はじめに
フューチャーの棚井龍之介です。
業務ではDynamoDBを利用しており、連日DynamoDBコンソール画面と睨めっこをしています。DynamoDBのコンソール画面は特定のデータをピンポイントで探すには優秀ですが、データ集計には全く向いていません。
そのため、統計調査や障害調査などによりデータ分析が必要になった場合、毎度awscliコマンドとbashコマンドのコラボレーションで試行錯誤しながら集計することになります。
DynamoDBでのデータ検索は原則「スキャンとクエリ」のみです。SQLのWHERE句に似たfilterという機能はありますが、テーブル同士のJOINや複雑な条件絞り込みは難しいため「SQLが打てれば一瞬で解決できるのに、どうしてこんな面倒なんだ。これが低レイテンシの代償なのか」と考えていました。
何度もデータ集計をして、「aws dynamodb xx yy zz ~~」の職人芸を繰り出すことや、一度きりの集計でしか使えないスクリプトを量産しているうちに、もっと楽で正確で作業コストの低い方法はないか? と思う機会が増えてきました。
AWS News Blog からの福音
New – Export Amazon DynamoDB Table Data to Your Data Lake in Amazon S3, No Code Writing Required
なんと、DynamoDBのテーブルデータを、追加コードなしでパッとS3に出力できるようになりました!
PipelineやGlueを利用したS3出力ならば以前から可能でしたが、より低コストでDynamoDB → S3へのデータ出力が可能となりました。
「S3にExportできる → GlueのデータカタログとAthenaのクエリ機能により、サーバレス環境でSQLを実行できる」の連想ゲームなので、動作検証も兼ねて早速試してみました。
本記事の流れ
DynamoDBのデータにSQLを実行するため、本記事では以下の流れで説明します。
1.DynamoDBを準備
Export S3の機能は新しいコンソール画面上でのみ可能なので、古いUIを利用している場合は「新しいコンソールを試す」を選択してください。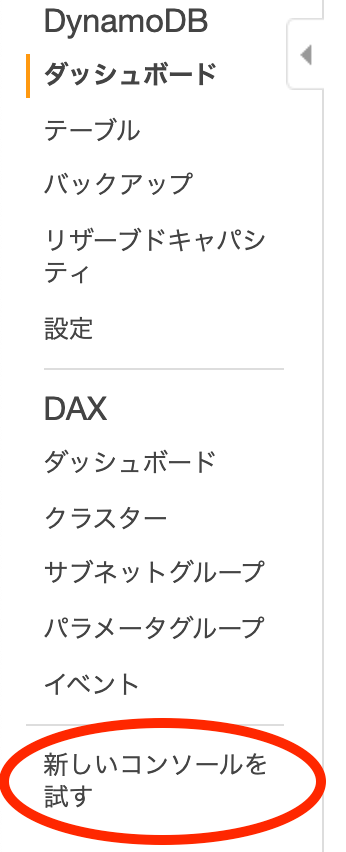
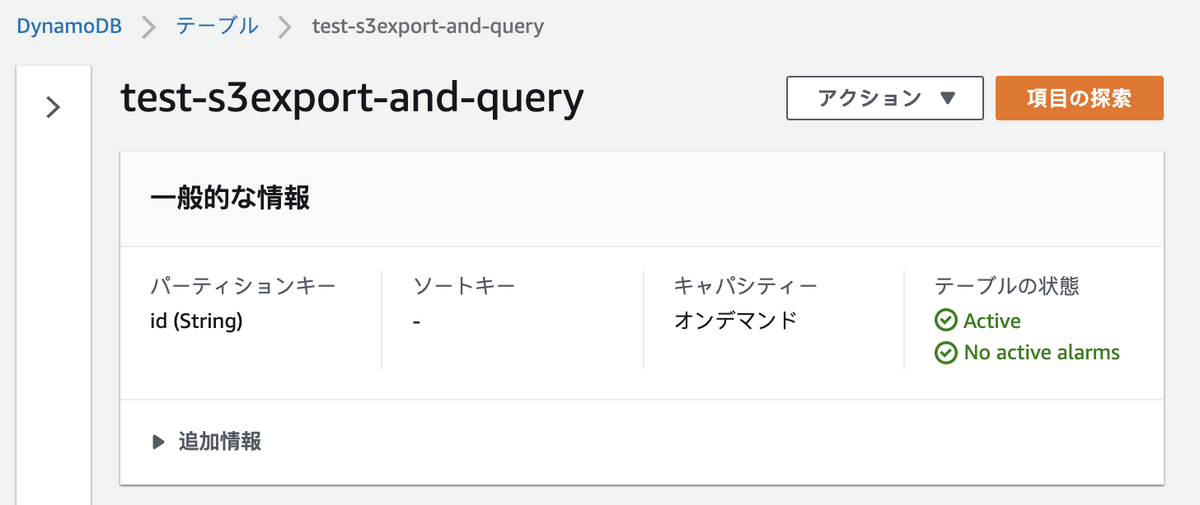
