ARMなMacが出るとWWDCで発表されてから首を長くしてまっていて、発表と同時にMacBook Proを買って、アプリケーションのARMネイティブ対応がされているかいろいろインストールして試してみたりしています。まだ発売されて2週間足らずですが(といっても、みんな開発キットをつかって以前から準備したようですが)、動作しているアプリケーションは多いです。発売後にも、Erlang、Node.jsあたりはmasterブランチにパッチが入りました。Goも、昨日パッチがマージされました。
業務利用が多い言語のうちの1つということで、手元のPCで軽くベンチマークをとってみました。使った機種は3つです。
- 2020モデルのM1のMacBook Pro
- 2020モデルの10th Gen Core i5のMacBook Air
- Ryzen 9 4900HSのASUSのZephyrus G14
前2つがTDP 10Wクラスの中、RyzenだけTDP 35Wでだいぶ上のクラスではあります。ベンチマークはgithub.com/SimonWaldherr/golang-benchmarksを利用しています。Goはmasterの0433845をとってきて、Intel Mac上から、bootstrap.bash で arm64/darwin、amd64/darwin、amd64/windows の3セット作って使いました。コア数はそれぞれ8(低速4+高速4)、8(物理4、論理8)、16(物理8、論理16)と構成に違いはあるものの、特にマルチスレッド性能を測るテストはなく、-cpuオプションを設定しても結果は違いがなかったので、デフォルト値で実行しています。
ベンチマークの数値の結果はこちらです。Goのベンチマークはタスクごとの経過時間で出てくるので、MacBook Airの結果を100として相対値をとってグラフにしたのが以下の図です(項目が多くてラベルが半分非表示になっていますが)。グラフは短いほど高速です。
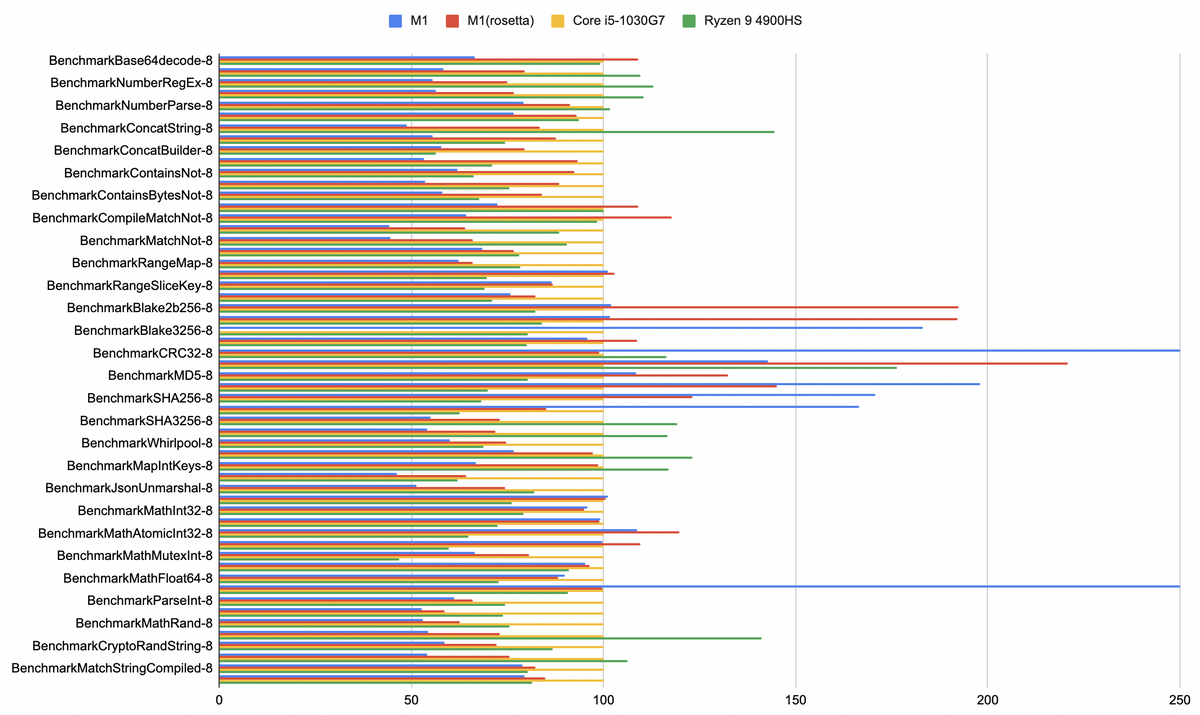
たまにハッシュ計算とかでかなり遅いものがありますが、おそらくCPUの命令を駆使して高速化、みたいなのがまだきちんと行われていない領域だと思うので、そこはコミットチャンスかと思います。あと、Boolのパースがなぜか遅い。といっても1.5nsと0.3nsとかなので割合でみるとすごい遅く見えますが、実際には影響は少ないかと。
大雑把にみると、MacBook AirのCore i5に比べて概ね1.5〜2倍ぐらい高速ですね。Ryzenに対してもかなり高速。この2機種とも、今年の頭のモデルで比較的新しくてそこまで遅くないのですけどね。ただ、Ryzen機が暖かいので(GeForceのGPUのおかげかもしれませんが)、寒い冬にはとても優しいので、個人的にはRyzen優勝にしたいと思います。
詳細な結果は以下の通り。単位はnsで、数字が小さいほど高速です。
| M1 | M1(rosetta) | Core i5-1030G7 | Ryzen 9 4900HS | |
|---|---|---|---|---|
| BenchmarkBase64decode-8 | 75.52 | 124 | 113.6 | 112.8 |
| BenchmarkBase64regex-8 | 13271 | 18101 | 22755 | 24957 |
| BenchmarkNumberRegEx-8 | 8616 | 11622 | 15494 | 17492 |
| BenchmarkFulltextRegEx-8 | 7098 | 9619 | 12552 | 13851 |
| BenchmarkNumberParse-8 | 54.91 | 63.28 | 69.32 | 70.62 |
| BenchmarkFulltextParse-8 | 783.4 | 949.1 | 1020 | 955.1 |
| BenchmarkConcatString-8 | 23788 | 40679 | 48756 | 70460 |
| BenchmarkConcatBuffer-8 | 4.792 | 7.568 | 8.636 | 6.425 |
| BenchmarkConcatBuilder-8 | 2.662 | 3.659 | 4.594 | 2.595 |
| BenchmarkContains-8 | 5.465 | 9.55 | 10.23 | 7.279 |
| BenchmarkContainsNot-8 | 6.993 | 10.45 | 11.29 | 7.489 |
| BenchmarkContainsBytes-8 | 6.198 | 10.21 | 11.55 | 8.718 |
| BenchmarkContainsBytesNot-8 | 7.74 | 11.2 | 13.31 | 8.996 |
| BenchmarkCompileMatch-8 | 80.4 | 121.3 | 111.1 | 111.1 |
| BenchmarkCompileMatchNot-8 | 35.95 | 65.89 | 55.98 | 55.14 |
| BenchmarkMatch-8 | 870.8 | 1261 | 1969 | 1745 |
