はじめに 昨年の記事1
せっかくなので昨年の記事と少しコードを変えようと思い、AWSの公式ドキュメント2
docker-compose
LocalStack
を使用している点が異なるので、その点でも本記事は参考になると思います。
本記事で紹介するコードは以下のリポジトリに載せてあります。
https://github.com/RyujiTamaki/glue-dev-sample
ディレクトリ構成は以下のようになっています。
$ tree . ├── README.md ├── docker-compose.yml ├── spark.conf ├── src │ ├── __init__.py │ └── sample.py └── tests ├── __init__.py └── test_sample.py
docker-compose.yml 本記事ではDockerFileを特に作らず、GlueとLocalStackのDockerイメージをそのまま使用します。
以下docker-compose.ymlになります。
version: '3.5' services: glue.dev.s3.local: container_name: s3.dev image: localstack/localstack:0.12.8 environment: - SERVICES=s3 - AWS_DEFAULT_REGION=ap-northeast-1 - AWS_DEFAULT_OUTPUT=json - AWS_ACCESS_KEY_ID=test - AWS_SECRET_ACCESS_KEY=test networks: - glue.dev.network glue.dev.summary: container_name: glue.dev image: amazon/aws-glue-libs:glue_libs_3.0.0_image_01 volumes: - ./:/home/glue_user/workspace/jupyter_workspace - ./spark.conf:/home/glue_user/spark/conf/spark-defaults.conf environment: - DISABLE_SSL=true - AWS_REGION=ap-northeast-1 - AWS_OUTPUT=json - AWS_ACCESS_KEY_ID=test - AWS_SECRET_ACCESS_KEY=test ports: - 8888 :8888 - 4040 :4040 networks: - glue.dev.network command: /home/glue_user/jupyter/jupyter_start.sh networks: glue.dev.network: name: glue.dev.network
以前の記事1 jupyter_start.sh をDockerFileでコピーしていましたが、本記事では最初からDockerイメージにある jupyter_start.sh を実行しています。
また、Glue3.0の公式のDockerイメージにはバグがあり、暗号化を無効にすることで解決することが報告されています3 spark.conf を用いて /home/glue_user/spark/conf/spark-defaults.confを上書きしています。
上書きに使用している spark.confは以下になります。元からある /home/glue_user/spark/conf/spark-defaults.conf の spark.io.encryption.enabled を falseに書き換えています。
spark.driver.extraClassPath /home/glue_user/spark/jars/*:/home/glue_user/aws-glue-libs/jars/* spark.executor.extraClassPath /home/glue_user/spark/jars/*:/home/glue_user/aws-glue-libs/jars/* spark.sql.catalogImplementation hive spark.eventLog.enabled true spark.history.fs.logDirectory file:////tmp/spark-events spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version 2 