今回の動作検証用に、以下の設定でDynamoDBテーブルを作成します。
- テーブル名: test-s3export-and-query
- パーティションキー: id(String)
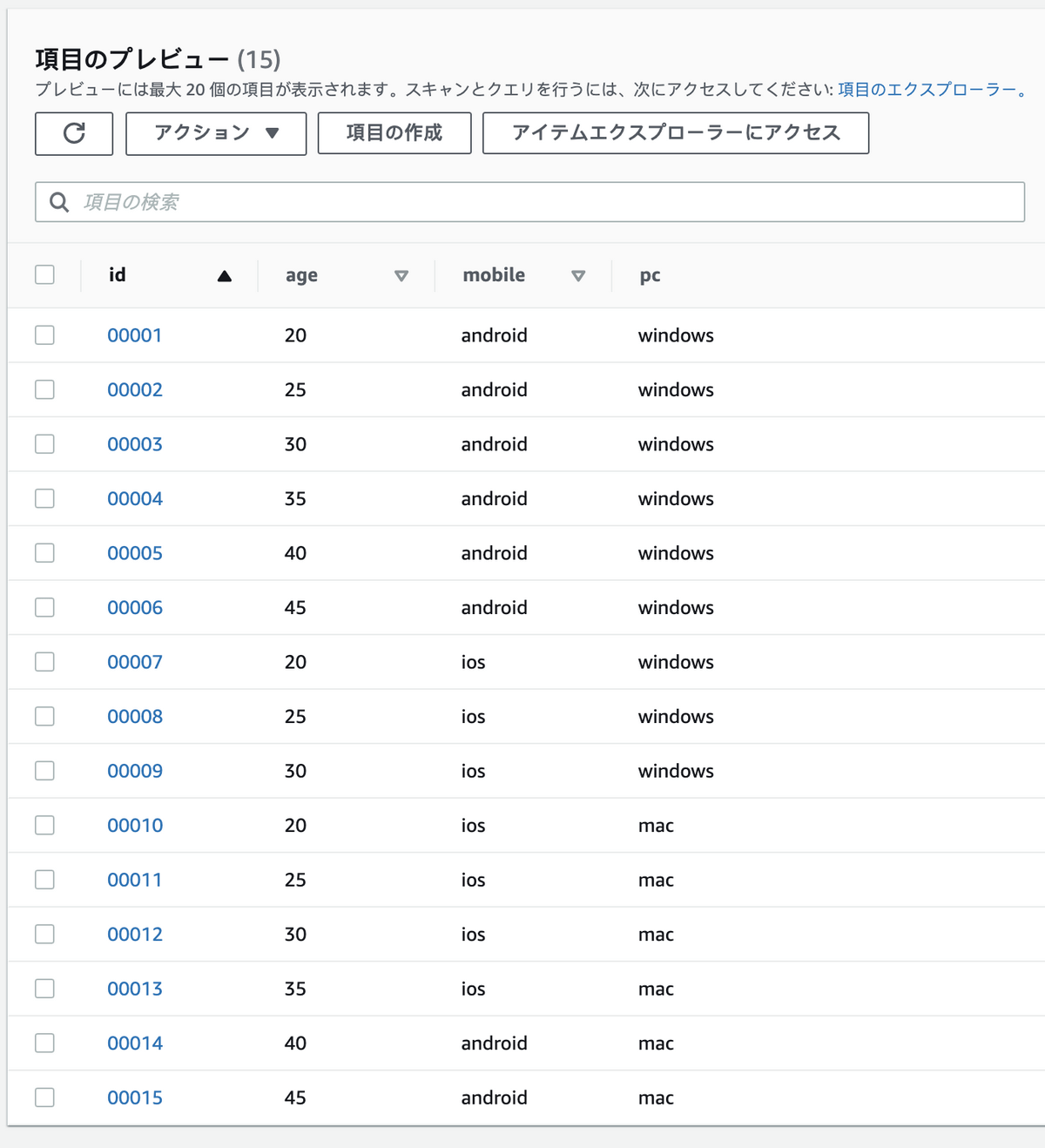
動作検証用に、サンプルデータを15件投入します。
{"id":{"S":"00001"},"age":{"N":"20"},"pc":{"S":"windows"},"mobile":{"S":"android"}} |
投入結果をコンソール画面で確認します。
15件とも正しく格納されています。
2.Export先のS3を準備
データ出力先のS3を作成します。
今回は test-dynamodb-export-20210315 のバケット名で作成しました。
3.Exportを実行
テーブルのExportでは、DynamoDBの読み込みキャパシティーユニットが消費されません。よってDBのパフォーマンスには影響を与えずにデータを出力できます。ただし、Export実行のタイミングとトランザクションのタイミングが重なった場合、出力項目が最新のテーブルとはズレが生じる可能性があります。本機能は「DynamoDBの特定の断面をS3にExportすることが目的」なため、リアルタイムなデータ分析には適していない点にご注意ください。
