はじめに
エンタープライズでのミッションクリティカル領域においてもクラウド利用が普通になってきています。
その過程において今までできないことを指向する試みも行われてきています。その代表的なものがクラウドの備えるリソースの高い拡張性と弾力性を利用したシステム展開です。例えば「より多くのデータを扱う」「同業他社に向けたサービス展開をする(マルチテナンシー)」といったものがあります。その際のアーキテクチャ選定では将来の利用を想定した選択を行う必要がありますが、データベースのスケールというのは非常に難しく簡単ではありません。
各種の要件に応じてデータベースを選定するということは多く行われていますが、その中で一番考え方が難しいスケーラビリティにどう立ち向かうかについて記載していきます。データベースについては全ての要件を満たせる「万能」なアーキテクチャが存在しないのが実情です。そのためスケーラビリティを確保するための工夫とアーキテクチャを決定するロジックが必要となります。
大事なのは、データベースのアーキテクチャだけではなく、データ特性(データモデル)の2つの目線で考えるということです。どちらかだけに偏ると、システム要件は実現できたとしてもTCOの増大を招くことになりその選択を後悔することになります。
データベースとしてのスケーラビリティ
データ―ベースに求められる要件は当然利用方法により異なりますが、大きく分けて2種類ありそれぞれ重視されるポイントが異なります。
| # | 用途 | 特徴 | 重視されるポイント |
|---|---|---|---|
| 1 | トランザクション型 | オペレーション用途に利用されてデータの記録と作成が行われる | 応答性能(レスポンス)重視 |
| 2 | アナリティック型 | データ分析用途に利用されてデータの参照に利用される | 単位時間処理(スループット)重視 |
この2つのタイプは重視されるポイントが異なることからスケーラビリティの確保の考え方が異なっています。
(2)アナリティック型についてはスケーラビリティの考え方は非常にシンプルで、「分散処理をする」という一択です。すなわちデータを細かい単位に分割してそれぞれの分割単位で処理を並列に実行するという考え方です。その実現にはRDBをベースとしたものとHDFS(Hadoop)をベースとしたものがあり、クラウドサービスで考えたときには代表的なものとして以下があげられます。
| # | クラウドサービス | RDB型プロダクト | HDFS型プロダクト |
|---|---|---|---|
| 1 | AWS | Redshift | Amazon EMR |
| 2 | Azure | SQL Datawarehouse | HDInsight |
| 3 | GCP | BigQuery | Google Cloud Dataproc |
| 4 | AWS/Azure/GCP | Snowflake | - |
