ライブリッツの筒井です。
GoのORマッパー連載 、折り返して5日目です。
SQLBoilerを使用したDBスキーマ駆動なREST APIサーバの開発ワークフローを紹介します。
なぜSQLBoilerを選ぶのか? 自分たちのチームでは、REST APIサーバを開発する際にはまずデータベースのテーブル設計から始めることが多いです。その次にAPI定義の設計へ入るのですが、既にテーブル定義は出来上がっているため、なんとなくSQL文が頭に思い浮かんだ状態 でAPIのRequest / Responseを考えることになります。
ゆえにO/Rマッパに一番に求めるのは、「いかにストレスなく思い描いていたSQL文を実行し、Goの文脈に持ち込めるか 」ということです。
この基準を元に、次のような観点からSQLBoilerを選定しています。
複雑なSELECT文でDSLに苦悩したくない 前述の通り、我々の頭の中にはなんとなくのSELECT文が既に浮かんでいます。このSELECT文を組み立てるために、O/Rマッパ特有のDSLに悪戦苦闘することは避けたいものです。
SQLBoilerのクエリビルダはSQLの基本的な構文と大きく違わないため、直感的に使用できました。またGoのコードが生成されているため、カラム名、テーブル名を指定する際にコード補完が効くのも嬉しいポイントです。
相関サブクエリを使った集計などはクエリ相当複雑になってしまいますが、Raw SQLの実行、StructへのBindも容易なので、「複雑なクエリはSQLをそのまま実行」というアプローチが取れます。
(これについては jmoiron/sqlx も同様です)
INSERT, UPDATE, DELETEはSQLを書きたくない SELECT文が複雑になることは多々ありますが、INSERT, UPDATE, DELETEはそうでもありません。
これらのDMLはO/Rマッパに乗っかり、Type Safeに書きたいところです。
SQLBoilerでは、INSERT, UPDATE, DELETEはStructのメソッドとしてコードが生成されます。JSONからUnmarshalしてInsertといった処理が簡単に書けます。
Schema Migrationはいらない これには「データベースの寿命 > アプリケーションの寿命」という前提があります。
Migration機能も含め、データベースをアプリケーションからは独立した1サービスとして扱う、という考え方をとっています。
一方「データベースの寿命 == アプリケーションの寿命」とできる場合は、ActiveRecordのようにデータベースをアプリケーションの1機能として扱えたほうが開発効率は上がるでしょう。
SQLBoilerにはSchema Migration機能は含まれておらず、既存のデータベースからコードを生成するアプローチを取っています。
別ツール (Flyway を使うことが多いです) でSchemaを管理している自分たちにはピッタリでした。
SQLBoilerの使い方 プロジェクトのセットアップについては公式ドキュメント に詳しいため割愛します。
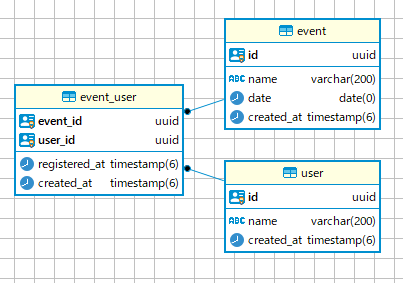
テーブル定義 今回使用するテーブル定義です。1 : 0...N の関係です。
create table "user" ( "id" uuid not null default gen_random_uuid() , "name" varchar (200 ) not null , "created_at" timestamp not null default now() ); alter table "user" add primary key ("id");create table "event" ( "id" uuid not null default gen_random_uuid() , "name" varchar (200 ) not null , "date" date not null , "created_at" timestamp not null default now() ); alter table "event" add primary key ("id");create table "event_user" ( "event_id" uuid not null , "user_id" uuid not null , "registered_at" timestamp not null default now() , "created_at" timestamp not null default now() ); alter table "event_user" add primary key ("event_id", "user_id");alter table "event_user" add foreign key ("event_id") references "event" ("id");alter table "event_user" add foreign key ("user_id") references "user" ("id");
シンプルなINSERT, SELECT まずはユーザ作成処理を考えます。
func CreateUser (ctx context.Context, b []byte ) error ) { u := &boiler.User{} if err := json.Unmarshal(b, u); err != nil { return nil , err } err := u.Insert(ctx, db, boil.Infer()) if err != nil { return nil , err } return u, err }
boiler.User は、SQLBoilerによって生成された user テーブルに対応するStructです。
type User struct { ID string `boil:"id" json:"id" toml:"id" yaml:"id"` OrganizationID string `boil:"organization_id" json:"organizationID" toml:"organizationID" yaml:"organizationID"` Name string `boil:"name" json:"name" toml:"name" yaml:"name"` CreatedAt time.Time `boil:"created_at" json:"-" toml:"-" yaml:"-"` R *userR `boil:"-" json:"-" toml:"-" yaml:"-"` L userL `boil:"-" json:"-" toml:"-" yaml:"-"` }
実行結果は次の通りです。
func TestCreateUser (t *testing.T) testConfigureDatabase(t) d := `{"organizationID":"00000001-0000-0000-0000-000000000000","name":"Emmett Brown"}` got, err := CreateUser(context.TODO(), []byte (d)) if err != nil { t.Errorf("CreateUser() error = %v" , err) return } logJson(t, got) }