DynamoDBのコンソール画面上から、Export S3を実行します。
「ストリームとエクスポート」から「S3へのエクスポート」を選択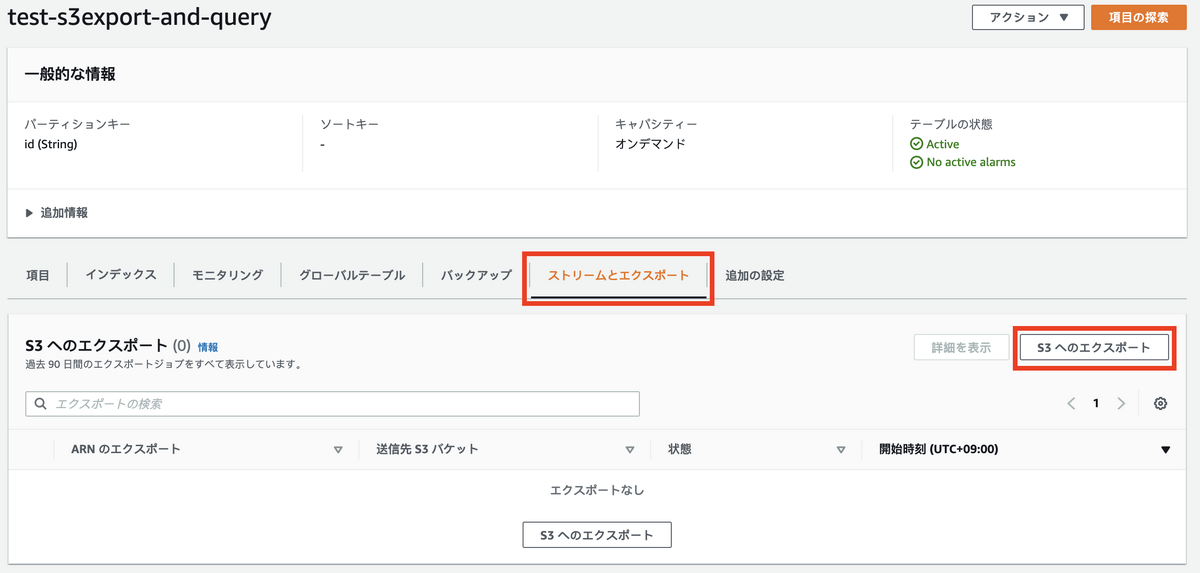
Export S3の実行には Point-in-Time Recovery の設定が必要なため、画面の指示に従い有効化します。
出力先のS3を選択したら、「エクスポート」を実行します。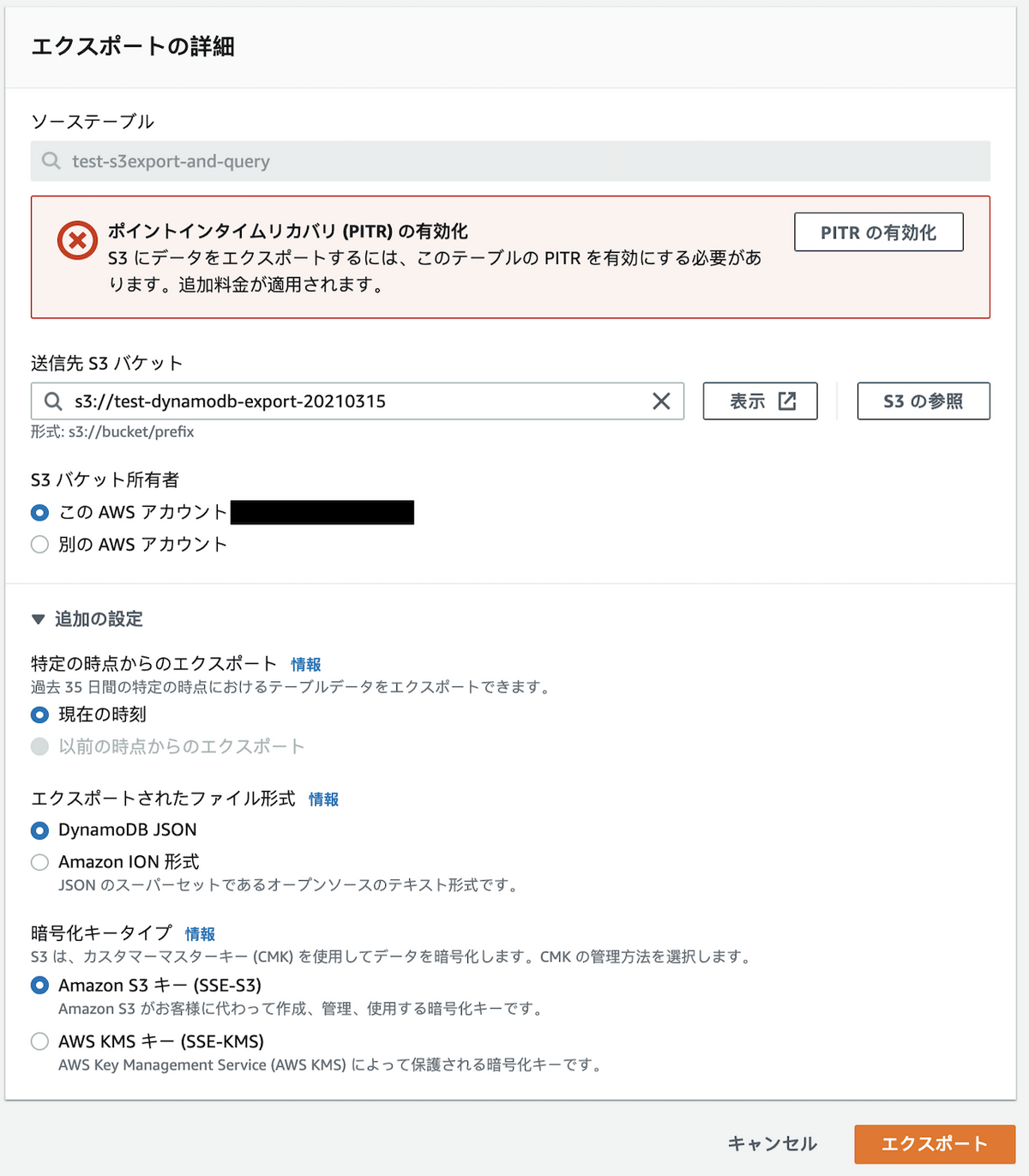
コンソール画面上でExportの進行状況が見れます。
データ数にもよりますが、出力は5分程度で完了します。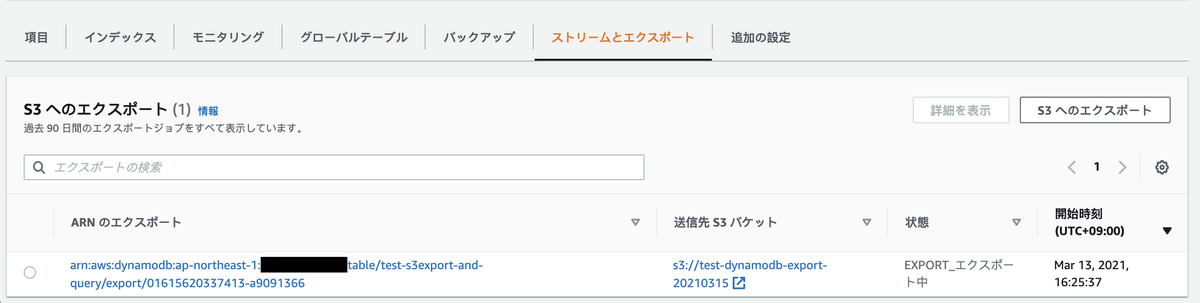
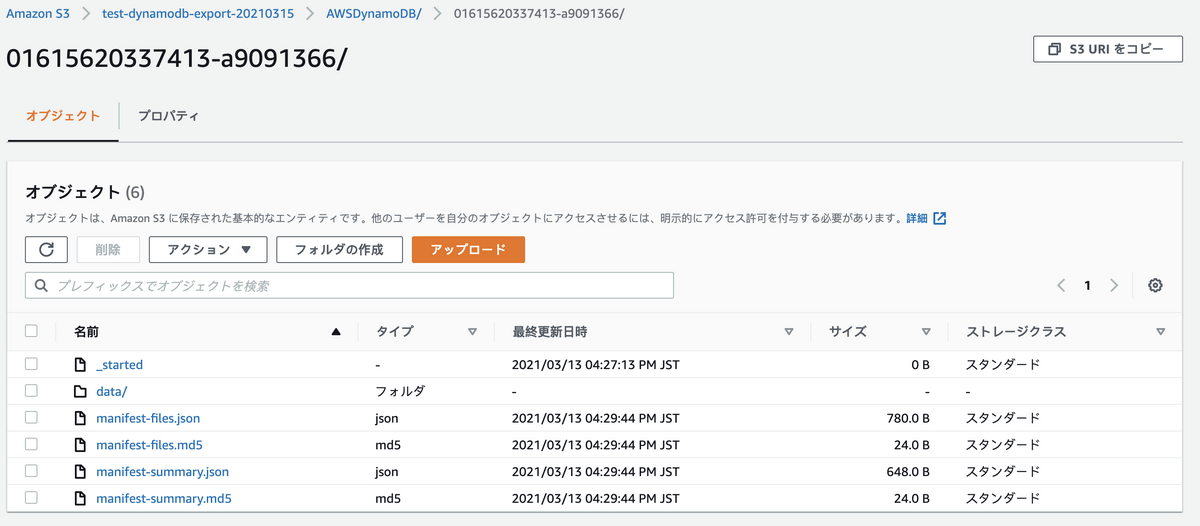
Export完了後に出力先S3を確認すると、DyanmoDBデータ本体以外にも複数ファイルが確認できます。
各ファイルの意味はこちらです
| オブジェクト | 説明 |
