム操作 | × | ◎ | △(MCPやCLIを呼ぶ手順は書ける) |
| リアルタイム情報取得 | × | ◎ | × |
| 認証・権限制御 | × | ◎ | × |
| オフライン利用 | ◎ | △ | ◎ |
| モデル間移植性 | ◎ | ○ | ○ |
| 作成難易度 | 低 | 高 | 低 |
| メンテナンス負荷 | 中 | 高 | 中 |
| 適した内容 | コーディング規約、設計原則、プロジェクト方針 | DB、社内システム、SaaS、API、ファイルサーバー | レビュー手順、設計テンプレート、運用手順 |
| 長所 | 必ず読まれる | 動的・巨大データを扱える | コンテキスト効率が高い |
| 短所 | 肥大化するとコンテキストを圧迫 | 導入・運用コストが高い | 発見されないと利用されない |
実際、いくつか自分でも作ってみたりもしたのですが、これ実際に効果があるのか定量評価してみたくなったので、スキルのベンチを作ってみました。name/descriptionをもとにした自動起動(暗黙的実行)もスキルにはあります。本当にやりたいタスクに対してスキルが使われているのか、処理時間や消費トークンがどれだけ節約できるのか、というのを確認してみたいですよね?
skillsのドキュメントにも、スキルの評価について書かれたページがあります。これの前のページではClaudeを前提としてシェルスクリプトで-pでプロンプトを実行して説明の評価をする、というのが書いてありますが、おそらくこのページも詳細は書かれていませんが、それを前提としています。
https://agentskills.io/skill-creation/evaluating-skills
今回はCodex-5.5でやってみました。Codexには、CLIやApp以外に、プログラマブルにセッションを作ってプロンプトを入れて結果をもらえるCodex SDKがあります。それを使ってみています。作ってみたベンチは以下のところにpushしています。
https://github.com/shibukawa/codex-skill-bench
実際にデモ的なスキルを作って検証しました。こんな感じで処理時間や消費トークンをまとめてレポートを出すようにしました。
プロンプトの評価との違い
今回はスキルの評価を目的としました。生成AIの文脈だと、プロンプトの評価というのは以前からありました。WWDCでもEvaluations frameworkというのが登場していました。
- WWDC26: Meet the Evaluations framework
生成AIは決定性がないため、以前からあるユニットテストとは同じような評価は難しいです。同じ入力に対して同じ結果を返さない可能性があるからです。またユーザーの入力も多岐にわたる可能性があります。
基本的には機械学習のモデルの評価と同じく、なるべくバリエーションの広い入力として想定されるデータや、失敗データと、それぞれの期待される評価結果を用意してシステムに投入してみるしか方法はありません。Evaluations frameworkは成功の割合などのちょっと自由度のある検証ができたり、検証そのものをLLMに判断させてヒューリスティックな結果の検証ができるようにしています。
スキルの場合には、そのプロンプトレベルの評価と比べて追加でいろいろ行う必要があります。プロンプトであれば、入力のプロンプトと、出力のプロンプトのペアで評価を行えば良いですが、まずはコーディングエージェントはワークスペースを用意する必要があります。そして入力んプロンプトを与えますが、それによってそもそもそのスキルが起動しているかどうか。そして結果がファイルの変更や新規作成であれば、その内容の評価も必要となるため、プロンプトの評価よりも難易度は2段ぐらいあがります。
ついでに、Codexのプランの利用枠内で検証させてみたいな、と思ったのが今回作ってみた理由です。
Codexの起動の仕方による消費の違い
まず作ってみたのはソースコードのヘッダーにライセンスを入れるというシンプルなスキルです。スキルを使わなくてもエージェントがやってくれるような処理です。Copilotではスラッシュ+スキル名、Codexはスラッシュかドル+スキル名で明示的に実行できます。その明示的な処理、あるいは暗黙的実行。事前に一度ロードしておく、しない、のケースで比較しました。あとはスキルをつかわない、というものです。
結果は以下の通りです。暗黙的実行ではスキルは正しく使われているのは確認済みです。

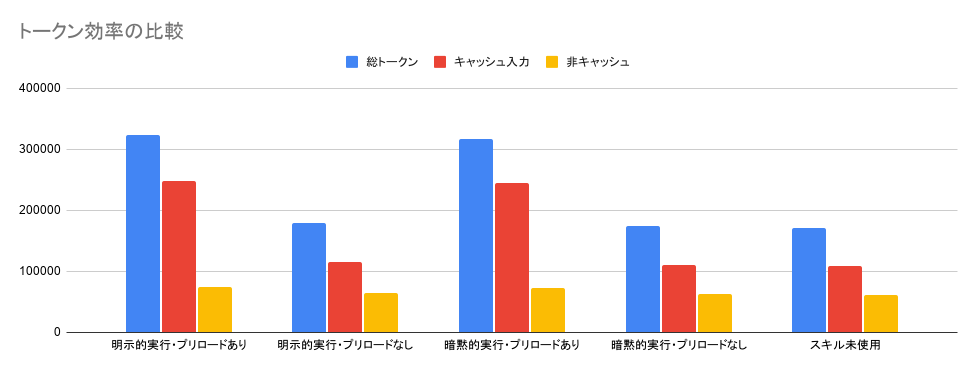