こちらについてもテーマとしては面白いのですが、スケーラビリティという点では大きな違いはないため、別の機会に譲ります。
今回のテーマとしたいのが「トランザクション型データベース」におけるスケーラビリティです。
これについて検討する上で、「トランザクションとは」という点の正しい理解が必要となります。
トランザクションとスケーラビリティ
トランザクション(transaction)は文字通り「trans + action」であり、複数のデータの読み書きを論理的な単位でまとめて扱うことがその定義となります。ここであらためてトランザクションを扱うシステムのもつ概念(ACID特性)について記載します。
| ACID | 説明 | 実現するための機能 |
|---|---|---|
| Atomicity 原子性 | トランザクションは完全に実行されるか、実行されないかのどちらかであること | コミット機能 |
| Consistency 一貫性 | あらかじめ定められた整合性を満たすことを保証すること | アプリケーションで実現 |
| Isolation 独立性 | トランザクションを同時に実行しても他のトランザクションには影響を受けない(受けないことを保証する)こと | 排他制御/トランザクション分離レベル |
| Durability 耐久性 | トランザクションの結果は永続化されること | トランザクションログ |
一貫性(Consisteny)は、データが矛盾なく記録されていることを意味しますので「データベース」として実現するものではなく、「データベースを利用するシステム」により実現することとなります。つまりアプリケーションにて実現するものとなります。
独立性(Isolation)は非常に重要な概念ではあるのですが、一般的には以下のように考えられています。
- どのレベルで実現するかというものをトランザクション分離レベルとして4段階で定義されており、独立性と性能とトレードオフになることからシステム要件に合わせて使い分けることをおこなう。
- 広く使われる分離レベル(Read committed)は、低い独立性レベルであり、ファントムリード・非再現リードというデータ一矛盾が発生する可能性があるが性能面の影響は比較的少なく、アプリケーションの実装手段の工夫により回避することや許容可能である。
- 実装手段の工夫とは、トランザクションでの排他ロックの利用、更新する際に他トランザクションでの更新があったかの値チェック(compare and set操作、楽観的ロックとも言う)などがある。
このことから、データベースのスケーラビリティを考えるうえでの本質的な要素は原子性(Atomicity)と耐久性(Durability)であると言えます(あくまでもスケーラビリティを考えるうえでの話です!)さらに、原子性と耐久性は「トランザクションログ」により確保されるのが一般的です。
