はじめに
TIG DXユニット真野です。Python連載の2本目です。普段はPython触らないのですが、データリネージという概念に興味をもったのと、それをサポートするためのPytnon製ツールがあったので触ってみます。
データリネージとは
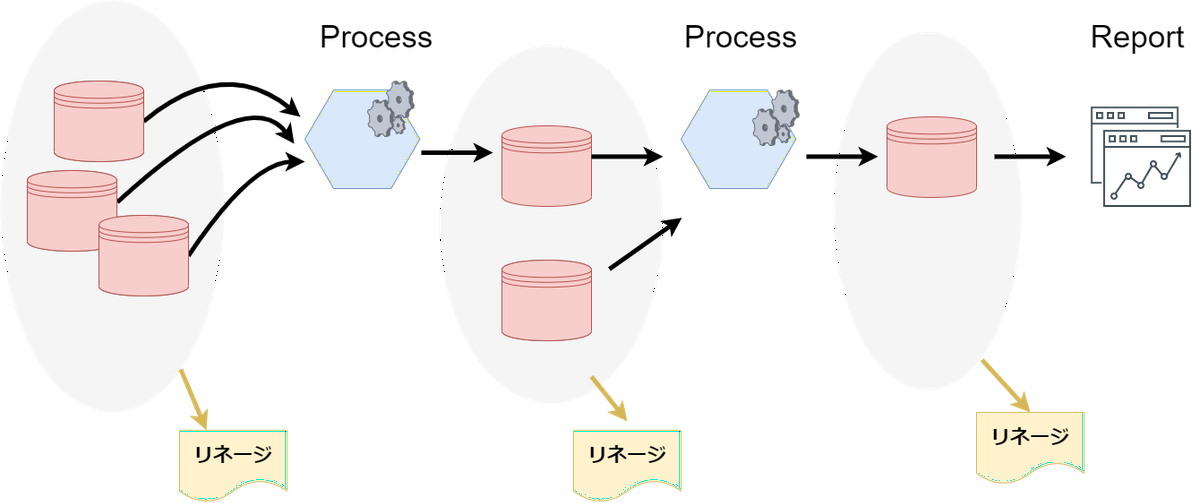
DWHのようなデータ基盤を整える上で必要になってくる概念で、保持するデータの発生源や、どのシステムがどう加工して保存されたかと言った流れを追跡できるようにすることです。データのトレーサビリティとも言うかなと思います。追跡可能にすることで、異常データの追跡(要はどこのETL処理で考慮漏れがでたりバグっちゃったのか)や依存関係などを捉えることができます。何かしらの分析にそのデータを利用すべきかどうかの重要な材料になるのは間違いないでしょう。システム開発においての影響度調査などにも便利かもしれませんね。
以下のページなどが参考になるかと思います
メタデータ管理というとベンダーごとに規格が乱立しそうですがオープンリネージという取り組みもあるようです。
ちなみに、リネージという単語を自分は聞き覚えがありませんでしたが、以下のような出自とか血統を指すようです。
リネージは、始祖を含む成員の構成が具体的にたどれる出自集団(=多くは父系か母系だが現在ではその両方あ るいは任意の親族集団)のことをさします。出自(しゅつじ)とは「自分はなになに一族、なになに家の出身だ」という、親族の出身の出所を示す用語です。
https://www.cscd.osaka-u.ac.jp/user/rosaldo/121110lineage_clan.html
積極的に使っていこうと思います。
データリネージの分類
データリネージを構成するシステムは、アクティブかパッシブかで分類できるそうです。
- アクティブ: データパイプライン側がソース情報と変換情報をリネージ側に明示的に提供
- パッシブ: SQLの実行ログを解析しリネージ情報を登録する。それによりデータリネージの更新呼び出しをパイプラインに追加するなどの手間を削減する。
またデータの追跡と言っても、粒度で複数のレベルが定義されています。
- エンティティ(テーブル)レベル
- 列レベル
- 行レベル
このうち最も簡易的だと思う(それでも実践的です)テーブルレベルのデータリネージを行えそうなSQLLineageを触ってみます。
SQLLineage
SQLLineageはデータリネージの中でも、SQLに特化したツールです。
READMEにも記載されている通り、pipでインストールできます。
# インストール |
サンプル実行
実行は簡単です。-gオプションでグラフ表示されます。
# サンプルの実行 |
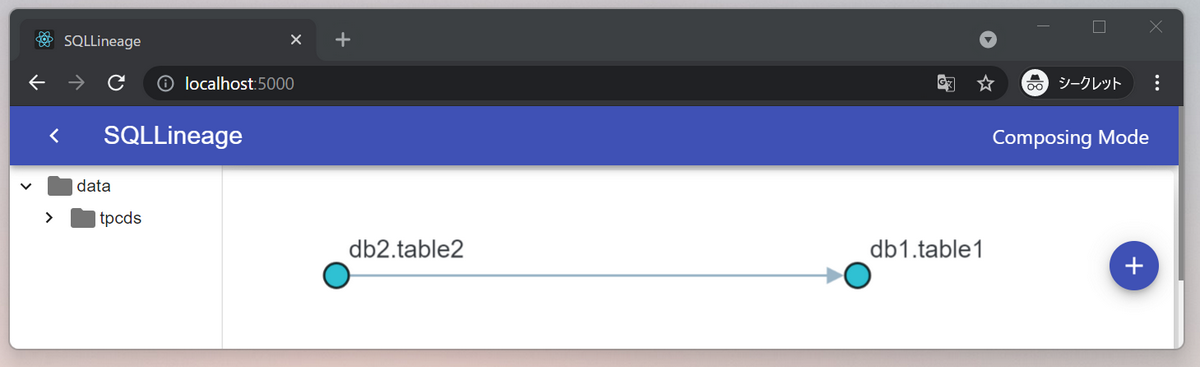
コンソールに出力されたURLを開くと、次のような db2.table2 から db1.table1 にデータが流れていることが表示されます。素敵そう!
