はじめに
こんにちは、TIG中神です。
GCPで構築するサーバーレスデータレイクの連載第1弾の記事となります。GCPでデータレイクを構築する場合のポイントについて連載形式でご紹介していければと思います。
データレイクとは
まずはデータレイクがどのようなものなのか整理していきましょう。
データレイクとは?
そもそもデータレイクとはどのような定義になるでしょうか。
Wikipediaではデータレイクは以下のように定義されていますね。
データレイク (Data lake) は構造化/非構造化データやバイナリ等のファイル含めたデータを一元的に格納するデータリポジトリ。
一般的に、データレイクはレポート、可視化、分析、機械学習に利用されるエンタープライズのデータのコピーや返還後のデータを一カ所に集約する。
データレイクはリレーショナルデータベースの構造化データ(列と行)や、半構造化データ(CSV、ログ、XML、JSON)、非構造化データ(Eメール、ドキュメント、PDF)、バイナリデータ(画像、音声、映像)を含めることができる。
適切に管理されておらず、ユーザが意図するデータへのアクセシビリティが低く、小さな価値しか提供できない低品質のデータレイクはデータの沼と表現される。
その他、主要なクラウドベンダーも以下のように定義しています。
(GCP) データレイクのモダナイゼーション
(AWS) データレイクとは - Amazon Web Services (AWS)
(Azure) Data Lake | Microsoft Azure
各引用元の内容を要約すると以下のような特徴が浮かび上がってきます。
これらの条件を満たすものをデータレイクとして位置づけることが出来ると思います。
- 構造化データ、半構造化データ、非構造化データなどデータのフォーマットに関わらず一元的にデータを保存する。
- 保存したデータは分析、機械学習など様々な用途で利用される。
- データマートやデータウェアハウスとはアプローチが異なる。
データレイクで管理されるデータ群
| データ種別 | 例 |
|---|---|
| 構造化データ | RDBMS、CSVなどの行列データ |
| 半構造化データ | XML、JSONなど |
| 非構造化データ | 画像、音声、映像やPDFデータなど |
データレイクアプローチ
データレイクの特徴の1つに「データマートやデータウェアハウスとはアプローチが異なる」というものがありましたが具体的にはどのような事なのか記載します。
データレイクの検討を進めるにあたり大きな考え方として、トップダウン的な考え方とボトムアップ的な考え方の2種類があるのでご紹介します。
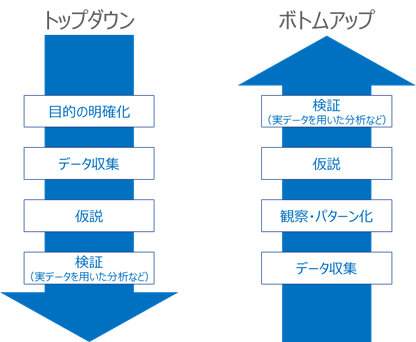
それぞれのアプローチによる違い
- トップダウン的なアプローチの特徴
- 企画時点で利用目的がはっきりしており、要件や目的に基づいて具体化していく。
- 半面、用途がはっきりしている分アドホックな作りになり拡張性が損なわれやすいリスクもあり。
- 企画時点で第三者に導入効果を説明しやすい。
- 要件や目的に基づいて具体化するため導入効果が早めに出やすい。
- ボトムアップ的なアプローチの特徴
- 企画時点でどのようにデータ活用するか明確ではないため、まずはデータ収集して観察や仮説に基づき具体化していく。
- 半面、検討に正解がないため品質や利用価値の低いデータレイク(泥沼化)となるリスクもある。
- 企画時点で第三者に導入効果を説明しにくい。
- 運用の中でPoCや拡張を継続的に行って検証していく必要があるため導入効果が出るまで時間がかかる。
どちらかのアプローチが望ましいのか?