正しく理解するためにトランザクションログの説明をWikiより転記すると以下です。
計算機科学のデータベースの分野において、トランザクションログ(英: transaction log)(または データベースログ, バイナリログ とも呼ばれる)とは、クラッシュやハードウェア故障があったとしてもデータベース管理システムのACID特性を保障するための操作履歴を指す。ログは電源が途絶えてもデータを保持できる補助記憶装置上のファイルに出力される場合が多い。
データベースが起動後に、整合性の無い状態であるか、正常に終了されていないことを検知すると、
データベース管理システムはトランザクションログを読み取り、以下の操作を行う。どちらも原子性と永続性を保障するために必要である。完了していない または ロールバックされたトランザクションが行った操作を取り消す。
コミットしているが、データベースには反映されていない操作を再実行する。
トランザクションログとは、耐久性を確保するための仕組みだがデータベースに障害が発生した場合には原子性の確保するために利用されるものであることになります。データベースは正常時には揮発性メモリ(キャシュ)内で行われるが、操作履歴となるトラクションログが必ず不揮発性領域に(通常はファイル)保存されることになります。裏を返すとトランザクションログが作成されないとデータの更新はできないことになります。
そのため、トランザクションログの保存がデータベースのスケーラビリティを決定する決定的な要素となります。
トランザクションログは製品ごとに名称は異なりますが概念としては同一のものとなります。
| タイプ | プロダクト | ログ名称 |
|---|---|---|
| RDB | Oracle | REDOログ |
| RDB | PostgreSQL | WALログ |
| RDB | MySQL | Binログ |
| RDB | SQL Server | トランザクションログ |
| KVS | Cassandra | コミットログ |
| KVS | HBase | WALログ |
| KVS | クラウドサービスKVS(Dynamo DB@AWS/Cosmos DB@Azure/Bigtable@GCP) | ? |
クラウドサービスKVSについては明確な説明がないため? としています。Dynamo DBではかつてはトランザクションのサポートはされておらず、「データの更新は1つのキー単位に限定したうえで、レプリケーションとクオラムの概念により耐久性を保証するが、すべてのレプリカにデータが必ず保存されるとは限らない」という結果整合性が提供されていました(参考:Dynamo: Amazonの高可用性Key-value Store[和訳])つまり複数データの原子性(Atomicity)は提供されてません(クライアント側で対応(冪等性実装)を行う必要がある)。そのためトランザクションログという概念もなかったはずです。
