アルゴリズムとデータ構造連載の4日目です。
データ構造とアルゴリズムはどちらかというと独立した存在(どちらも大事)っぽく語られることが多いと思いますが、一方で、特定のアルゴリズムと組み合わせるスペシャルなデータ構造というものがあります。例えば、次の二分探索に特化して、配列の並び替えをすることで、2分探索を早くする(CPUのキャッシュに乗せやすくする)、というものとかがあります。
そのような、探索やカウントなどの特定アルゴリズムに特化しつつ、なおかつ情報理論的下限まで使用メモリを抑え、圧縮したまま利用できるようにしたデータ構造を簡潔データ構造(succinct data structure)と呼びます。新しめの研究分野かつ、日本での研究が活発らしいです。本も何冊も出ています(といっても、僕は論文をあまり読まないので詳しくはないですが)。



基本のデータ構造のビットベクトル、ウェーブレット木などの木構造などがあり、それを使った例もいろいろです。圧縮したまま検索できるということで、巨大なゲノムデータをコンピュータで扱ったり、日本語入力の大量の辞書を組み込みながらも使用メモリを減らす、といった応用例があります。全文データを定数時間で直接スキャンする(FM-index)こともでき、それを使ったブラウザで動く検索エンジンを作ったりしました。
今回は木構造のLOUDSを扱ってみようと思います。本当は自分で実装するところからやりたかったのですが、今回は次のライブラリを使ってみます。理論的なところは抜いて、まずは使ってみます。
LOUDS
LOUDSというのを調べると出てくるのはこんな図です。正確にはTRIEという木構造がこれで、これの簡潔データ構造的表現がLOUDS、みたいな関係です。格納するのは単語のリストです。この木にはto、tea、ted、ten、A、in、innの6個の単語が登録されています。
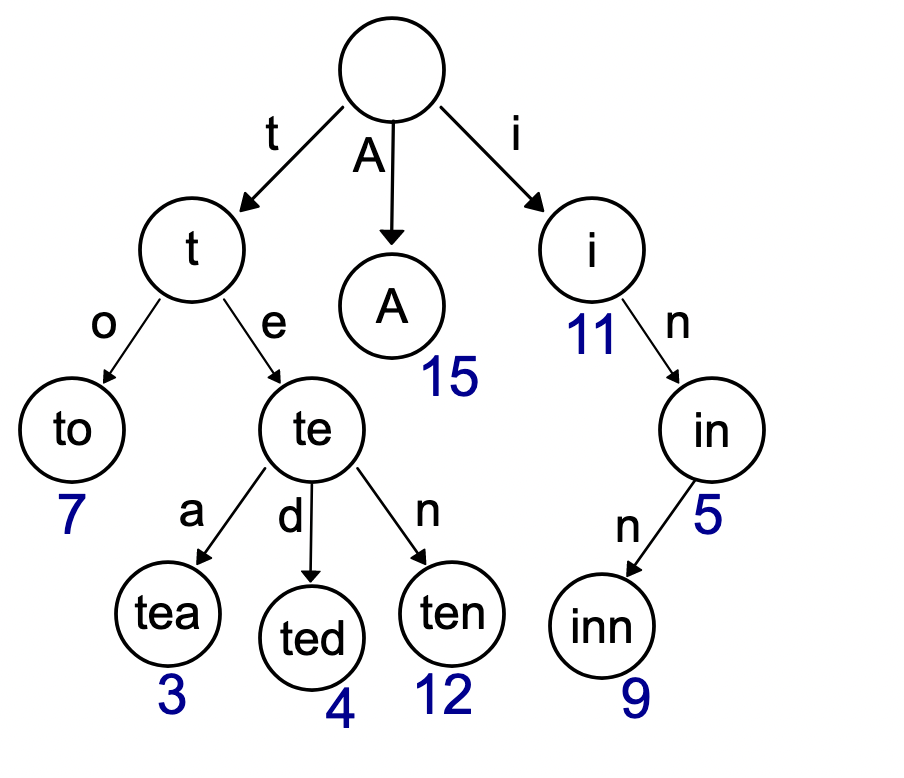
図はWikipediaのTrieから引用
探索した単語を調べると、ノードのIDの数値が出てきます。単語のリストをmap(Goでは、他の言語では辞書と呼んだりhashと呼んだり)でキーを単語に、ノードIDを値に持つのと似ています。ちょびっと違うのは以下の3点
- 共通部分をまとめて、差分だけを子供に持つ、みたいな感じでデータ量を減らしています。
- 単語のノードの親を見つけることができる(mapだと全捜査が必要)
- ノードの子供をまとめて取って来れる
共通部分が多いツリーであれば効果が高いということですね。
実際に試してみる
GoではLOUDSを実装しているライブラリはGitHubでは3つだけありました。そのうち、mainパッケージに全部入れているようなやつではなく、ライセンスが明記されているものは次のライブラリだけでした。
文字列の共通部分が比較的多く出てくるものといえば住所データかな、ということで、政府CIOポータルを探して、総務省の標準地域コードが良さそうなのでこのCSVを落としてきました。コードをシンプルにするためにShiftJISはあらかじめUTF-8にして、先頭のヘッダー行は抜いておきます。
データはこんな感じになっています。
ken-code,sityouson-code,tiiki-code,ken-name,sityouson-name1,sityouson-name2,sityouson-name3,yomigana |
LOUDS木を作って探索する
