
フューチャー夏休み自由研究連載12本目の記事です。
はじめに
はじめまして。TIG DXユニットの富山です。2020年4月新卒入社です。
夏休み自由研究連載の11本目の記事で公開されたSlack×GASの日報テンプレBOTを実務に導入してみたの執筆者である仁木さんと同期です。
私が参画しているプロジェクトでは、データベースにDynamoDBを採用しています。私は、RDBMSしか使用した経験がなかったので、NoSQLであるDynamoDBの理解にとても苦しみました。そこで今回の夏休み自由研究では理解した内容をまとめてみたいと思います!
つまったポイントサマリ―
- DB = RDBMSという固定概念を取り除くこと |
これらが理解できるような記事を目指します。
DynamoDBとは
公式ドキュメントによると、
Amazon DynamoDB は、規模に関係なく数ミリ秒台のパフォーマンスを実現する、key-value およびドキュメントデータベースです。完全マネージド型マルチリージョン、マルチマスターで耐久性があるデータベースで、セキュリティ、バックアップおよび復元と、インターネット規模のアプリケーション用のメモリ内キャッシュが組み込まれています。DynamoDB は、1 日に 10 兆件以上のリクエストを処理することができ、毎秒 2,000 万件を超えるリクエストをサポートします。
とのことです。とりあえずすごいと言うことはわかりました。
ざっくりと、AWSが提供するkey-value型のハイパフォーマンスNoSQLフルマネージドサービスです。
NoSQLとは
そもそもNoSQLとは何者でしょうか。次世代的な響きがしてカッコいいですよね。
わたしはDynamoDBを触り始める以前、Yes/NoのNoSQLだと思っていましたが、 Not Only SQL の略称です。NoSQLについてWikipediaから冒頭の説明文を引用してみましょう。
NoSQL(一般に “Not only SQL” と解釈される)とは、関係データベース管理システム (RDBMS) 以外のデータベース管理システムを指すおおまかな分類語である。関係データベースを杓子定規に適用してきた長い歴史を打破し、それ以外の構造のデータベースの利用・発展を促進させようとする運動の標語としての意味合いを持つ。
つまり、RDBMS以外のDBシステムを指す大まかな定義の単語のようです。
一口にNoSQLといってもデータ形式の格納方式の違いで様々なタイプのNoSQLが存在します。大きくは下記3つに分類されます。
1. KVS (Key-Value-Store) |
DynamoDBはKVSのNoSQLに該当します。
RDBMSとの志向の違い
RDBMSとNoSQLは異なる志向を持ちます。RDBMSはACID(Atomicity、Consistency、Isolation、Durability)という特性で語られます。ざっくりと、トランザクションにおいて持つべき4つの特性(原子性/一貫性/独立性/永続性)を表現したものです。
それに対して、NoSQLはBASE(Basically Available、Soft-State、Eventual Consistency)特性という特徴で語られます。
ざっくりと、「基本的には常に利用可能で、常に整合性を保っている必要はなく、一時的に一貫性のない状態を許容して、結果的には整合性が取れている状態に至る」 というものです。ACIDとは対照的に、可用性や性能を重視した分散システムの特性です。
ということは、「DynamoDBでトランザクション制御はできないの?」とお考えの方もいらっしゃると思います。後述します。
余談ですが、ACID(酸)に対して、BASE(塩基)とはめちゃくちゃイケてるネーミングですね。
DynamoDBの特徴
高可用性
DynamoDBでは高可用性を重視しています。具体的には3つのAZ(Availability Zone)でレプリケーションを持っています。そのためAZに問題が起きても、他のAZが機能するため耐久性・信頼性が担保されています。
フルマネージド
データ容量の増加に応じたディスクやノードの増設作業をはじめ、メンテナンスが不要です。テーブルを自動的にスケールアップ/ダウンして容量を調整し、パフォーマンスを維持してくれます。
SQLクエリを直接はサポートしていない
NoSQLとだけあってSQLを直接サポートされていません。そのためテーブルの結合も行えません(DQLなど、SQLライクに書けるラッパーは存在します)。。
シンプルなCRUDに対しては非常に有効ですが、複雑なものが不得意なのかもしれません。
DynamoDBを触る上で抑えておくべきポイント
下記のテーブル構造を例に説明していきます。ペットショップのペット管理用DBです(笑)。
主要概念
DynamoDBには、いくつかの独自概念が登場します。
イメージ的に、RDBMSの既存概念と似ているものがあるので表にしてみました。
| DynamoDB | RDBMS |
|---|---|
| Table | Table |
| Item | Row |
| Attributes | Column |
| Partition Key | Primary Key |
| Sort Key | 指定する場合はPrimary Keyを構成する一部になる |
今回の例だと、このようになります。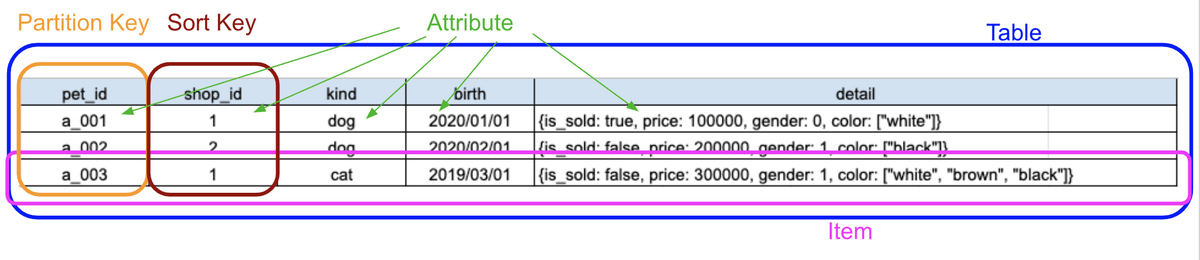
ポイントとして、Itemは正規化の必要が無い点です。つまり異なるItemで同名のAttributeを持つ必要はありません。また、 detail のようにAttributeにネストしたデータ構造を持たせることも可能です。
Table、Item、Attributeに関してはある程度理解が出来ると思います。
パーティションキーとソートキー
DynamoDBを触る上で絶対に抑えて置かなければならない概念に、パーティションキー(別称:ハッシュキー)とソートキー(別称:レンジキー)が挙げられます。