|———————– |—————————————————————- |
| _started | ターゲットs3パスへの疎通確認に利用されたもの。削除して問題ない |
| data/ | 出力したデータ本体。テーブル項目がgz形式に圧縮されて出力される |
| manifest-files.json | Exportされたファイルの情報が記載される |
| manifest-files.md5 | manifest-files.jsonのチェックサムファイル |
| manifest-summary.json | Exportジョブの概要情報が記載される |
| manifest-summary.md5 | manifest-summary.jsonのチェックサムファイル |
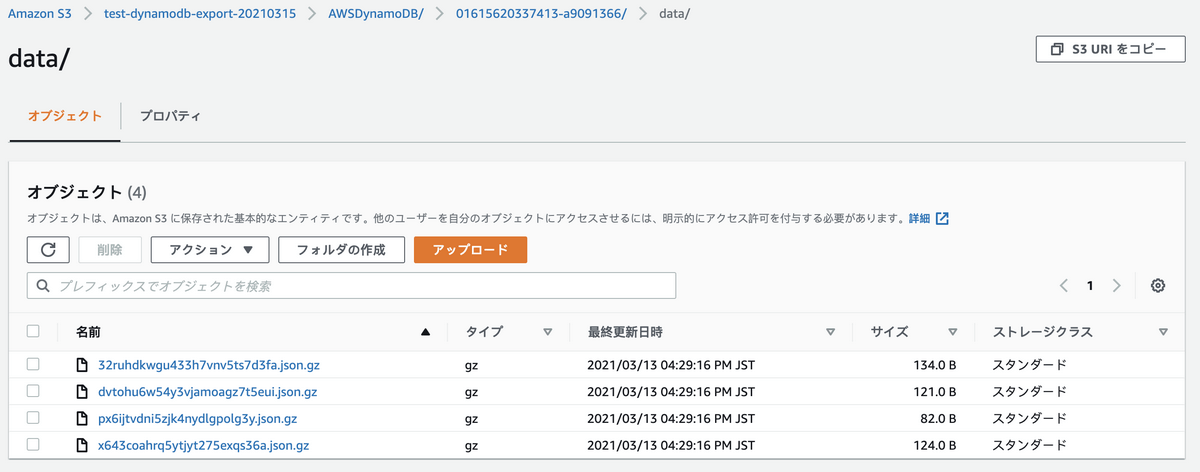
dataパス配下に、ExportしたDynamoDBテーブルデータがgz形式で格納されています。
以上で、DynamoDBのExport S3は完了しました。
コンソール画面をいくつか操作するだけで、DynamoDB→S3へのデータ出力が完了です。
4.GlueのCrawlerを実行
