うちの会社では、各種クラウドサービスの知見を共有する勉強会を毎週行なっています。弊社ではコンサルティング事業をしていて、次々と多くの案件をこなしているし、各案件の要件も異なるため、自社でもっている知見もバラエティーに富んでいます。既存のサービスではこういう制約があってハマったとか、今回これで作りきったけど、次回クリーンに作り直すならこうしたい、みたいな話が赤裸々に語られる楽しい会です。で、僕はインフラをやることはあまりないのだけど、話を聞くだけでは申し訳ないので、2週間前の会で、最近ハマっているOpenCensusについて紹介しました。
「分散トレースとは」という話がまとまっていて、初学者に「これ読んどいて」と言えるようなページがなかったので社内向けの資料をベースに技術ブログでも公開します。
トレーシングとメトリックス
トレーシングはどの処理がどの順番で行われているか、どのぐらい処理時間がかかっているかをミクロに見ていくことによって、システムの状況を把握しやすくする。
メトリックスは、マクロな統計情報。だいたい平均は100mSで終わってる、80パーセンタイルの処理時間は120mS、95パーセンタイルは400mSみたいな、「なんとなく」を掴む方法。メモリ使用量、CPUなどのシステムの状態を把握し、異常が起きそうかどうか、余裕があるかどうかを把握するために使うもので、SRE本ではかなり強調されているもの。
OpenCensusでは、メトリックスはビューというものをあらかじめ定義する。どういった単位の数字で、どういった感じの値分布になるのか、を定義する。ちょうど、OpenCensusのGoライブラリのデフォルト定義がわかりやすい。
この分布に含まれるリクエスト数がいくつ、みたいなカウント数が集計されるので、数万件のアクセス時にも、収集されるデータ量はあまり大きくならない。トレーシングはどの処理がどの順番に行われたか、どれだけ時間がかかったかを個別に収集するため、ビューといったものはない。アクセス数に比例した分量の詳細なログが出力されるが、データ量削減のために、トレーシングも、間引いて(サンプラーの設定による)収集することがある。
背景
- Googleが社内のサービスの監視のために、Borgmonを作る
- Borgmonはモニタリングのためのツール。システムが正しく動作しているかどうかのモニタリングを行う
- 元Googleの人がBorgmonに触発されてOSSでPrometheusを作る
- Googleが社内のサービスのトレーシングのために、Dapperを作る
- Dapperの論文が2010年ごろに出る
- この論文をもとに、Zipkin(Twitter)、Jaeger(Uber)といったOSSが作成される
