はじめに
Python連載の5本目です。
当初テーマをPySparkで予定しておりましたが、そこから派生して、AWS Glueを題材にさせていただきます。
AWS Glue Data Catalogについて
Glueといっても大きく下記の3種類、処理系をいれると4種類に分かれると思っていますが、それぞれ全く別のプロダクトという理解をしています。
- AWS Glue
- AWS Glue Data Catalog
- Hive MetaStore
- AWS Glue DataBrew
CSVを利用する上での困りごと
1. crawlerが利用できない
AWSが推奨するベストプラクティスでは、「crawlerを利用することでデータをCatalog化し、多様や処理系で利用できる」とされていますが、’”’ダブルクォーテーションで囲まれたフィールドを持つCSV(TSVも同様)の場合、正しく読み込まれず(※)、AWS上のドキュメントでも対応が必要とされています。
.png)
2. テーブルのデータ型を全てStringに設定する必要がある
crawlerを利用できないこともシステム運用上の困りごとになりますが、それ以上にデータ型に問題があります。
OpenCSVSerDeを利用したCatalogでは、データ型をStringに固定する必要があり、Catalog化のメリットが半減してしまいます。
CSVへの対応方法
利用するCSVファイル
データ
"ID","NAME","FLG","NUM","DATE","DATE TIME" |
crawlerで読み込んだ直後の状態
crawlerで読み込んだデータをAthenaより表示すると以下の状態となります。
データが欠損して表示されている事がわかります。
同じく、Athenaのメニューより見たテーブル定義になります。
定義的には一見正しく見えますが、前述の通り正しく動かない状態になります。
対応方法1:OpenCSVSerDeを利用する
crawlerでCSVを読み込み、DDL化します。
このDDLを修正ます。
CREATE EXTERNAL TABLE `sample`( |
修正後、全てのデータが表示できるようになります。