Athenaでのクエリ実行には、事前のテーブル定義が必要です。
各項目ごとに手動追加することも可能ですが、作業簡略化のために今回はGlueのCrawler機能をを利用します。
まずは、Glueデータカタログの「データベース」→「データベースの追加」を選択し、Crawler結果を格納するデータベースを追加してください。
今回は test_dynamodb_export の名前でデータベースを追加しました。
続いて、「テーブル」→「テーブルの追加」→「クローラを使用してテーブルを追加」を選択します。
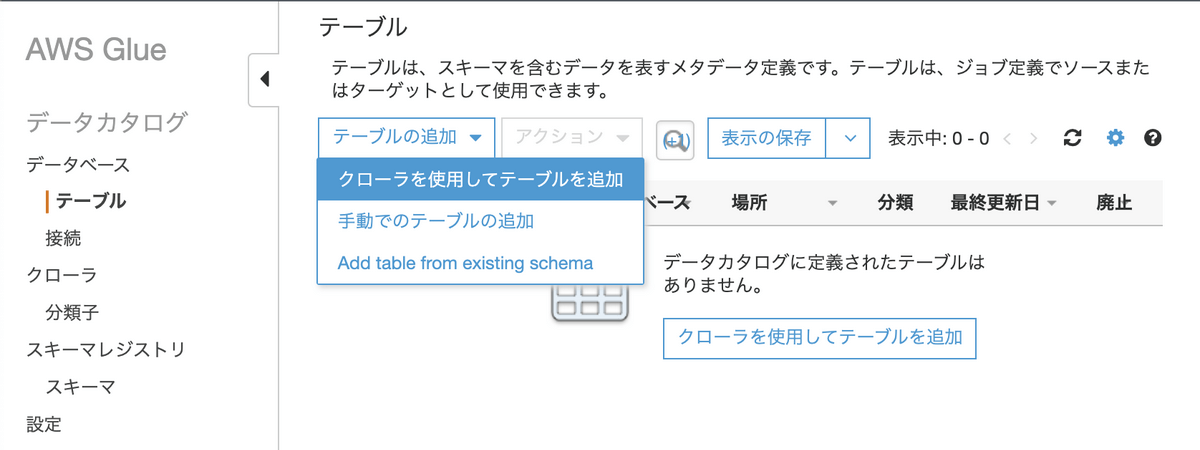
今回のクローラでは、以下の設定とします。
- 名前: test-dynamodb-export
- インクルードパス: s3パス(DynamoDBデータのExport先のパス, ~/data/ までを指定する)
- スケジュール: オンデマンド
- データベース: test_dynamodb_export
- テーブルに追加されたプレフィックス: users_ (“プレフィックスでの指定文字列+data”が、テーブル名となる)