アプローチとしてはどちらも正しいと言えます。ただし、企画時点の状況や最終的な目標をどこに置くのかによって柔軟にアプローチを変化させる必要があると考えます。
例えば、特定の利用に限定したDWHやデータマートで十分なのであればアドホックなシステムとしてトップダウンアプローチで検討していけばいいと思いますし、幅広いデータを保存するデータレイクを検討したいのであればボトムアップアプローチで検討を進めていければいいと思います。
ただ、現実的には下記で言う真ん中のパターン(ハイブリッド)が多いと思いますので、それぞのアプローチの特性や、将来像などを加味してバランスを取りながら検討を進めていく事が重要であると考えます。
- トップダウン的なアプローチが適している
- 特定の利用に限定したDWHやデータマートで十分
- トップダウンとボトムアップアプローチのハイブリッドが適している
- 企画時点では特定の利用限定で大丈夫だが最終的にはデータレイクとして拡張していきたい
- ボトムアップ的なアプローチが適している
- 幅広いデータを保存するデータレイクを検討したい
データレイクのシステム化
前置きが長くなりましたが、上記のような検討を経て、実際にどのようにシステム化するかというところですがデータレイクの特性上、どの程度のデータ量を扱うのか? どの程度のクエリが実行されるのか? あらかじめ定義することが難しいので拡張性の高いクラウドプラットフォームを活用していく事が基本的な方針になるかと思います。
その中でもGoogle Cloud Platform(以下、GCP)を使うと、比較的容易にさらにサーバーレスでデータレイクを構築できるため小規模・低コストで進めて徐々に規模を拡大していきたいような要望の場合は特に適しているのではないかと思います。
データレイクのサービスレベル
また、サーバーレスでデータレイクを構築していくにおいても、通常のシステムと同じようにどの程度のサービスレベルで提供するかという検討が非常に重要になります。内容はいわゆる非機能の定義とほぼ同じですが、データレイクで特に重要なポイントとしては以下のようなところがあげられます。
- 可用性
- システムの重要度(データレイク停止による業務影響など)、サービス継続性、メンテンナス時間の確保
- BCP対策の有無、バックアップなど
- 性能/拡張性
- 可能な限りオートスケール構成とする
- おおよその処理量やデータ量の見込みをたてる(処理量やデータ量を明確に定義することは難しいが可能な範囲で)
- 利用するプロダクトの制約・制限の把握など
- セキュリティ
- 企業や業界で準拠すべき規約やルール、個人情報の取り扱い有無、インターネットアクセスなど
- 運用性
- 監視、認証など既存のシステムとの連携
- データレイク導入後のデータ追加や利用者追加などの運用作業項目や運用体制の確立
- 運用作業は極力汎化してシンプルなものにしておくなど(特定業務向けの作業や人依存になるような運用は避ける)
データレイクの構成要素
それでは次にデータレイクを構成するためにどのような要素が必要なのか見ていきましょう。
以下はGoogleのPrinciples and best practices for data governance in the worldでも使用されている概念でGartner社により定義されたデータガバナンスのフレームワーク(Gartner, Applying Effective Data Governance to Secure Your Data Lake, Sanjeev Mohan, April 17, 2018)です。