spark.hadoop.mapreduce.fileoutputcommitter.marksuccessfuljobs false spark.unsafe.sorter.spill.read.ahead.enabled false spark.network.crypto.enabled true spark.network.crypto.keyLength 256 spark.network.crypto.keyFactoryAlgorithm PBKDF2WithHmacSHA256 spark.network.crypto.saslFallback false spark.authenticate true spark.io.encryption.enabled false spark.io.encryption.keySizeBits 256 spark.io.encryption.keygen.algorithm HmacSHA256 spark.authenticate.secret 62e100c5-5281-4030-992b-1f60391ed508
Glueジョブのサンプルコードとテストコード AWSの公式ドキュメント2
サンプルコードは以下です。
import sysfrom pyspark.sql import SparkSessionfrom awsglue.context import GlueContextfrom awsglue.job import Jobfrom awsglue.utils import getResolvedOptionsclass GluePythonSampleTest : def __init__ (self ): params = [] if '--JOB_NAME' in sys.argv: params.append('JOB_NAME' ) args = getResolvedOptions(sys.argv, params) self .context = GlueContext(SparkSession.builder.getOrCreate()) self .job = Job(self .context) if 'JOB_NAME' in args: jobname = args['JOB_NAME' ] else : jobname = "test" self .job.init(jobname, args) def run (self ): dyf = read_json(self .context, "s3://awsglue-datasets/examples/us-legislators/all/persons.json" ) dyf.printSchema() self .job.commit() def read_json (glue_context, path ): dynamicframe = glue_context.create_dynamic_frame.from_options( connection_type='s3' , connection_options={ 'paths' : [path], 'recurse' : True }, format ='json' ) return dynamicframe if __name__ == '__main__' : GluePythonSampleTest().run()
S3に置かれたJSONファイルをDynamicFrameに読み込む処理をしています。
import pytestfrom pyspark.sql import SparkSessionfrom awsglue.context import GlueContextfrom awsglue.job import Jobfrom awsglue.utils import getResolvedOptionsimport sysfrom src import sample@pytest.fixture(scope="module" , autouse=True ) def glue_context (): sys.argv.append('--JOB_NAME' ) sys.argv.append('test_count' ) args = getResolvedOptions(sys.argv, ['JOB_NAME' ]) sc = SparkSession.builder.getOrCreate() sc._jsc.hadoopConfiguration().set ("fs.s3a.endpoint" , "http://glue.dev.s3.local:4566" ) sc._jsc.hadoopConfiguration().set ("fs.s3a.path.style.access" , "true" ) sc._jsc.hadoopConfiguration().set ("fs.s3a.signing-algorithm" , "S3SignerType" ) sc._jsc.hadoopConfiguration().set ("fs.s3a.change.detection.mode" , "None" ) sc._jsc.hadoopConfiguration().set ("fs.s3a.change.detection.version.required" , "false" ) context = GlueContext(sc) job = Job(context) job.init(args['JOB_NAME' ], args) yield (context) job.commit() def test_counts (glue_context ): dyf = sample.read_json(glue_context, "s3://awsglue-datasets/examples/us-legislators/all/persons.json" ) assert dyf.toDF().count() == 1961
公式のドキュメントのコードとは以下の設定を加えている箇所が異なります。
sc = SparkSession.builder.getOrCreate() sc._jsc.hadoopConfiguration().set ("fs.s3a.endpoint" , "http://glue.dev.s3.local:4566" ) sc._jsc.hadoopConfiguration().set ("fs.s3a.path.style.access" , "true" ) sc._jsc.hadoopConfiguration().set ("fs.s3a.signing-algorithm" , "S3SignerType" ) sc._jsc.hadoopConfiguration().set ("fs.s3a.change.detection.mode" , "None" ) sc._jsc.hadoopConfiguration().set ("fs.s3a.change.detection.version.required" , "false" )
以前のAWS Glueの単体テスト環境の構築手順4 5
動作確認 以下コマンドでDockerを起動します。
docker compose up --build
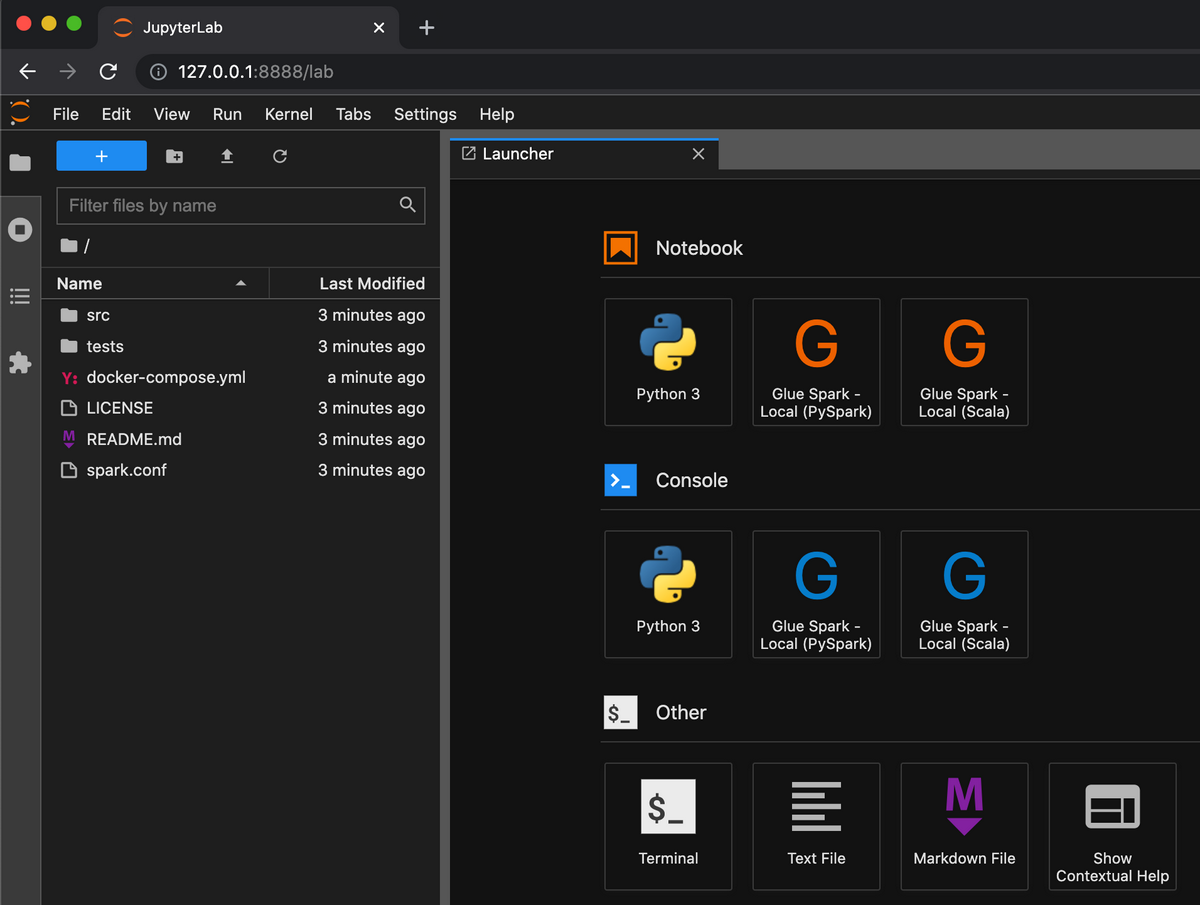
Glue用のコンテナとLocalStack用のコンテナが立ち上がります。http://127.0.0.1:8888 にブラウザでアクセスすると、JupyterLabが起動していることが確認できます。
次にテストを実行してみましょう。
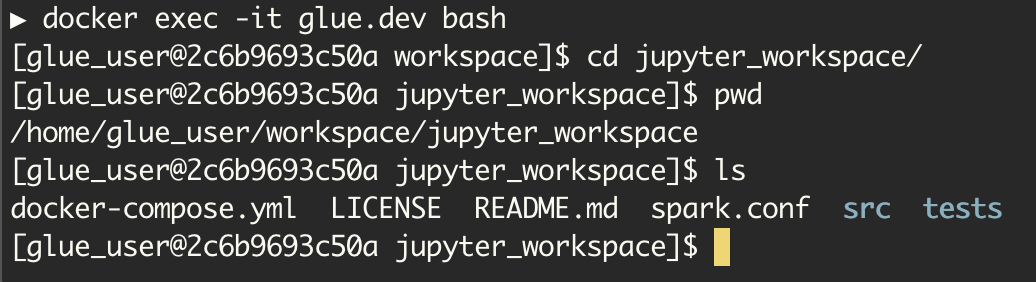
docker exec -it glue.dev bash
/home/glue_user/workspace/jupyter_workspace にマウントしたファイルがあることが確認できます。
テストに使用するJSONファイル s3://awsglue-datasets/examples/us-legislators/all/persons.json をローカルにコピーします。
Dockerコンテナ内で以下コマンドを実行し、LocalStackのS3に格納します。
aws s3 mb s3://awsglue-datasets --endpoint-url http://glue.dev.s3.local :4566 aws s3 cp /path/to/persons.json s3://awsglue-datasets/examples/us-legislators/all/ --endpoint-url http://glue.dev.s3.local :4566
jupyter_workspace配下で以下のコマンドを実行することにより、pytestが実行できます。
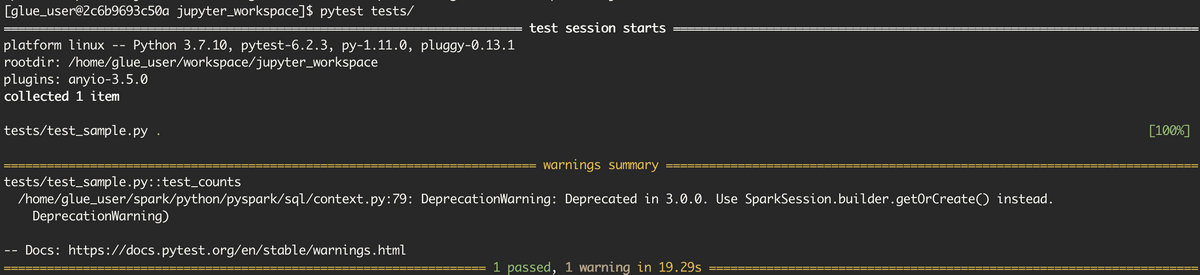
以下実行結果です。
DeprecationWarning: Deprecated in 3.0.0. Use SparkSession.builder.getOrCreate() instead.