パーティションーキー、もしくはパーティションキーとソートキーによってユニークなItemを表現します。
DynamoDBでは、Itemを内部的にパーティションごとに分散して保持しています。パーティションキーは内部的にハッシュ関数が実行され、ハッシュ文字列が生成されます。生成されたハッシュ文字列をもとに、Itemの格納場所が決まります。そのためパーティションキーは必須です。
ソートキーでは範囲指定やソートが可能です( shop_id をソートキーにするべきかは見逃してください)そのため、ソートキー以外のAttributeでのOrder byは不可能です。ソートキーの設定は必須ではありません。
Secondary Index
先程パーティションキーとソートキーについて説明をしましたが、Secondary Indexはプライマリキー以外の属性を使用する際に登場する概念です。
Secondary Indexには、LSIとGSIという2つの概念が存在します。
LSI
Local Secondary Index の頭文字を取っています。LSIは、ソートキー以外での絞り込みを行うキーを設定できるものです。
例でいうと、birth をLSIに設定した場合、 pet_id + birth のような検索ができるようになります。
注意点として、LSIは既存のテーブルに追加・削除はできません。テーブル作成時に定義するようにしましょう。
GSI
Grobal Secondary Index の頭文字を取っています。GSIは、パーティションキーを別途設定できるものです。
例でいうと、kindでdogのItemを取得したい際に、 kindをGSIに設定することで検索が容易にできるようになります。
LSIと異なり、既存のテーブルに追加・削除できます。
しかし、GSIを1つ定義すると、テーブルが1つ増えるのと同等のコスト増しになります。
DynamoDBでトランザクション制御は可能なのか
可能です。詳細については公式Docsをご参照ください。
単一のAWSアカウントおよび領域内の複数のテーブルにわたって、ACIDを提供しています。
ここではDynamoDBにおけるトランザクション制御の特徴を挙げます。
DynamoDBにおけるトランザクション制御についての特徴
- 複数テーブルに対して制御できる
- トランザクションに含められるのは25件まで(記事執筆時点(2020/08/17))
- テーブルのロックはされない
- もし、トランザクション中に他操作が入った場合、トランザクションは中止されて例外が返ってきます。
- 同一Itemに対して操作はできない
- 全ての商用リージョンで利用可能
プログラムからどのように触るのか
aws-sdkが公開されています。主要なサーバサイドの言語はサポートされているのではないでしょうか。
FutureのDXユニットではGoを積極的に使う文化があります。私もGopherの仲間入りを果たしました。
もちろんGoのsdkも公開されています。また、ラッパーされたライブラリもいくつかあります。
詳しくは私の先輩方の最高に分かりやすい記事をご覧いただければと思います。CRUD操作のサンプルコードが書かれており、大変参考になります。
DynamoDB×Go連載#1 GoでDynamoDBでおなじみのguregu/dynamoを利用する
DynamoDB×Go連載#2 AWS SDKによるDynamoDBの基本操作
よく触るItem操作まとめ
私的によく触るItemの操作APIをまとめます。
様々な操作APIが存在するので、どのAPIを使用すると何が出来るのかを把握するのに苦戦しました。
読み込み
| API | できること |
|---|---|
| GetItem | ユニークキーを指定してデータが1つ取得 |
| TransactGetItems | トランザクションにて最大25件取得 |
| BatchGetItem | 最大100アイテム (ただし、16MBを超えないアイテム数) を並列で取得 |
| Query | 特定のパーティションキーがあるすべての項目を取得 |
| Scan | すべての項目(1度の操作で最大1MB。それを超えたらLastEvaluatedKeyを指定して再読み取りが必要)のデータを取得(filter式あり) |
書き込み
| API | できること |
|---|---|
| PutItem | Itemの登録 |
| Update | Itemの更新 |
| TransactWriteItems | トランザクションにてCreate, Update, Delete制御 |
| BatchWriteItem | 最大25件のバッチ処理(入力/削除)。(最大1MB) |
| Delete | Itemの削除 |
DynamoDBを触るうえでの注意点
最後に、実際に触ってみて「独特だなぁ」と感じた部分について記載します。
- パーティションキーやソートキーに空文字は入れられない
- タイムスタンプの概念が存在しないので、文字列での登録が必要(日付型自体はサポートされています。ソートキーとして定義した場合、日付のソート等は可能です。詳しいデータ型に関してはこちらをご参照ください)。
- テーブルの結合ができない
- 基本的にAPI経由で触る
- AWSのクレデンシャル情報で認証
おわりに
今回は自由研究ということで、DynamoDB未経験だった私が詰まったポイントを踏まえ入門編としてまとめてみました。
個人的な感想として、DynamoDBはキー設計がとても重要だと感じました。今後、もっと踏み込んだ記事も執筆していけたらと思います!
参考文献
AWS DynamoDB公式Docs
Amazon DynamoDB Deep Dive | AWS Summit Tokyo 2019
AWS Black Belt Tech シリーズ 2015 - Amazon DynamoDB
「RDBMS」と「NoSQL」の比較
NoSQL wikipedia
コンセプトから学ぶAmazon DynamoDB【Amazon RDSとの比較篇】