内部結合SQL
次に内部結合したSQLでどうなるか試してみます。
INSERT INTO table1 (name, text) |
-fオプションでファイルを指定できます。
$ sqllineage -g -f join.sql |
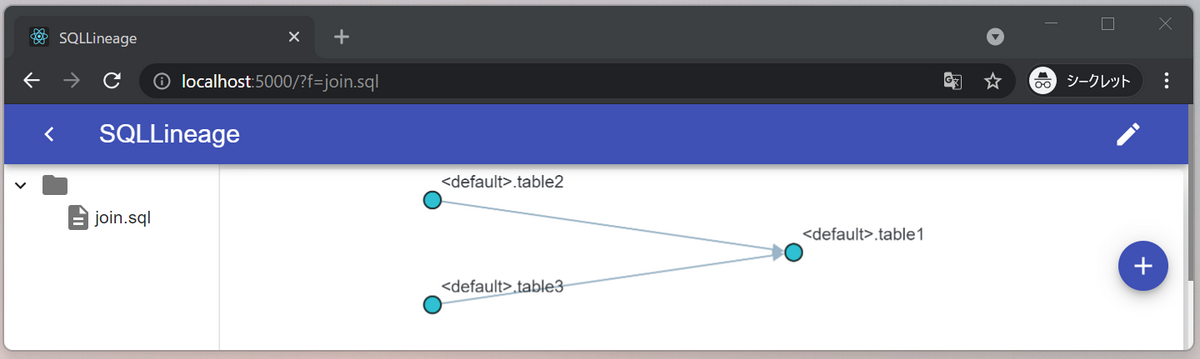
table2, table3がtable1の入力になっていることがわかります。
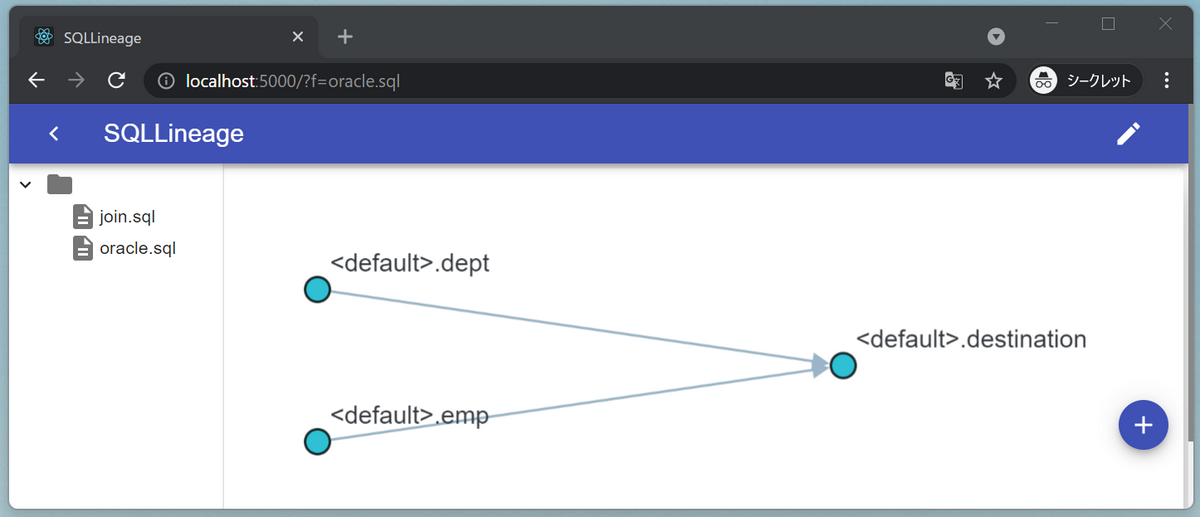
JOINを用いない結合SQL
私が最初に触ったRDBはOracleだったので、せっかくなのでOracleのJOINを利用しないSQLを試してみます。
INSERT INTO destination (emp_id, dept_id, dept_name) |
$ sqllineage -g -f oracle.sql |
この記法でも認識してくれるようです。凄い。
sqllineageは内部的にはandialbrecht/sqlparseを利用しているので、対応具合はそちらを見るのが良さそうです。例えば、Oracle 11gのPivot/Unpivotは2021.09.28時点だとまだ対応して無さそうなのがわかります。
1処理で複数のSQLが登場する場合
ここで個人的に気になったのは、1つのETLで複数のSQLが呼ばれる、多段になっているケースです。これはREADMEをちゃんと読めばちゃんと書かれています。;区切りで複数のSQLを記載すれば良いとのこと。
例えば、あるプログラムで2つのSQLが呼ばれているとします。その場合はカンマ区切りでSQLログを集約すれば良いです。
INSERT INTO tbl3 (name, text) |
これをsqllineageの入力とします。