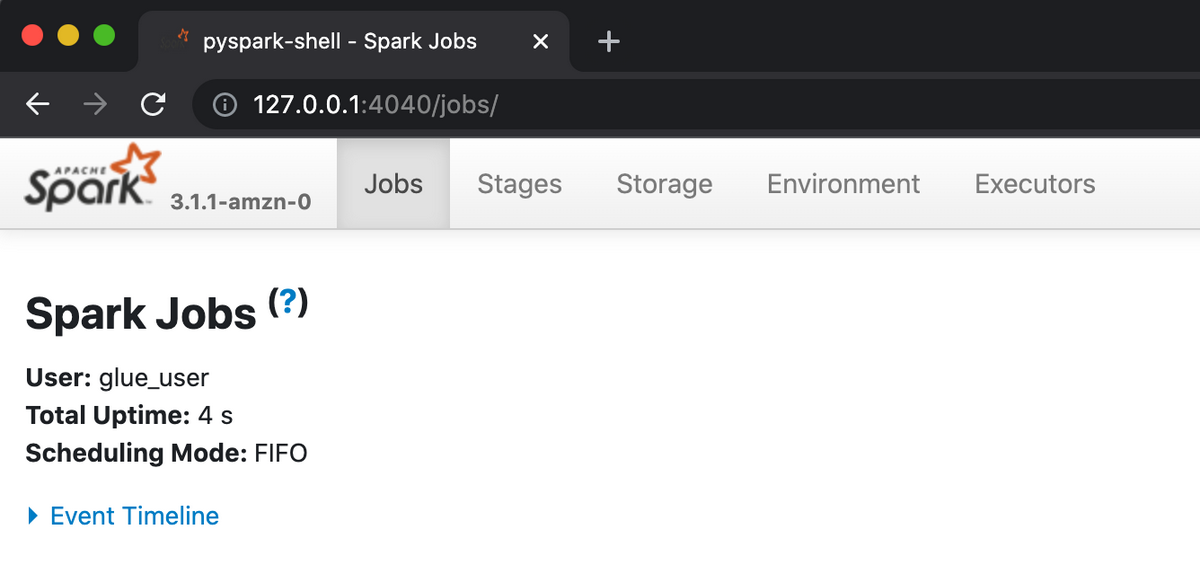
上記Warningが出ていますが、テストがパスできたことを確認できました。http://127.0.0.1:4040/ にブラウザでアクセスすると、Spark UIを確認できます。
Jobの調査に便利です。ただ、自分が使ってみたところ少し不安定なところもありました。今後の改善に期待です。
以上で開発環境構築の紹介を終わります。以降はsrc/以下にGlueジョブのスクリプトを作成、tests/以下にGlueジョブのテストを追加、としていくといいと思います。
注意点 dockerを再起動すると以下のようなエラーが出ます。
glue.dev | PermissionError: [Errno 13] Permission denied: '/home/glue_user/.jupyter/migrated'
根本解決になっていなくて恐縮ですが、一度 docker compose rm で停止済みのコンテナを削除すると次の docker compose upでは上記のエラーが出ずにJupyter Labが立ち上がるようになります。
まとめ 本記事では最新のGlue3.0のDockerイメージを使って、ローカルでの環境構築を紹介しました。