結果としては、暗黙実行でも、明示的な実行でもこのようなシンプルなケースでは処理時間は大きく変動はしませんでした。同一セッション内部で一度ロードしていても処理時間への影響はありませんでした。キャッシュはされません。
一方、トークン実行を見ると、プリロードした分トークン消費は大きいのですが、その分キャッシュされているため、非キャッシュのトークン消費はほぼ変わらずでした。キャッシュと非キャッシュでAPIコストは大きく変わるため、ここはモニタリングすべきポイントですね。OpenAIのAPI価格表、ClaudeのAPIの価格表を見ると、どちらもキャッシュヒットすると1/10の価格になります。非キャッシュトークンをまずはKPIとすれば良さそうです。
シンプルなタスクでは処理時間やトークンは変わらないというか、Codexがかしこすぎてちょっとしたスクリプト程度じゃメリットは出せないってことがわかりました。
複雑なタスクでの違い
データベースなどのデータの集計の集計のスキルを作成して実行してみました。2つのテーブルを見て組織ごとの値の集計、みたいなタスクにしてみました。先程はプリロードは差がなかったので、それはやめて、明示的実行、暗示的実行、スキルなしの3つでやっています。これだとかなりの差が出ていますね。
ちょっと謎なのがこちらのケースだと暗黙的なリクエストでトークン消費が大きい点。これはdescriptionの書き方が悪くて、該当するスキルを探すのに時間がかかったとかでしょうかね。
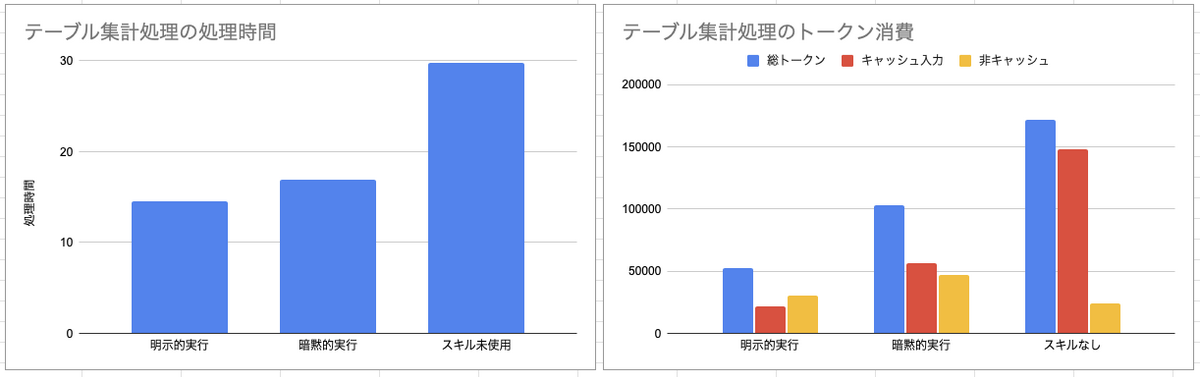
このように、ちょっと複雑なデータ調査系のタスクはあらかじめてスキル化しておくなどするとトークン消費が抑えられて、効率は良くなりそうです。
なお、このテストの前に、1テーブルの集計のタスクのテストをやってみたのですが、それだとスキルの有無では差が出ませんでした。簡単すぎたようです。
もっと詳細な分析の案
今回はスキルのベンチマーク、というアイディアを試す簡易実装なので、業務でやるのであれば、もっと手間暇かけて演る必要があるでしょう。
今回はコストもかかるので、ほぼ一回ずつしか計測はしていませんし、結果の評価は目視でやりました。本来は結果の評価を行い、ランダムゆえのブレがありえるのでリトライして品質の安定度なども見る必要があるでしょう。結果は、structured outputで出力するようなテストケースのプロンプトにしたので簡単に白黒はつけられるようにしていますが、ドキュメントの作成とかであれば、検証自体にもLLMは必要でしょう。
今回は単一のモデル(Codex-5.5)でやっていますが、ここも安価なモデルとかも含めてやって結果を比較する方が良いでしょう。確定論的な結果が出せるスクリプトをきちんと作り込んだ場合は、安価なモデルでもきちんとした結果は得られます。今はスキルごとにモデルを選ぶというのはできませんが、エージェントごとに使えたカスタムプロンプト機能では実現されていたので、将来的にできるようになるんじゃないかと期待しています。
あと、モデルごとの結果というのは一度実行して結果を保存しておくことも大切です。たまに話題になる「エージェントのモデルの劣化」ですが、機械学習同様に、ゴールデンデータセットに対する処理結果を保存しておくことで、本当にどこに原因があったのかが追跡できるようになります。実はスキル側が変わっていたので結果が変わったとかもありえます。
まとめ
今回はとりあえず実証実験ということで、Codex SDKを使って実装してみました。Codexがスキル起動とかをログとして出してくれているため、きちんと作ったスキルが動作し、複雑なタスクではきちんとトークン消費量の削減や時間削減につながっていることは確認できました。また、簡単なタスクではCodexがかしこすぎてスクリプトを書いても効果はない、というのも見えました。やはり計測してみると色々考察できて良いですね。
トークンコストの上昇や定額モデルはもう限界など言われ始めています。より効率の良いエージェントの使い方、というのは仕事としてコーディングをAIでやっていくには重要な指標となるでしょう。おそらく、今後の仕事の見積もりには人月の見積もり以外に、「AIの予想トークン数」も見積もる、みたいな話が出てくるんじゃないかと思っています。そうなると、トークン節約を数字で語れるのが「できるエンジニア」となっていくかと思います。
CopilotやClaudeではまた別の仕組みを作る必要があるかと思いますが、思いつきでやってみた割にはきちんと結果が出たので今回は大成功でした。