{ "id" : "54629dbd-2c32-4e71-8592-be66be0a5385" , "organizationID" : "00000001-0000-0000-0000-000000000000" , "name" : "Emmett Brown" }
次にユーザ一覧を取得する処理を考えます。
select * from user where organization_id = $1
Goのコードは次の通りです。
var db * sql.DB func ListUsers(ctx context.Context, orgID string) ([]* boiler.User, error) { users, err := boiler.Users( qm.Where("organization_id = ?", orgID), ).All (ctx, db) if err != nil { return nil, err } if users = = nil { users = []* boiler.User{} } return users, nil }
この程度のシンプルなクエリであれば自動生成コードで簡単に実装可能です。
実行結果は次のようになります。json タグもSQLBoilerが付けてくれているので、サクッとSerializeが可能です。
func TestListUsers (t *testing.T) testConfigureDatabase(t) orgID := "00000001-0000-0000-0000-000000000000" got, err := ListUsers(context.TODO(), orgID) if err != nil { t.Errorf("ListUsers() error = %v" , err) return } logJson(t, got) }
[ { "id" : "00000001-0001-0000-0000-000000000000" , "organizationID" : "00000001-0000-0000-0000-000000000000" , "name" : "ユーザ01" } , { "id" : "00000001-0002-0000-0000-000000000000" , "organizationID" : "00000001-0000-0000-0000-000000000000" , "name" : "ユーザ02" } ]
中間テーブルのJOINを含むSELECT イベントとその主催者ユーザ、参加者ユーザ一覧を取得する処理を考えます。
SQLで書くならば次のようになるでしょう。
select "event".* , "participant".* from "event"left join "event_user" r1 on r1.event_id = event.idleft join "user" participant on participant.id = r1.user_id
SQLBoilerで実装する場合、Eager Loadingによって結合先テーブルを読み込む形になります。Eager Loadingのコードも、SQLBoilerが外部キー制約を読み取って自動生成してくれています。
クエリ時に qm.Load() で結合先テーブルを読み込んでおけば、FromTable.R.JoinTable の形式でGoからアクセス可能です。
JoinのJoinも、ドット区切りで結合先テーブルを記述すると読み込み可能です。
type Event struct { *boiler.Event ParticipantUsers []*boiler.User `json:"participantUsers"` } func ListEvents (ctx context.Context) error ) { es, err := boiler.Events( qm.OrderBy(boiler.EventColumns.Date+" desc" ), qm.Load(fmt.Sprintf("%s.%s" , boiler.EventRels.EventUsers, boiler.EventUserRels.User)), ).All(ctx, db) if err != nil { return nil , err } res := make ([]*Event, len (es)) for i, e := range es { ps := make ([]*boiler.User, len (e.R.EventUsers)) for j, u := range e.R.EventUsers { ps[j] = u.R.User } res[i] = &Event{ Event: e, ParticipantUsers: ps, } } return res, nil }
実行結果は次の通りです。
[ { "id" : "00000000-0000-0000-0000-000000000001" , "name" : "イベント01" , "date" : "2015-10-21T00:00:00Z" , "participants" : [ { "id" : "00000001-0002-0000-0000-000000000000" , "organizationID" : "00000001-0000-0000-0000-000000000000" , "name" : "ユーザ02" } , { "id" : "00000001-0003-0000-0000-000000000000" , "organizationID" : "00000001-0000-0000-0000-000000000000" , "name" : "ユーザ03" } ] } ]
実行されたSQLは次の3つでした。Eager Loadingがきちんと効いていますね。
SELECT * FROM event ORDER BY date desc ;SELECT * FROM event_user WHERE (event_user.event_id IN ($1 ));SELECT * FROM user WHERE (user.id IN ($1 ,$2 ));
集計を含むSELECT 参加者数の多いイベントを取得する処理を考えます。
SQLは次の通りです。
select event.* , coalesce (r1.participants, 0 ) as participantsfrom eventleft join ( select event_id as id, count (* ) as participants from event_user group by event_id order by participants desc limit 10 ) r1 on event.id = r1.id order by participants desc
ここまで来るとクエリビルダに頭を悩ませるのも大変なので、SQLをそのまま実行させます。