| BenchmarkMatchNot-8 | 837.3 | 1237 | 1875 | 1697 |
| BenchmarkForMap-8 | 20.56 | 22.97 | 29.94 | 23.39 |
| BenchmarkRangeMap-8 | 55.31 | 58.52 | 88.86 | 69.77 |
| BenchmarkRangeSlice-8 | 3.8 | 3.865 | 3.758 | 2.619 |
| BenchmarkRangeSliceKey-8 | 4.528 | 4.545 | 5.23 | 3.617 |
| BenchmarkAdler32-8 | 764.9 | 830.3 | 1007 | 714.6 |
| BenchmarkBlake2b256-8 | 2612 | 4930 | 2561 | 2105 |
| BenchmarkBlake2b512-8 | 2626 | 4958 | 2580 | 2167 |
| BenchmarkBlake3256-8 | 6339 | エラー | 3460 | 2782 |
| BenchmarkMMH3-8 | 413.4 | 468.5 | 431 | 345 |
| BenchmarkCRC32-8 | 1098 | 139.2 | 140.5 | 163.7 |
| BenchmarkFnv128-8 | 4924 | 7617 | 3448 | 6084 |
| BenchmarkMD5-8 | 3566 | 4345 | 3283 | 2635 |
| BenchmarkSHA1-8 | 5789 | 4247 | 2924 | 2041 |
| BenchmarkSHA256-8 | 10865 | 7832 | 6361 | 4346 |
| BenchmarkSHA512-8 | 7801 | 3987 | 4685 | 2939 |
| BenchmarkSHA3256-8 | 4575 | 6080 | 8312 | 9898 |
| BenchmarkSHA3512-8 | 7929 | 10540 | 14666 | 17115 |
| BenchmarkWhirlpool-8 | 35819 | 44605 | 59697 | 41050 |
| BenchmarkMapStringKeys-8 | 82.45 | 104.4 | 107.5 | 132.5 |
| BenchmarkMapIntKeys-8 | 49.72 | 73.35 | 74.43 | 87.11 |
| BenchmarkJsonMarshal-8 | 1422 | 1981 | 3076 | 1907 |
| BenchmarkJsonUnmarshal-8 | 5496 | 7963 | 10694 | 8788 |
| BenchmarkMathInt8-8 | 0.3465 | 0.3442 | 0.342 | 0.2602 |
| BenchmarkMathInt32-8 | 0.3505 | 0.3478 | 0.3656 | 0.29 |
| BenchmarkMathInt64-8 | 0.3558 | 0.3552 | 0.3588 | 0.26 |
| BenchmarkMathAtomicInt32-8 | 7.132 | 7.864 | 6.562 | 4.258 |
| BenchmarkMathAtomicInt64-8 | 7.07 | 7.758 | 7.079 | 4.231 |
| BenchmarkMathMutexInt-8 | 12.45 | 15.07 | 18.69 | 8.776 |
| BenchmarkMathFloat32-8 | 0.3594 | 0.3636 | 0.377 | 0.3438 |
| BenchmarkMathFloat64-8 | 0.3551 | 0.348 | 0.3946 | 0.2866 |
| BenchmarkParseBool-8 | 1.598 | 0.3529 | 0.3532 | 0.3208 |
| BenchmarkParseInt-8 | 12.31 | 13.28 | 20.09 | 14.93 |
| BenchmarkParseFloat-8 | 72.39 | 80.48 | 137.3 | 101.6 |
| BenchmarkMathRand-8 | 12.82 | 15.15 | 24.15 | 18.27 |
| BenchmarkCryptoRand-8 | 109.9 | 147.7 | 202 | 285.2 |
| BenchmarkCryptoRandString-8 | 119.1 | 146.1 | 202.5 | 175.8 |
| BenchmarkMatchString-8 | 5371 | 7498 | 9923 | 10558 |
| BenchmarkMatchStringCompiled-8 | 529.2 | 551.9 | 670.8 | 538.3 |
| BenchmarkMatchStringGolibs-8 | 523.5 | 559.2 | 659.5 | 538.2 |