2019年にトランザクションサポートが提供されました(参考:Amazon DynamoDB トランザクション: 仕組み)これは非常にインパクトのある機能向上でした。この機能の利用にあたってはトランザクションログの概念が組み込まれたと推測されますが、トランザクションログの実装がパフォーマンスに与える影響を極小化するために最大25項目以内であるという制約が設定されています。トランザクションログがスケーラビリティ決定する要素であることには変わりありません。
トランザクション型データベースのアーキテクチャ
ここでエンタープライズ用途という条件における、クラウド環境でのトランザクション型データベースアーキテクチャとスケーラブル構成について一度整理しておきます。網羅感は乏しくいろいろ指摘を受けそうですが「実質的」な意味ではこの選択肢に限定されるはずです。
| # | データ構造 | スケーラブル構成 | クラウドサービス |
|---|---|---|---|
| 1 | key-value型 | 可能 | DynamoDB(AWS), CosmosDB(Azure), Bigtable/Cloud Spanner(GCP) ※1 |
| 2 | Relational型 | 制限的で可能 | Relational Database Service(AWS/Azure/GCP/Oracle Cloud) |
| 3 | Relational型 | 可能 | Oracle-RAC (Oracle Cloud) |
(※1)SpannerはRelation型が自然かと思いますが、本記事ではコアアーキテクチャに注目するためKVSと分類しました
今回のテーマのスケーラブルデータベースですが、冒頭「全ての要件を満たせる「万能」なアーキテクチャが存在しない」ということを書きましたが、Oracle RACは例外といってもいいかもしれません。しかしながら、
- コスト削減圧力は依然として高く、ソフトウェアのライセンス費用はできるだけ抑えたい。
- 機能的に不足している部分はアプリケーションの工夫で対応するほうがリーズナブル。
- クラウド環境を固定化するのは避けたい(いざとなれば他へ移すことも容易であるという選択をしたい)
ということもあり、今回は(1)(2)に特化して議論を進めます。
今回の内容はあくまでも「手段」の話をしています。決して「目的」としてはいけないというのは言うまでもありません。
Key Value型とRelational型の選択
このテーマは深みのあるテーマではあるのですが、「できる・できない」という技術や手法ではなく、扱うデータモデル(データ種)のデータ管理面で考察してみます。
「データモデル」とは物理的なテーブルではなく、情報のまとまり(エンティティ)を抽出したもので以下の原則に従います。
