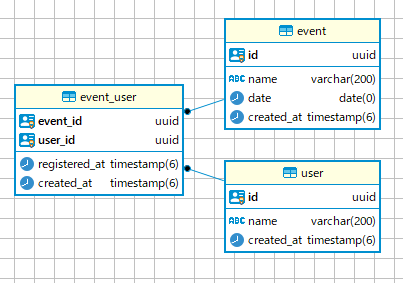
create table "user" ( "id" uuid not nulldefault gen_random_uuid() , "name" varchar(200) not null , "created_at" timestampnot nulldefault now() ); alter table "user" addprimary key ("id");
create table "event" ( "id" uuid not nulldefault gen_random_uuid() , "name" varchar(200) not null , "date" datenot null , "created_at" timestampnot nulldefault now() ); alter table "event" addprimary key ("id");
create table "event_user" ( "event_id" uuid not null , "user_id" uuid not null , "registered_at" timestampnot nulldefault now() , "created_at" timestampnot nulldefault now() ); alter table "event_user" addprimary key ("event_id", "user_id"); alter table "event_user" addforeign key ("event_id") references "event" ("id"); alter table "event_user" addforeign key ("user_id") references "user" ("id");
シンプルなINSERT, SELECT
まずはユーザ作成処理を考えます。 先にコードを掲載します。
funcCreateUser(ctx context.Context, b []byte) (*boiler.User, error) { u := &boiler.User{} if err := json.Unmarshal(b, u); err != nil { returnnil, err } err := u.Insert(ctx, db, boil.Infer()) if err != nil { returnnil, err } return u, err }
boiler.User は、SQLBoilerによって生成された user テーブルに対応するStructです。 カラムに設定したコメントが反映されているのが地味に便利なポイントです。
// User is an object representing the database table. type User struct { ID string`boil:"id" json:"id" toml:"id" yaml:"id"` // 所属する組織ID OrganizationID string`boil:"organization_id" json:"organizationID" toml:"organizationID" yaml:"organizationID"` // ユーザ名 Name string`boil:"name" json:"name" toml:"name" yaml:"name"` CreatedAt time.Time `boil:"created_at" json:"-" toml:"-" yaml:"-"`
R *userR `boil:"-" json:"-" toml:"-" yaml:"-"` L userL `boil:"-" json:"-" toml:"-" yaml:"-"` }
SELECT*FROM event ORDERBYdatedesc; SELECT*FROM event_user WHERE (event_user.event_id IN ($1)); SELECT*FROMuserWHERE (user.id IN ($1,$2));
集計を含むSELECT
参加者数の多いイベントを取得する処理を考えます。
SQLは次の通りです。
select event.*, coalesce(r1.participants, 0) as participants from event leftjoin ( select event_id as id, count(*) as participants from event_user groupby event_id orderby participants desc limit 10 ) r1 on event.id = r1.id orderby participants desc
ここまで来るとクエリビルダに頭を悩ませるのも大変なので、SQLをそのまま実行させます。
type EventPopularity struct { boiler.Event `boil:",bind"` Participants int`boil:"participants" json:"participants"` }
funcListPopularEvents(ctx context.Context) ([]*EventPopularity, error) { r := []*EventPopularity{} queries.Raw(` select event.*, coalesce(r1.participants, 0) as participants from event left join ( select event_id as id, count(*) as participants from event_user group by event_id order by participants desc limit 10 ) r1 on event.id = r1.id order by participants desc `).Bind(ctx, db, &r) return r, nil }