ただし、全てはString型として認識されているため、データは文字列として扱う必要があります。
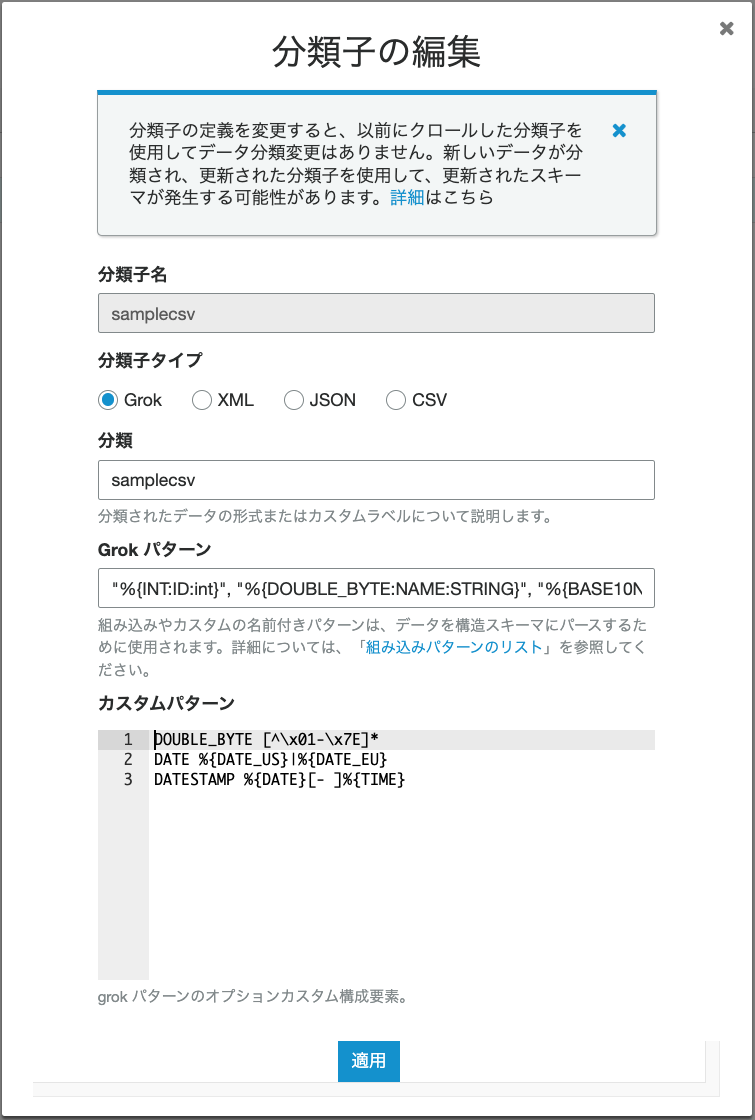
対応方法2:crawlerのカスタム分類子(Grok)を利用する
正規表現を元にした、パーサーを自分で用意する形になります。
詳細は、AWSをの公式を見るのが良いと思いますが、抜粋、要約すると、フィールド単位にマッピング定義を作る方法となります。
%{PATTERN:field-name:data-type}
今回のCSVでは、以下の形となります。
こちらがよく纏められており、見ながらやったのですが、どうしても読み込んでくれませんでした。。。
なお、構文チェックはWebで可能です。
- 構文チェック
- Grokパターン
"%{INT:ID:int}", "%{DOUBLE_BYTE:NAME:STRING}", "%{BASE16FLOAT:NUM:STRING}, "%{DATE:DATE:DATE}", "%{DATESTAMP:DATE TIME: TIMESTAMP}"
- カスタムパターン
DOUBLE_BYTE [^\x01-\x7E]*
- 画面の入力例
対応方法3:CSVをparquestに変換して利用する
システムとの親和性が最も高いparquestに変換後、crawlerでCatalog化します。
parquestへの変換では、元データに何も手を入れない形にします。
import boto3 |
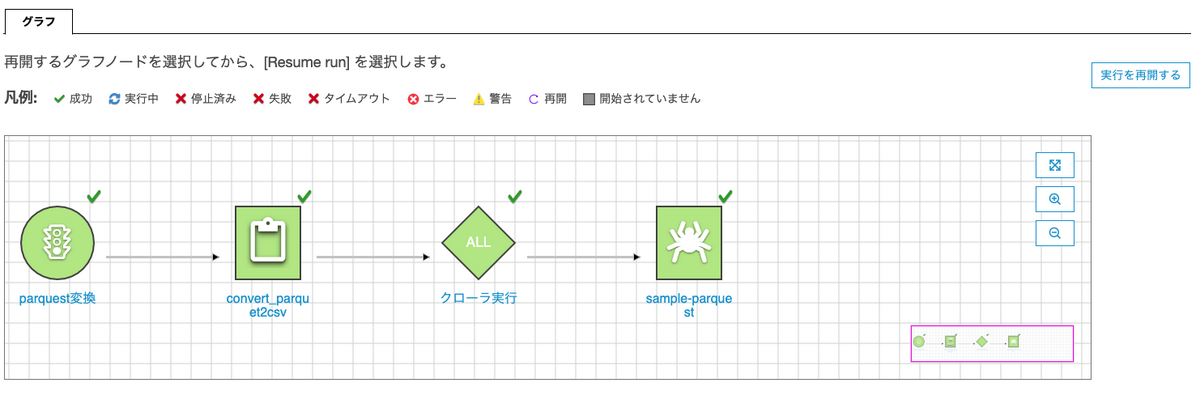
この変換処理をワークフローでcrawlerとつなげます。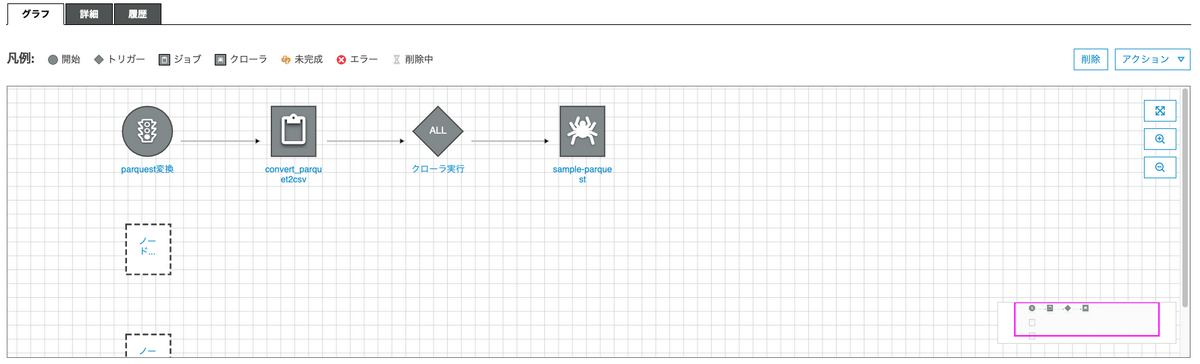
全ての成功を確認後、Athenaからデータを見てると、余計な一手間がいらずデータを参照でき、データ型もCatalogの範囲内でハンドリングされています。
実行結果
データプレビュー

テーブル定義

まとめ
データ型を認識でき、手軽に実行できる対応方法3:CSVをparquestに変換して利用するを基本方針として考える形で良いと思いました。