- データの整合性を保つために正規化(通常は第三正規化)設計を行うのが原則です
- 物理設計(いわゆるテーブル設計)に落とし込む際に、あえてそれを崩す非正規化の手法を行う場合があります
次の表の中で非正規化とあるのは、あえて正規化を崩していることを意味していますので、データの整合性を保つための施策を実装時におこなう必要があることを意味しています。なおこの表はパフォーマンスという点の評価はしていません。

ここで言えるのは、key-value型は扱うデータモデルを選び、実装面の工夫が必要であるのに対して、Relational型はデータモデルとしての制約はないということです。このことから以下のことが言えます。
(1) この表でFitするデータ種を主体に扱う場合にkey-value型を選択する。
(2) エンタープライズ領域では、データ種や業務オペレーションは多種多様なことから一般的にはRelational型が選ばれることが多い。
(3) 特にスケーラビリティが求められる場合に、Relational型を基本としたうえで何らかの施策が必要。
ここで、(1)の選択はデータベースの特徴を踏まえて選択することから容易です。難しいのは(2)と(3)の判断となります。(2)で実装するのであればシンプルでもあり実装コストも非常に読みやすいのですが、(3)を選択した場合には実装コストにも大きく影響します。すなわち実現しようとしているシステムにおいて(2)でどこまでの範囲を実現できるのかがポイントになるのです。さらに、(2)では実現できない場合に(3)の選択をとる必要があるがどのようなアーキテクチャにすればよいのか。
データモデルの観点からシステムの特徴をつかむ
まず自分たちが取り組もうとしているシステムについての特徴をつかむ必要があります。今行わなくてはいけないのはデータベースのスケーラビリティの判断ですが、やみくもに性能指標値(TPS:秒間トランザクション数、QPS:秒間クエリー実行件数)を求めるのではなく、データモデルを中心として考える必要があります。
下の図では「小売業での在庫管理」を示す例となります(まったくの架空のデータです)。ECも展開していることからEC受注処理も入っています。主なオペレーションがどのエンティティにアクセスするのかのCRUD情報を示しています。アーキテクチャを検討する際に具体的なアプリケーションの設計は完了していないのが普通ですが、その企業の業務規模は見えているのが普通ですがからこの程度の情報は収集することは可能でしょう。
もちろんシステムにはこのほかにも多様な業務処理が存在し、エンティティも無数に存在しますが、主要なエンティティという視点で見渡すと意外にシンプルな形になります。データを中心に業務が動いているということを改めて感じるはずです。
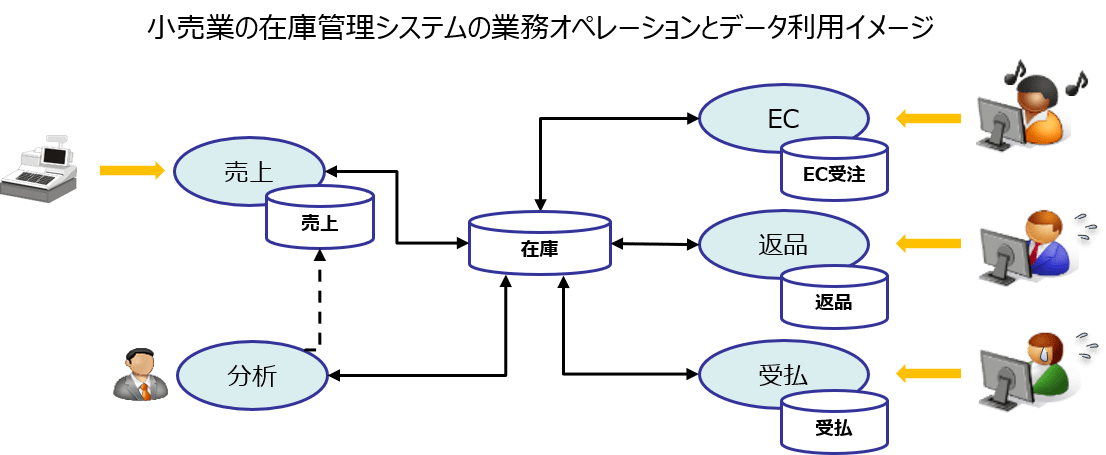
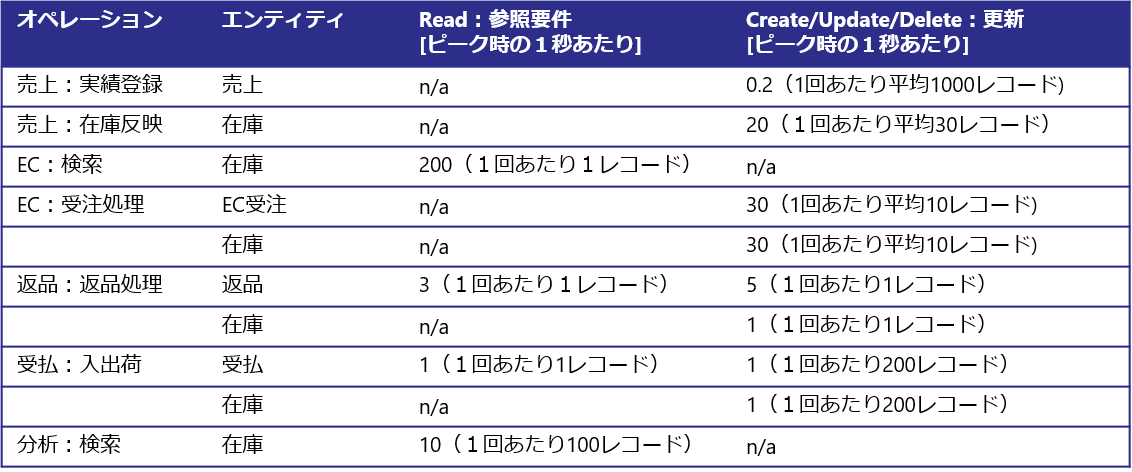