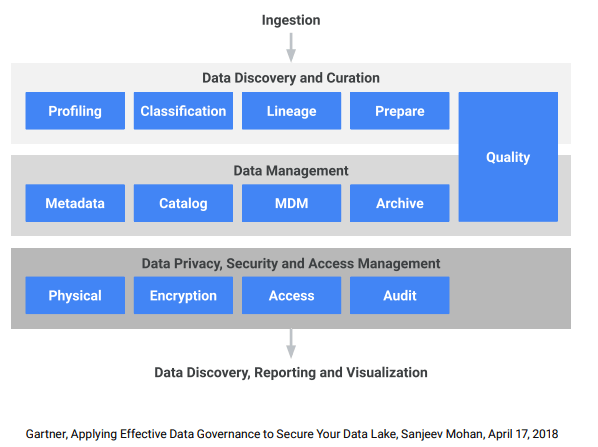
それぞれの要素で必要になる機能は概ね以下のようなところでしょうか。
これらをGCPのプロダクトを使って構成していく事になります。
| 構成要素 | 機能群 |
|---|---|
| Ingestion | 取り込み |
| Data Discovery and Curation | 収集、分類、履歴、準備、品質管理 |
| Data Management | データ管理、メタデータ管理、カタログ管理、マスタデータ管理、アーカイブ管理、品質管理 |
| Data Privacy, Security and Access Management | データセキュリティ、物理的セキュリティ、暗号化、アクセス管理、監査 |
| Consumption | 利用 |
GCPを用いたデータレイク
これらのことを踏まえてGCPでデータレイクを構築する場合、以下のようなプロダクトの組み合わせで実現可能です。
特殊な要件がない限りはサーバーレスで実現可能ですので、インフラもコード化による構成管理がしやすい状態を保てると思います。
また、データマートやデータ分析はGCP以外の場所で行うといったようにマルチクラウドな構成に柔軟に発展させることも可能です。
※特殊な機能やカスタマイズが必要な場合は仮想サーバーやコンテナが必要になることもあります。
以下は、Google Cloud スマート アナリティクス ソリューションで定義されているGCPのデータ分析関連のプロダクトになります。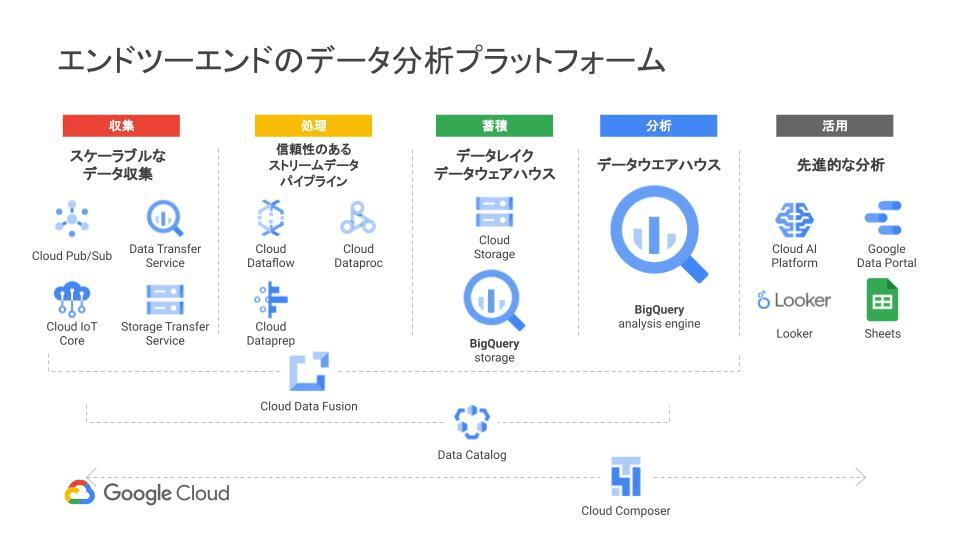
プロダクトの選択肢はいろいろありますが、データレイク関連で特に注目したいプロダクトの概要やポイントを以下に記載します。
※一部、上記の図に記載されていないプロダクトもあります。
- Data Catalog
- フルマネージドでスケーラビリティの高いデータ検出およびメタデータ管理サービス
- 構造化データ、半構造化データ、非構造化データに対するメタデータ(テクニカル、ビジネスメタデータ)の管理やタグ付けが可能
- DLPとの連携で個人情報に対するタグ付けも可能
- Cloud Data Fusion
- フルマネージドでクラウドネイティブなデータをあらゆる規模で統合可能
- GUIでETL/ELTパイプラインの作成およびデプロイが可能
- OSSのCDAPがベースであり互換性がある
- 事前構成されたライブラリ群を利用してGUIでパイプラインを作成可能
- パイプラインはDataprocで実行される
- パイプラインの中でGCS、BigQueryはもちろん、AWS、Azure、Snowflakeなど外部サービスと連携する事も可能
- Dataform
- DWH内のSQLベースの変換処理の順次実行定義が可能
- Googleのプロダクト以外にもAWS Redshift、Snowflake、Azure SQL Data Warehouseなどに対しても利用することが可能
- Cloud Data Loss Prevention
- 機密性の高いデータを検出、分類、保護するためのフルマネージドサービス
- 個人情報を含むデータを自動検出してマスクすることも可能
- Cloud KMSなどと組み合わせて柔軟な鍵管理を行う事も可能
- Cloud Storage
- 高耐久でスケーラブルなオブジェクトストレージ
- バケット単位でクラス、ライフサイクル、アクセス権限を設定でき、データを層で管理したい場合に有用
- BigQuery