type EventPopularity struct { boiler.Event `boil:",bind"` Participants int `boil:"participants" json:"participants"` } func ListPopularEvents (ctx context.Context) error ) { r := []*EventPopularity{} queries.Raw(` select event.*, coalesce(r1.participants, 0) as participants from event left join ( select event_id as id, count(*) as participants from event_user group by event_id order by participants desc limit 10 ) r1 on event.id = r1.id order by participants desc ` ).Bind(ctx, db, &r) return r, nil }
実行結果は次の通りです。
[ { "id" : "00000000-0000-0000-0000-000000000001" , "name" : "イベント01" , "date" : "2015-10-21T00:00:00Z" , "participants" : 2 } ]
SQLBoilerのつらいところ Bulk Insertが出来ない SQLBoilerで生成されたコードにBulk InsertのAPIは含まれていません。複数件のInsertを行うためにはfor文を使う、などの対応となります。
ただ、テンプレートを追加することでBulk Insertのコードを生成している方もいるようです。https://qiita.com/touyu/items/4b25fbf12804f12778b7
テーブル設計に若干の制約が生じる 主な制約は以下の2つです。
関連するテーブルには外部キー制約を設定する必要がある
中間テーブルには結合先2テーブルの主キーを使った複合主キーを設定する必要がある
上記例の event_user テーブルでは、複合主キー (event_id, user_id) を設定することが必須 です。
これらの制約は主にEager Loadingのためのもので、クリアできない場合には各テーブルを手動でJoinする必要が出てきます。
プロジェクトによっては「外部キー制約は使わない」という設計ポリシーを取っていることもあるかと思いますので要注意ポイントです。
そもそもデータベースが無いと開発が進まない これはSQLBoilerが悪いわけではありません。
ただ「データベースを元にコードを生成する」というアプローチ上、
このようなシーンが頻発するのであれば、Migration機能を持つGORMなどのほうが適任かもしれません。
SQLBoilerとoapi-codegenによるREST APIサーバ開発 タイトル回収です。SQLBoilerとoapi-codegen によるコード生成を活用したREST APIの開発フローを紹介します。
oapi-codegenの詳細はここでは割愛します。以下記事を御覧ください。Go の Open API 3.0 のジェネレータ oapi-codegen を試してみた
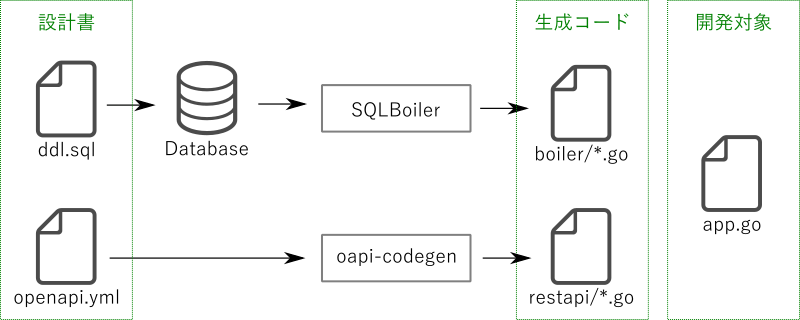
まず、設計書としてデータベースのDDL、API定義のopenapi.ymlが用意されている前提です。boiler と、ルーティング他を担う restapi を生成します。
我々が開発するのは、上記2パッケージのグルーコード、ビジネスロジックを担う app.go です。
開発例 今回は例として次のようなOpenAPI定義を用意しました。
openapi: 3.0 .0 paths: /user: get: description: Returns an array of User operationId: listUsers responses: '200': content: application/json: schema: type: array items: $ref: '#/components/schemas/User' components: schemas: User: type: object required: - id - name properties: id: type: string format: uuid name: type: string example: "Emmett Brown"
この定義を元にoapi-codegenを実行すると、次のようなStructが出来ます。
package modeltype User struct { Id string `json:"id"` Name string `json:"name"` }
このStructに、gomodifytags によって boil タグを追加します。openapi.yml の x-oapi-codegen-extra-tags を利用すると任意のタグを付与することも可能ですが、ひとつひとつのフィールドに追加するのは漏れが出そうだったので、gomodifytagsを使っています。
package modeltype User struct { Id string `json:"id" boil:"id"` Name string `json:"name" boil:"name"` }
あとはSQLの実行結果をこのStructにBindすれば完成です。
この例ではAPI定義の User のフィールドはすべてテーブル定義の User に含まれているため、SQLBoilerで生成されたSelect文から直接Bindが可能です。
func ListUser (ctx context.Context) error ) { res := []*model.User{} err := boiler.Users().Bind(ctx, db, &res) if err != nil { return nil , err } return res, nil }
参考までに、コード生成のためのMakefileを掲載します。
.PHONY : generategenerate: boiler restapi/types.go boiler: sqlboiler psql restapi: mkdir -p $@ restapi/types.go: openapi.yml restapi oapi-codegen -generate types -package restapi -o $@ .tmp $< gomodifytags -all -add-tags boil -transform snakecase -all -file $@ .tmp > $@ rm -f $@ .tmp
まとめ SQLBoilerの使い方と、これを使ったREST APIサーバの開発フローを紹介させていただきました。
私は過去約3年ほど、数プロジェクトでSQLBoilerを採用しています。
この間Goは1.10から1.16となり、SQLBoilerはv2からv4に(主にGo modules対応で破壊的変更はありませんでした)進化しています。
その性質上うまくハマらないプロジェクトもあるかと思いますが、うまくハマればとても使いやすいライブラリと感じています。
なお、今回利用したコード、プロジェクトはこちらのリポジトリ にまとめてあります。
次は伊藤真彦さんのSQLビルダーgoquの使い方 です。