この例では次のことが言えます。
- 参照は主に在庫データについて行われており、約200QPSである。
- 更新は主に在庫データについて行われており、約100TPSである。
経験上、この例のように「在庫エンティティ」といった高頻度に更新されるリソース系エンティティが存在する場合、データベースのスケーラビリティに悩むことが多いと感じます。
次に、データ参照とデータ更新についてそれぞれ確認していきます。
データ参照のスケーラビリティ
これについては従来から対応方法は明確にあります。DBのレプリケーション技術を用いて別のインスタンスからデータを参照するという方法でMySQLやPostgreSQLでサポートされています。クラウドベンダーの提供するRelational Database Serviceでは比較的容易に実現可能です。
- MySQLによReadonly用レプリケーション構成例
Using Replication for Scale-Out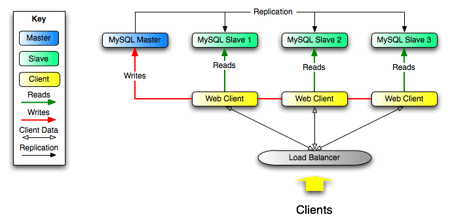
2.Amazon AuroraでのReadonly用レプリケーション構成例
Amazon Aurora DB クラスター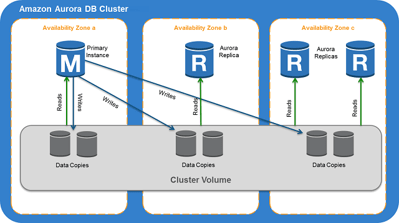
ここで紹介したように、データ参照(ReadOnly)についてのスケーラビリティという点については解決策があり、アーキテクチャとしての課題はないと考えてもよいでしょう。もちろん実装にあたっては十分な検討が必要です。
データ更新のスケーラビリティの判断
ここが本記事の一番のポイントになるところです。レプリケーションによりデータ参照のスケーラビリティの確保は可能ですが、あくまでもデータ更新可能なデータベースインスタンスは1つです。そのため、そもそもそのデータベースでどのぐらいのトランザクション処理が可能なのかを把握しないことには次の検討ができません。
これについてはやってみるしかない。という答えになってしまうのですが、それでは、何をやれば把握できるのでしょうか。
これまでに、トランザクションログの保存がデータベースのスケーラビリティを決定する決定的な要素となるということをすでに述べています。そうであるのであればこのトランザクションログに依存する性能が何によって決定するのかということを考えると決定できます。すなわち以下となります。
- トランザクションログの書き込まれるタイミングはcommitタイミングである。
- ランザクションログの 書き込まれる量は更新データのサイズに依存する。
これを先ほどの在庫管理システムに当てはめて考えてると以下のようになります。

約100TPS発生して、データ更新(insert/update)が約1500レコード発生しています。
このほか多数の業務が実施されているわけですし厳密に求めることは意味がありません。あくまでも傾向分析をしたいのでこの程度の情報で十分です。