- サーバーレスでスケーラビリティと費用対効果に優れたマルチクラウド データウェアハウス
- ANSI SQL を使用してペタバイト規模のデータを極めて高速に分析可能
- 柔軟性の高いマルチクラウド分析ソリューションで、AWSなどクラウドをまたいだデータによる分析が可能
- また、カラム単位でアクセス制御など細かい単位でアクセス制御を行うことが可能
- Looker
- ビジネス インテリジェンス、データ アプリケーション、組み込み型アナリティクス向けのエンタープライズプラットフォーム
- データへのアクセスポイントを一元化することで保存データ利用におけるガバナンスを利かせることが可能
- Google Cloud、AWS、Azure、オンプレミスのデータベースなど分散されたデータを統合的に管理することも可能
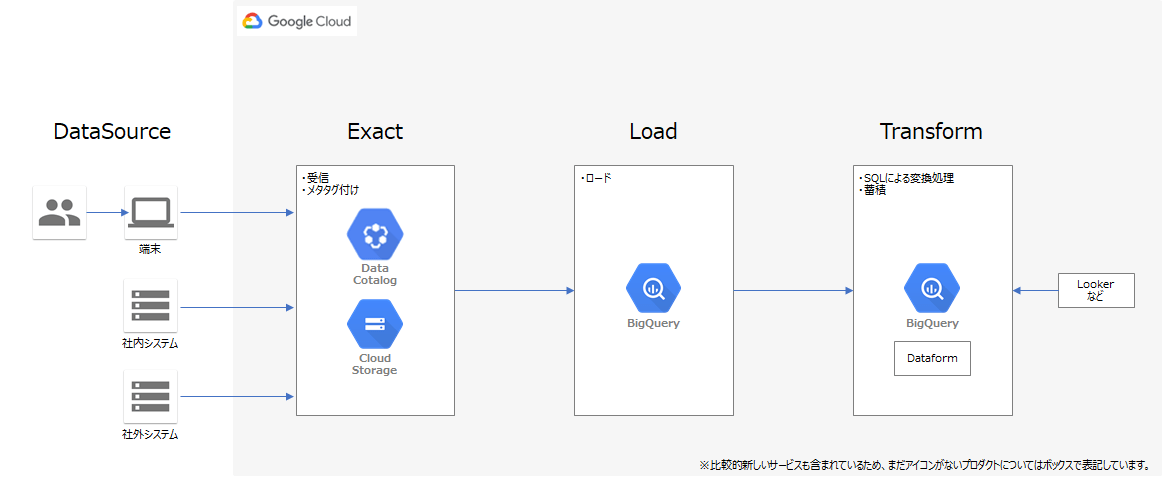
リファレンスアーキテクチャ(ミニマム構成)と構成ポイント
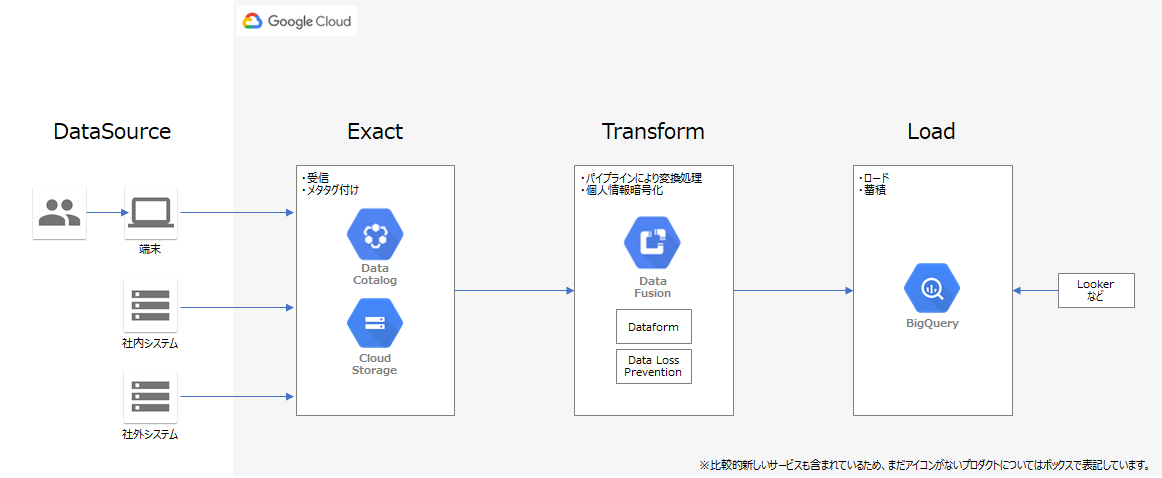
これらのGCPプロダクトを用いたリファレンスアーキテクチャを以下に記載します。
記載するアーキテクチャはミニマム構成となりますので、必要に応じてカスタマイズする事を前提とした構成になります。また、構成のパターンとしては大きくETLモデルとELTモデルに分かれますので状況に応じて使い分けることを想定しています。
ETLモデル
Extract(抽出) Transform(変換) Load(書き出し)を行うモデル。
データ収集後に、各種変換を行ってからデータベースに格納するモデル。
半構造化や非構造化データがある場合に適したモデル。
ELTモデル
Extract(抽出) Load(書き出し)Transform(変換)を行うモデル。
データ収集後に、データベースに格納しデータベース上で各種変換等を行うモデル。
構造化データのみ扱う場合やSQLのみで加工や変換が完結する場合に適したモデル。
さいごに
いかがでしたでしょうか?
GCPを用いると比較的容易にデータレイクの構築ができるので、本来の目的であるデータ活用に重きを置いた検討が出来るのではと思います。今後もデータレイクの構成要素(データ収集、データ管理、データセキュリティ、データ利用)毎に、より詳細な部分を記事化していければと考えています(不定期)
特にボトムアップ的なアプローチとなる場合は、泥沼化させずにどうデータを運用管理していくか? といった部分が非常に重要になってきますのでそのようなポイントに触れるような感じで記事化できればと思っています。
参考資料
[Google資料]
- データレイクのモダナイゼーション
- データレイクとしてのCloud Storage
- Google Cloud スマート アナリティクス ソリューションでイノベーションを促進する
- Principles and best practices for data governance in the world
- Cloud Storage
- Data Catalog
- Cloud Data Fusion
- Cloud Data Loss Prevention
- BigQuery
- Looker
- Dataform
以下は参照するためにユーザー登録が必要なります。
- Google Cloud Smart Analytics ソリューションの方向性と最新アップデート情報
- GCP のデータパイプライン サービスの紹介と選び方
- Google Cloudでデータレイクを構築
[その他資料]