>sqllineage -g -f multiple.sql |
結果は次のように、;で区切られた複数のSQLのフローをまとめて表示してくれます。
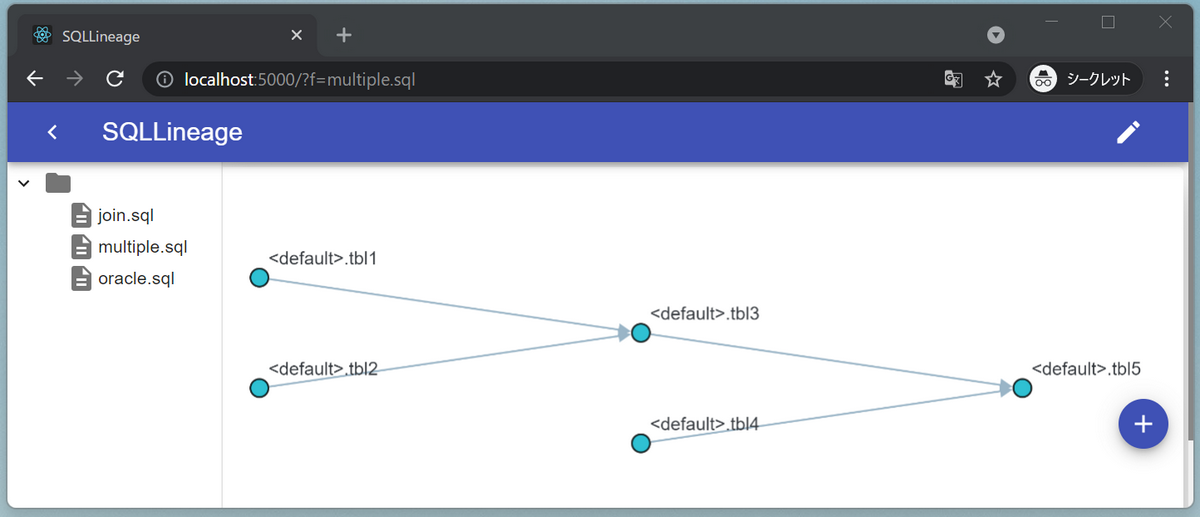
解析したい単位でSQLをまとめると、分析部分はsqllineageに頼れるということです。良い棲み分けだなと感じました。
SQL結果セットをアプリ側で読み込み、インサートする場合
Webアプリケーションだとよくありそうな処理方式ですが、この場合の解析はSQLLineageでは難しそうです(調べきれませんでした)。
おそらくSQLLineageのスコープ外だと思われるので、別のツール(Marquezなど)の検討を考えたほうが良いかなと思います。
列(カラム)レベルのデータリネージ
今の所、sqllineageは列レベルのデータリネージサポートは行わない方針のようです。理由は全てのSQLシステムに対応したメタデータサービスが存在しないためだそうです。実際のDBサーバにアクセスしないポリシーに感じられます。どういうことかと言うと、 select * とされるとこのSQLクエリだけ見てもカラムレベルのトレースが無理になるからです。
select * には対応しないけど、ちゃんとSQLに項目を書く前提で、カラムレベルも将来のバージョンでは考えているようなことも記載されていました。期待したいですね。
まとめ
データリネージのパッシブなデータ収集に、SQLログを解析するという手法があります。SQLLineageを用いると簡単に解析結果を確認・可視化できるためオススメです。
データ基盤といったプラットフォーム開発者以外にも、複雑なSQLの構造を可視化したい人にも使えるかと思います。
SQLユーザの皆様のお役にたてば幸いです。