この要件を実現できるかを実際にサンプルプログラムを作成して試してみます。その際に1レコード当たりのレコードサイズも重要な要素となるためこの値は現実的な数値で代表させるのが良いでしょう。また、updateとinsertではトランザクションログの発生量も変化するためにより負荷の高まるupdateに統一して試してもよいでしょう。このあたりは柔軟に考えればよいでしょう。ここでは100TPS発生してその際に15レコード更新されると仮定してみます。
得られたテスト結果が以下です。「records」はトランザクションあたりの更新レコード数を示します(このテスト結果はテストシナリオにおけるあくまでもサンプルです)
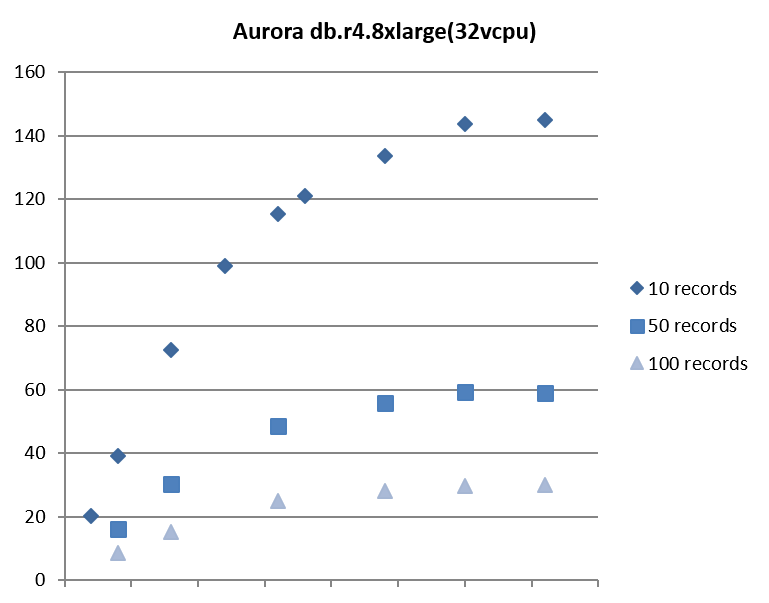
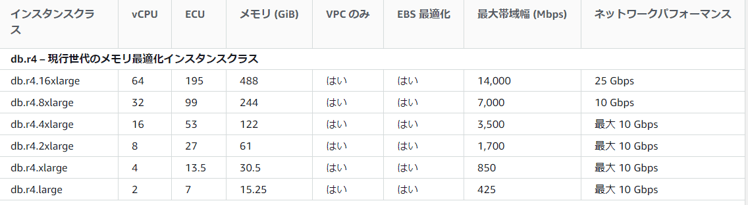
この結果から、AWS Aurora (PostgreSQL)で今回の要件を実現する場合には、r4.8xlargeを利用した場合において実現性はありそうということが推測できます。
ただ、テストは単純化していますので実際のアプリケーション実装時の余裕率や将来のビジネスの伸びを考えるとやや心もとない感じがします。またさらに上のインスタンスクラスのr4.16xlargeでテストすることでTPSは向上する可能性はありますが、コストも2倍となることから費用面から積極的に選択することが難しそうです。
そのためこのような要件がある場合は、1つのデータベースインスタンスでの実現はリスクがあると判断し、よりスケールするための施策を模索することに舵を切ることことになります。反対にこの調査を行った結果、十分に余裕があるということであればスケーラビリティは十分確保されているということが言い切れます。
Relational型データベースのスケーラブル構成
1つのデータベースで扱うトランザクションに限界があるということですから、データベースを増やせばよいということになります。すなわちスケーラブルな構成とは扱うデータを分割して管理することになります。
その方法は以下の3つです。
(1)業務分割パターン
(2)論理分割パターン
(3)データ分割パターン
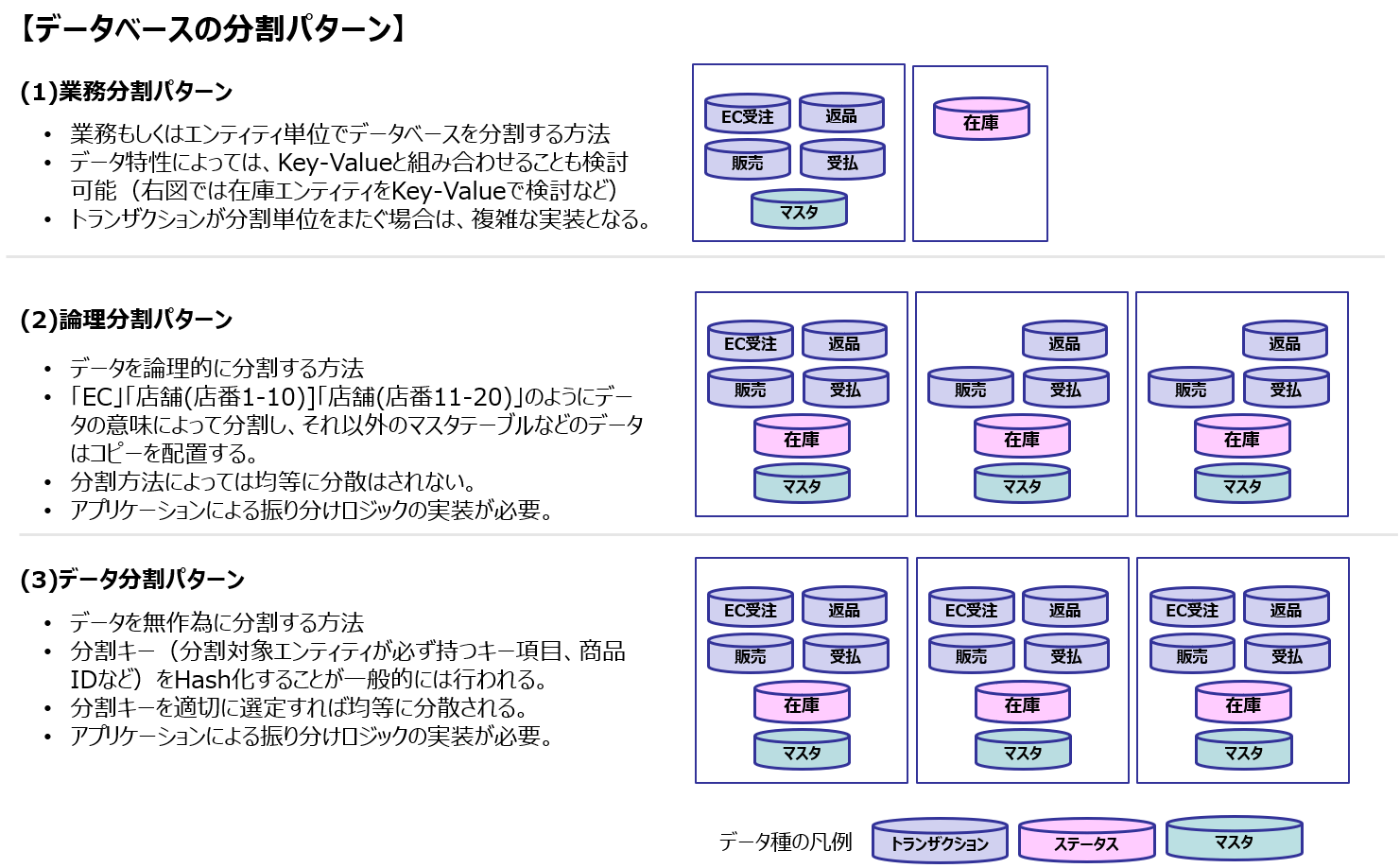
どのパターンを選択すべきかは、要件によって変わるため答えは1つではありません。
経験上ですが、
- エンティティをまたがるオペレーションが多く、トランザクション管理を実装するコストを考えると実現が厳しい
- 業務的はある一定の論理単位(例えば店舗)で行われることが多い
という観点で(2)を選択する場面が多いような気がします(この時、十分に議論をしたうえで決定するのが重要です)
また、業務規模が大きくエンティティも複雑で、保守性をより強固に持ちたい場合には、マイクロサービス指向に合致している(1)が選択されるでしょう。