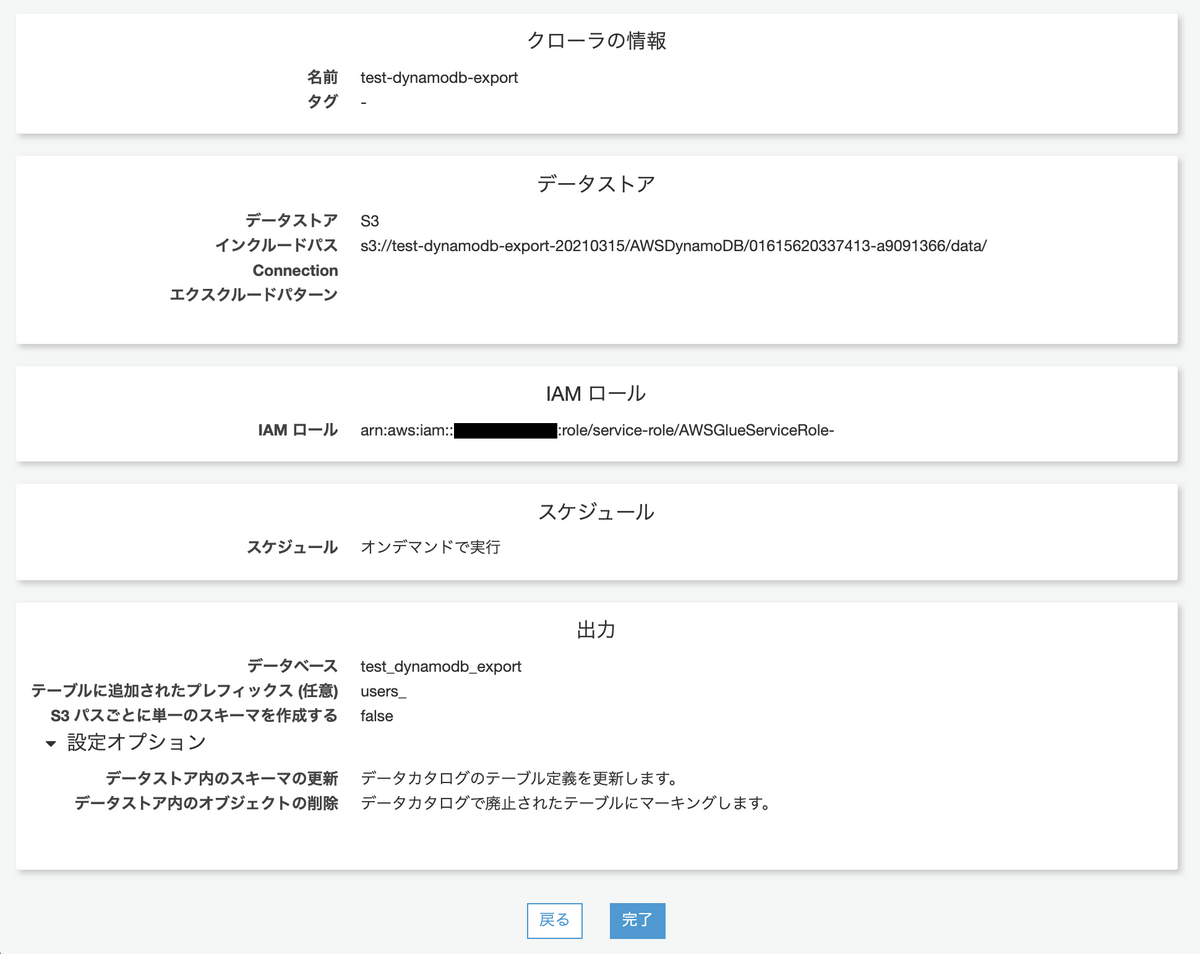
クローラの実行をオンデマンドに設定したため、「クローラ」→「test-dynamodb-export(今回追加したクローラ名)」→「クローラの実行」により、テーブル定義を追加します。

1,2分程度でクローラ実行が完了します。
以上により、DynamoDBのデータをS3に格納して「クエリが実行できる状態」になりました。
5.AthenaでSQLを実行
Athenコンソール画面での「データベース」で「test_dynamodb_export(今回追加したデータベース)」を選択し、テーブルに「users_data」が表示されることを確認します。
Glue Crawlerにより項目定義は完了しているため、あとはSQLを実行するのみです。
まずは SELECT してみましょう。
DynamoDBの出力項目をGlue Crawlerでテーブル定義した場合、各項目は「**Item.(項目名).(データ型)**」で指定できます。
SELECT Item.id.S AS id, |
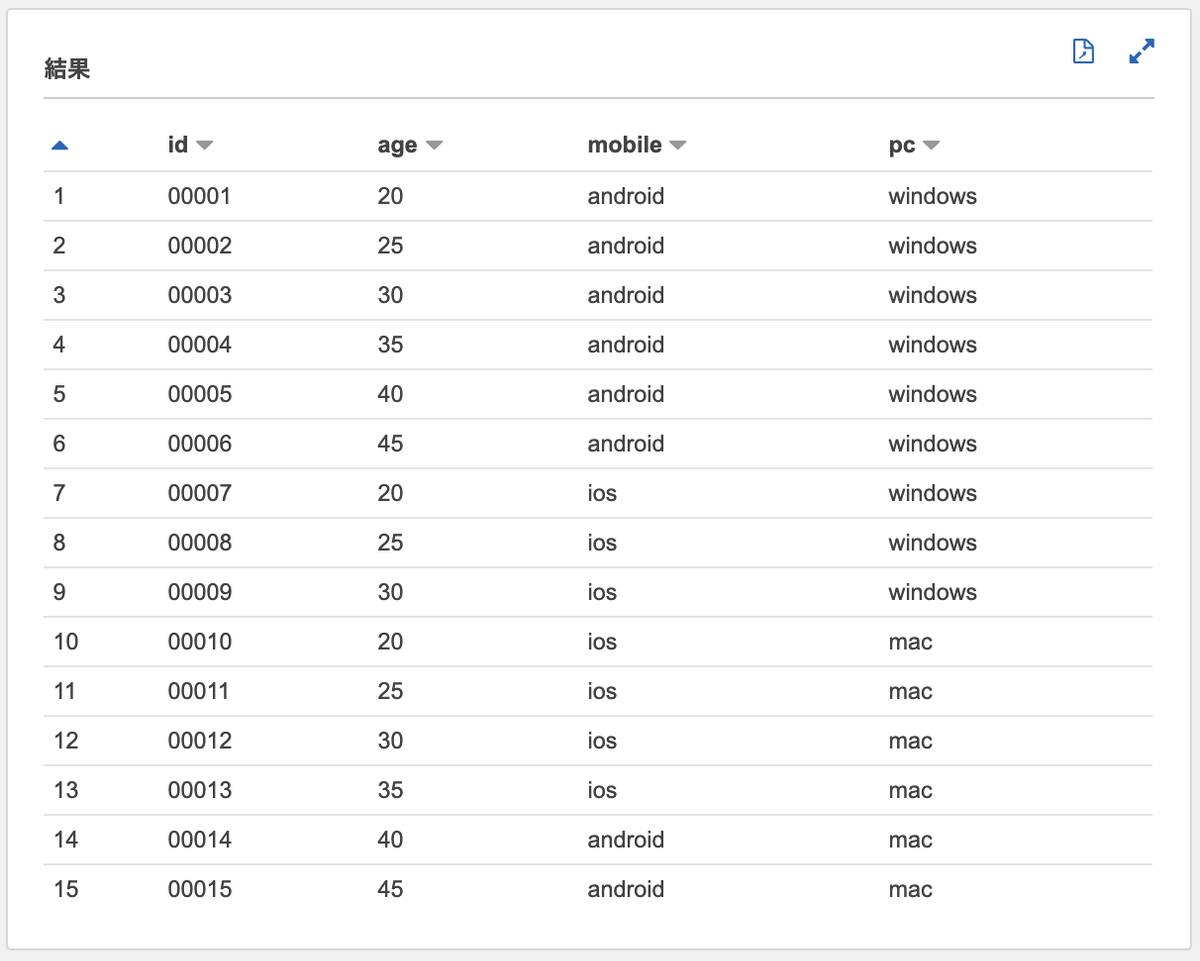
DynamoDBをSELECTできましたね。