- New Relic, Datadog, Treasure Dataなどのサービスがここ10年ぐらいのあいだで生まれた
- モニタリング・分析などのビッグデータ的な文脈
- 統合APIの機運
- いろんなバックエンドサービスが生まれたが、それぞれの専用のSDKをアプリケーションに組み込む必要があった
- OpenTracingというプロジェクトができ、Cloud Native Computing Foundation配下に入る
- Googleが社内のCensusというライブラリの公開版のOpenCensusを作成する
- トレーシングと、モニタリングを両方サポート
- 統合APIの統合
- OpenCensusとOpenTracingの統合が発表される
- この2つがマージして、CNCF配下のOpenTelemetryというものが作られることが発表される(先週)
分散トレーシング
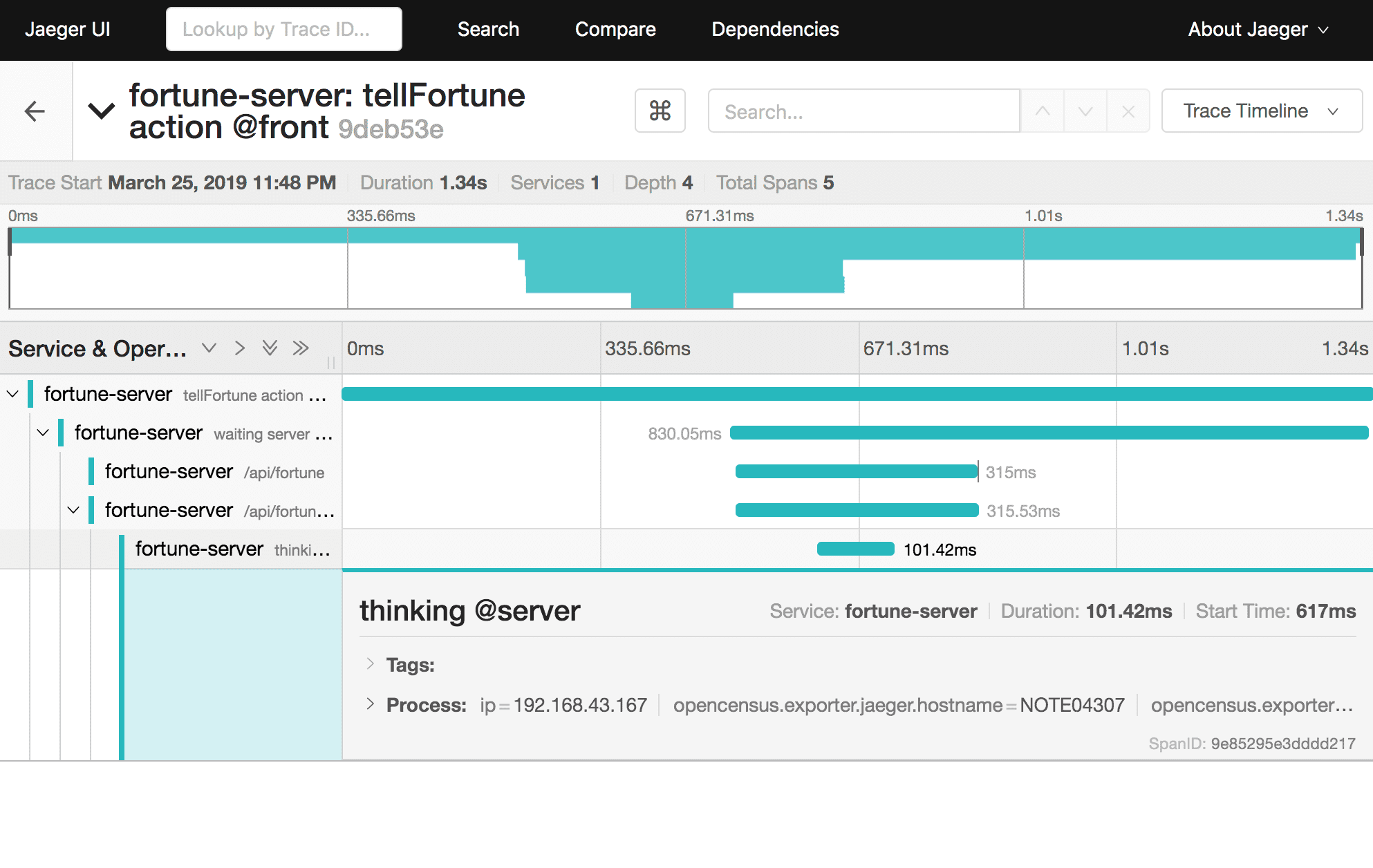
各処理にどれだけ時間がかかったのかを、ルールに従って出力することにより、複雑に関連しあったタスクでどこに問題があるのかを一目で見れるようにする。たんなるログではなく、親子関係の構造を持つログ。
- タスクのスタートと終了時に、特別なAPIを使って記録する(この1区画をスパンと呼ぶ)
- スパンを作る時には、親のスパンのIDをAPIに渡すことで、親子関係があることを通知する
- バッチ処理から作られるワーカーの場合は、スパンIDどうしをリンクすることで、関連するスパンであることを通知する
- ネットワーク越しにタスクを投げる時は、X-B3-TraceId, X-B3-ParentSpanIdといったヘッダー、gRPCのメタデータなどを介して、別プロセスでも親子関係のあるタスクを行なっていることを通知する
- スパンに対してログ、タグといったものを出力することもできる
- 分散トレースの文脈では、スパンの集合=トレース
この情報を使うことで、下記のようなグラフを表示できる。
OpenCensusとは
Borgmon由来のメトリクス、Dapper由来のトレーシングの両方に対応したライブラリ
次のような言語に対応している
- Go
- Java
- C++
- C#
- Python
- PHP
- Ruby
- Erlang/Elixir
出力先がプラグインで切り替えられる。Goのものだと、次のようなものに対応している。
- GCPのStackdriver
- Datadog
- AWSのX-Ray
- Jaeger
- Zipkin
- Honeycomb
どうやって出力するのか?