LOUDS木を作るコードは次の通りです。文字列のスライスを作り、それをNewTrie()に渡すだけです。
f, err := os.Open("code.csv") |
NewTrie()で作ったインスタンスにいろいろなメソッドがあります。
MarshalBinary()で[]byteに書き出せますし、NewTrieFromBinary()で[]byteから再構築ができます。高速ロードができますね。なお、130KBほどの元データでしたが、漢字の自治体名部分だけ取り出し(体感でデータ量の半数超)てLOUDSを作ったところ、32KBでした。NewTrieの2番目のデータ圧縮オプションを有効にすると25KBまで減りますが、キーを復元できなくなるので用途に応じてオンにするといいでしょう。
基本的に、探索するとIDが出てくるので、必要に応じてIDからキーを復元する、といった使い方になります。なお、IDは最初に投入したスライスのインデックスとは異なります。
探索メソッドは3つありました。
// 正確に一致 |
漢字名をキーに、読みを検索できるようにする
内部的なノードIDがわかってもうれしくないでしょう。読みを検索できるようにします。やり方は単純で、ノードのIDを配列のインデックスと見立てて、読みが入ったスライスから取り出してくるだけです。漢字を見てノードIDを調べたら、そのIDのインデックスに、読みデータの文字列を入れます。
var names []string |
LOUDS情報を作るときはmapも駆使して優雅にメモリを使いますが、実行環境ではスライスのインデックスアクセスのみ、というストイックな実装になっています。
検索は2段階で行います。
// 読みを調べる |
読み側もLOUDSにしてみる
せっかくなので読み側のデータもLOUDSにしてみます。2つのLOUDSのインデックスの対応表をスライスにします。ちなみに、データ量は30KBでした。
var names []string |
今回は調べるのは3ステップです。
// 読みを調べる |
無事出ましたね。ノードのIDをキーとするスライスを用意して有効なデータをそこから取り出せるようにすれば、メタデータやその他の有用なデータをたくさん格納できますね。
まとめ
LOUDSとか簡潔データ構造は調べると数式とかが多くてどうやって使うのか、みたいな情報があまりなさそうなので、あえて深入りせずにライブラリの利用方法に限定して調べました。
メモリ効率よくデータを格納できてそのまま取り出せるというのが簡潔データ構造の魅力です。個人的には値の変更がないマスタデータなんかは、RedisやRDBや共通サービスに持たせるのではなく、こういうデータにして各サービスに配ってしまう、というのも面白いんじゃないかなと思っています。マイクロサービスを真面目に正規化して設計すると依存関係が深くなって大変になったりしますが、それを適度に非正規化するための道具として使えそうかなって。
Goの場合(Go以外でも)なかなかライブラリ数が少なく、POPCNTという、インテルやARMのSIMD命令を使った効率の良いビットベクター実装とかもあまりないのが実情。まだまだみなさんの目の前のPCのポテンシャルが眠らされている、という感じがします。僕が簡潔データ構造に夢を持つのはそのあたりです。
まあ、自力で実装しても元が取れるぐらい業務利用用途があるかというと、まだ見つけられていないのが実情です。定年したら、盆栽をいじるみたいな感じで簡潔データ構造のコードをぽちぽち実装する、みたいなのが将来の夢です。