SQLっぽく、いくつか条件を追加してみます。
SELECT Item.id.S AS "35歳以下のiOSユーザ", |
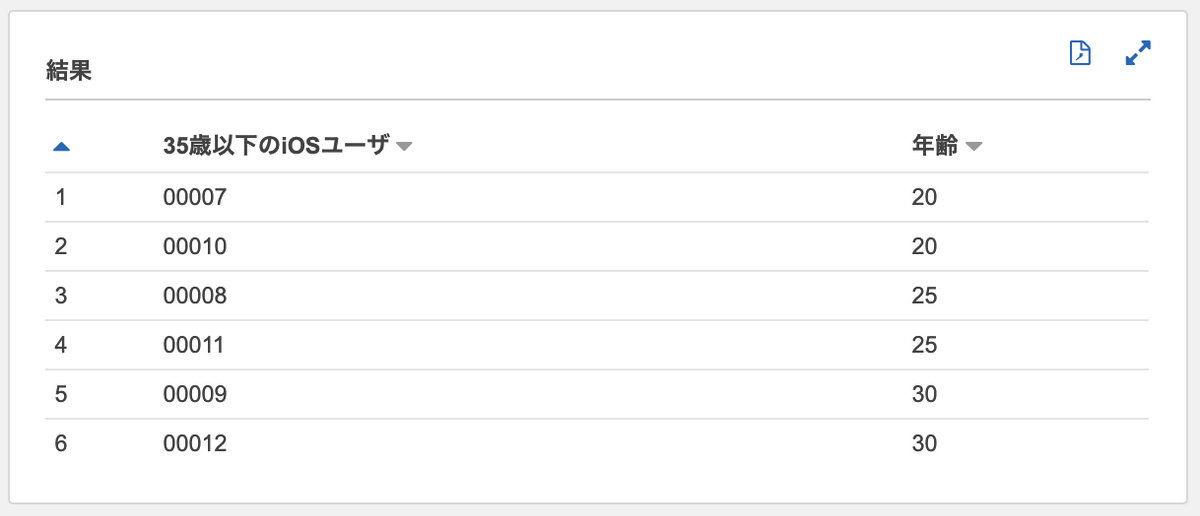
テーブルのJOINも、もちろんできます。
SELECT count(1) AS "15×15=225" |
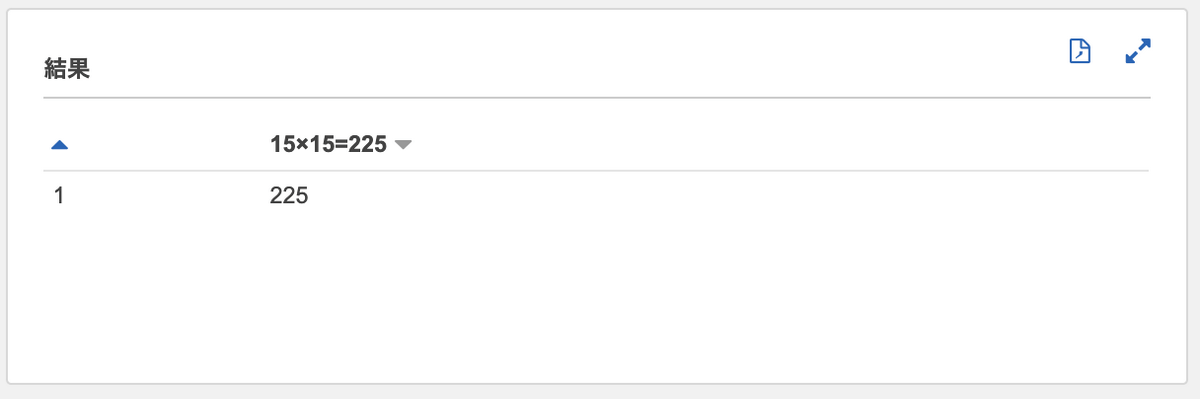
今回の記事では1テーブルしか作成していませんが、各テーブルごとに Export S3 + Glue Crawler を実施すれば、DynamoDBテーブル同士のJOINが可能となります。
まとめ
DynamoDBのS3 Export機能が搭載されたことにより、データ集計コストが下がりました。既存のGlueとAthenaを利用することで、「SQL分析に手間がかかる」というDynamoDBの弱点が一部解消されたと考えています。今回の構成ではリアルタイムなデータ分析は不可能ですが、過去データを特定の断面で集計するには十分です。
みなさんもDynamoDB集計に疲弊されていたら、是非とも DynamoDB Export S3 を使ってみてください!