自動出力
データの出力は、OpenCensusのAPIで行うが、Integrationと呼ばれる特別なプラグインを入れると、システムの入出力で勝手にログを取ってくれる。Pythonだと次のようなものが公式で提供されている、
- DB API, Django, Flask, Google Cloud Client Library, gRPC, httplib, PostgreSQL, MongoDB, MySQL, Pyramid, Requests, SQLAlchemy, threading
Node.jsではOpenCensusをimportするだけで、勝手にHTTPのログが出力されるようになる。プロセスをまたぐような通信のログが勝手に取得できる。
Envoyというコンテナ間の通信プロキシが通信のトレース出力機能を持っているのため、Kubernetesを使うと勝手に出力される
手動でメトリックスを出力する
測定したい単位、評価基準をプログラムで作り、定期的にstats.Recordで送信する。アプリケーションでどのようなメトリックスが必要かを考えて項目を設定する。あるいは、既成の自動出力のIntegrationを参考にすると良さそう。
下記のコードはExporter設定は省略しています
package main |
メトリックスの出力先としてPrometheus(PULL型)を設定しておくと、Prometheusが読みにくるためのAPIが作成され、定期的に出力された数値を取得しにくるようになる。
手動でトレースを出力する
StartSpanとEndでスパンを出力していく
下記のコードはExporter設定は省略しています
package main |
OpenCensusの使いどころ
複数のサービスに別れているシステムだと、分散トレーシングはかなり便利なはず。
- ローカル開発では、分散トレース収集可視化のJaeger/Zipkinと、メトリクス収集可視化のPrometheusがDockerで簡単に起動できるので、これを出力先にして開発を行う
- デバッグ出力するときも、トレースでタグとして情報を出力しておくと、かなり良い
- ステージング環境ではStackdriverとX-Rayで
- たてなくても, zPageという簡易のビューアはついてくる(かなり簡易)
- 本番環境では、Stackdriverの無料枠がかなり小さいので、サンプリング頻度をかなり下げて使うか、予算に入れてきちんとお金を払う?
- トレーシングはいらないので、メトリクスだけとかに絞るとか
- あるいは自前でPrometheus、Jaeger(Zipkin)を立てる?
OpenCensusの初期化とか環境設定がなかなかめんどいので、それを簡単にするocconfigというGoのパッケージをチームのハックデー等を使って作りました。Node.js版も公開はしてないけど実装はしました。READMEに環境設定のもろもろを書いたので、参考にしてください。まあ、本当に作ったばかりの状態で実戦投入はまだなので、実際に使うといろいろ出るかもですが。OpenTelemetryへの追従もやっていきます。
また、気軽にローカルの開発で使い始められるように、今Go界隈で一番いけているという話題のロガーのzap経由でコンソールに出力するエクスポーターも実装しました。Instrumentsも色々今後は仕事しながら足していきたいな、と思っています。
今後とか
- OpenTelemetryになっても、アプリケーションに対して(Record、StartSpan, End等の)後方互換APIは用意されるとのこと
- ExporterやInstrumentの実装者はそのままではいかないかもしれない
- 出力先の設定部分以外のアプリケーションコードに埋め込まれた部分は大丈夫そうなので、とりあえず今からやるならOpenCensusでやっていけば良さそう。
- OpenCensusはGoがプライマリーの扱いだったが、OpenTelemetryはリポジトリを見る限りでは、Java中心
- OpenCensus時代にも、Agent/Collectorというものが作られていた
- fluentdみたいなやつ。Exporterをアプリケーションで設定するのではなくて、Agentに設定すると、アプリケーションが相手先のシステムが何かを知らずに(気にせずに)出力できる
- CollectorはAgentの出力を集めて、実際の集計サーバーに転送する、というコンセプト
- 現在でも安定はしていないが、OpenTelemetryはProxy, Sidecar, AgentというのがProject Overviewに明記されているので、こちらが主流になる? とはいえ、C#のリポジトリを見ると、exporterも依然として存在する模様
- 用語が少し整理される?
- InstrumentはCollectorとなる?
その他の情報源
OpenCensusの情報はまとまっていなかったので、次のページを作ってみました。
あとは、Observability JapanというDiscordのグループもあります。