はじめに
こんにちは。TIG DXチームの後藤です。2021年7月に新卒でフューチャーに入社しました。
業務でAPIを通して数万~100万のデータのバッチ処理を行うLambdaの開発を行ったので、学びを共有したいと思います。
システム構成
参画しているプロジェクトでCSVデータをデータベースに登録する必要がありLambdaの開発を行いました。ちなみに所属しているチームではGo言語を採用しているので、Go言語で開発を行いました。データを登録するためのAPI(API Gateway + proxy統合Lambda)を活用してバッチ処理を行います。データの件数は数百件から数十万件と幅が広く、「数十万件ものリクエストをLambdaの実行時間制限である15分以内に処理しきれるのか?」というところから開発を始めました。
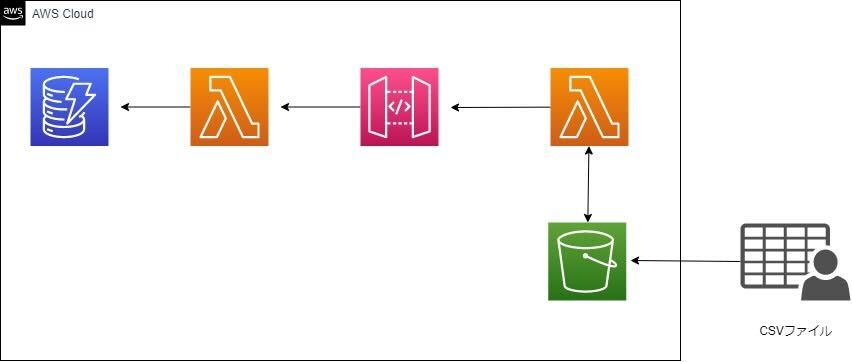
ちなみに、1Web API呼び出しに大体30ms~80msほどかかります。
AWS Lambda
AWS Lambdaはマネージドサービスでありサーバーの運用管理が必要なく、プログラムが実行された時間に対してのみ課金がされるので、開発コスト、運用コスト、金銭面を考えると非常に使い勝手がいいサービスです。実際に私の所属しているチームではLambdaを積極的に活用しています。そんな便利なLambdaですが、実行時間に制約があり最大で15分までの処理しか行うことができず、15分以上の時間がかかる処理を行う場合にはEC2などの別の環境を用意する必要があります。
試してみた結果
まずは非同期処理を使わず同期処理でデータの登録を実行してみました。
CSVファイルから読み込んだデータを登録するプログラムを書きLambdaのメモリサイズを512MBに設定ました。サンプルデータとして2万行のCSVファイルの処理を実行してみました。
for _, line := range lines { |
結果としては、約1万4千件のデータを登録し終えたところで15分の実行時間制限を超えてしまいました。通常の方法では数十万件のデータの処理は難しい事がわかりました。
並行処理
実際にプログラムを動かして、数十万件のデータを登録することが難しいとわかったので、他の方法を考えることにしました。1つ目の方法はStep Functionsを使いCSVデータを分割し処理する方法、2つ目はgoroutineで並行処理を行う方法です。Step Functionsを使う場合には追加でインフラの設定が必要になりますが、ソースコードは並行処理を行う場合よりもわかりやすくなるというメリットがあります。goroutineで並行処理を行う場合には、ソースコードは少し複雑になりますが、インフラのリソースを追加する必要がなく1つのLambdaでバッチ処理が完結します。今回はインフラ管理などの保守の容易さからgoroutineを実装することにしました。1つのLambdaで処理が完結している場合の方がログの確認も容易かと思います。再度メモリサイズを512MBに設定しサンプルデータ2万行のCSVファイルの処理を実行しました。
※エラーハンドリングを行う場合にはsync.ErrGroupを使用する方がよさそうです。
var wg sync.WaitGroup |
結果は、20秒かからずに終了!
Duration: 19927.45 ms Billed Duration: 19928 ms Memory Size: 512 MB Max Memory Used: 206 |
と喜んでいましたが、ログをよく見ると
dial tcp xxx.xxx.xxx.xxx:443: socket: too many open files |
というエラーが大量に出力されていました。
これはgoroutineで大量のコネクションを同時に作成してしまっているために起こるエラーです。
ということで、goroutineの同時実行数を500に制限することにしました。東京リージョンでのLambdaの同時実行数の上限は1000件であるためその半分である500に設定しました。
var wg sync.WaitGroup |
実行してみると無事にエラーなく処理が終了しました。2万件の処理が約20秒で終了することがわかりました。並行処理を使うとかなり高速に処理が行えました。
同時実行数と実行時間
無事に処理が実行できたところで次に気になるのが、同時実行数と実行時間の関係性です。行数を20万、メモリを1024MBに固定し同時実行数を100,300,500と変えて関係性を調査してみました。
| 同時実行数 | APIの最大同時実行数 | メモリ(MB) | 実行時間(秒) |
|---|---|---|---|
| 100 | 98 | 1024 | 246 |
| 300 | 304 | 1024 | 218 |
| 500 | 469 | 1024 | 227 |
それぞれ一度ずつしか実行していませんが、API(Lambda)の最大同時実行数は概ね設定した上限値に近い値になっています。Lambdaの最大同時実行が304になっている理由はよくわかりませんが、他のリーソースからAPIが呼ばれたか、実行後のLambdaが完全に停止する前に新しくgoroutineが実行されたのだと思います。実行するたびに結果は違うとは思いますが、表の結果から同時実行数を300あたりに制限するのが良さそうです。
メモリサイズと実行時間
同時実行数と実行時間の関係性がわかり、その次に気になるのが、メモリサイズと実行時間の関係性です。同時実行数を500、行数を10万に固定してメモリサイズを変え実行時間との関係性を調査しました。
| 同時実行数 | APIの最大同時実行数 | メモリ(MB) | 実行時間(秒) |
|---|---|---|---|
| 500 | 488 | 1024 | 199 |
| 500 | 320 | 2048 | 110 |
| 500 | 460 | 4096 | 46 |
| 500 | 502 | 6144 | 39 |
| 500 | 475 | 8192 | 27 |
メモリサイズが大きいほど、実行時間が短くなっています。それぞれの最大メモリ使用量は200MB~280MBに収まっていたので、CPUの性能の違いで処理が高速化した可能性が高いです。
APIを100万回呼び出す
最後に8GBのメモリで100万行の処理を実行してみました。
処理時間はなんと258秒でした!
多少上振れするとしても、Lambda関数の実行時間の限界である900秒以内に200万件は余裕で登録出来そうです!
参考文献
Writing Large Data to CSV File in Go
[Golang]ループ処理内でgoroutineを使う時に考慮しておくべきこと
Lambda function scaling
pkg.go.dev/golang.org/x/sync/errgroup