Relational型データベースのデータ保持
スケーラブルな構成とするためには実際のデータをどのように保持するのかについても検討する必要があります。データ保持形態によってスケーラビリティに制約が出ると本末転倒となるのでここまでの検討は事前に行う必要があります。
先ほどの例の「論理分割パターン」において、店舗(=店コード)で分割した場合を考えます。同一データベースにある各店舗のデータをどのようにテーブル保持するのかがポイントです。
この部分の検討は、データベースソフトウェアに深く依存することになりますので、事前の調査はしておく必要があります。以下の図はPostgreSQLをベースとした検討例です。
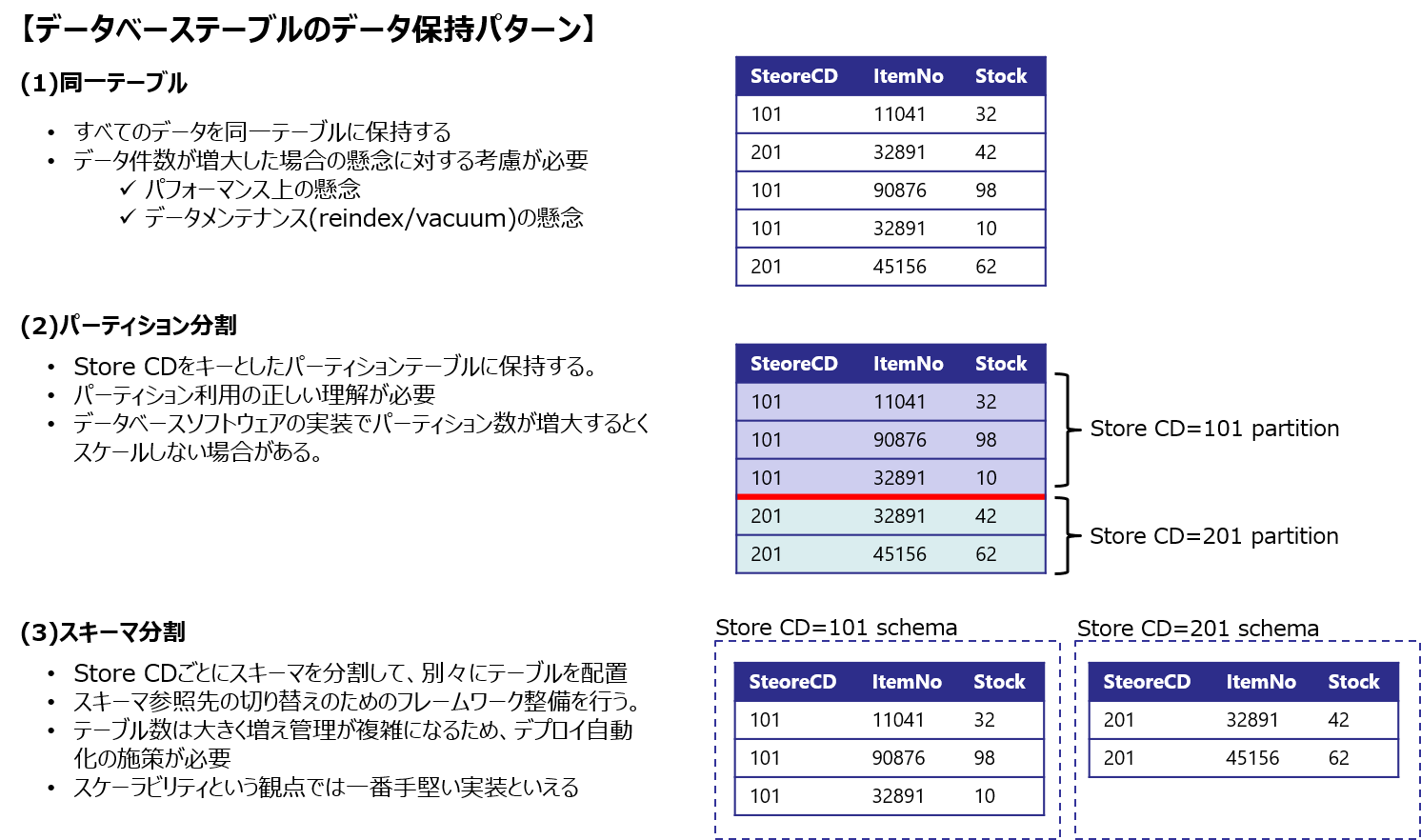
PostgreSQLのパーティションの特性についてここで詳細は記載しませんが制約事項について理解する必要があります。理屈上は正しいが、実装してみると正しくスケールしないということもあるため確認したほうが良いでしょう。以下に参考リンクを載せておきます。
- PostgreSQLパーティションプルーニングの動作を確認する
- PostgreSQL11でのテーブル・パーティショニング機能の改善
- PostgreSQL 12: Partitioning is now faster
(3)のスキーマ分割はデータの論理分割パターンにおける究極の形です。テーブル管理が手間が非常となりますが、わかりやすさと運用での安定性から意外と悪くない方法だと考えています。
まとめ
だいぶ長くなりましたので、最後にこれまに検討してきた内容をまとめてみます。
- データベースのスケーラビリティにはトランザクションログが決定的な影響を与えることについて解説しました。
- 実現にあたって、key-value型とRelational型の選択の考え方について解説をしています。実際の場面としてRelational型を基本として検討することが多いが、実現にあたっては通常の方法でできるのか、特別な施策が必要なのかという範囲の見極めについて議論しました
- スケーラビリティの検討にあたっては、まずはデータモデルという視点で検討を行い、スケーラブル構成をとるべき判断ポイントについての例をあげました。
- Relational型のデータベースの構成例とテーブル実装方法について検討しました。
ここまでの流れを一通り理解することにより「何となく決める」ではなく「根拠をもって決める」ということが可能になるはずです。後悔しない(←これ大事です。つまり無理をした実装はTCOの増大を招くことになります)スケーラブルデータベース構成を自信をもって決定できるでしょう。
今回はトランザクション型データベースということで触れなかったアナリティック型データベースについての考察はいずれまた記載してみます。
おわり。
(この記事も書きました)