
はじめに
こんにちは。TIG DXユニット所属、金欠コンサルタントの藤井です。
最近買ってよかったものは玄関に設置できる宅配ボックスです。
失敗談連載2022 4日目のこの記事では、クラウドインフラにはつきものの、インフラコストについての失敗談をご紹介します。
ぜひご一読いただき、私の屍を乗り越えていく事で、悲劇の発生を未然に防いでいただければと思います。
(一部記事にするにあたり、経緯を改変している部分があります。ご容赦ください)
RDSについて
概要
皆さん、RDSはお好きでしょうか。私は基本的に好きです。Amazon Relational Database Service、略してRDS。その名の通りAWSが提供する、RDBを運用するためのマネージド型サービスです。
高い可用性・耐久性・スケーラビリティを誇るサービスであるため、サービスの管理者はDBサーバそのものをほとんど意識をすることなくサービスを提供することが可能となります。
そんなRDSですが、2つだけどうしても私が好きになれない点があるので、紹介させてください。
私が好きになれない点
単純に利用料金が高い
前述のとおり、RDSはDBサーバの構築・運用において非常に便利なサービスを提供してくれます。EC2へのRDBMSのインストールから、ストレージ管理、障害時のフェイルオーバー、等と言った作業を管理者が実施する場合、人的コストもかなりかかってしまいます。
そのため、ある程度利用料金が高くなるのは仕方がないことではあります。
ご参考までに2022年5月時点での東京リージョンにおけるRDS1(シングルAZ・Aurora PostgreSQL互換エディション・オンデマンドインスタンス)とEC22(オンデマンド・OSはLinux)の料金比較をいくつかのインスタンスタイプについて以下に掲載します。
| インスタンスタイプ | RDSの時間あたりの料金 (USD) | EC2の時間あたりの料金 (USD) | RDSコスト/EC2コスト |
|---|---|---|---|
| t4g.medium | 0.113 | 0.0432 | 2.62 |
| t4g.large | 0.225 | 0.0864 | 2.60 |
| t3.medium | 0.125 | 0.0544 | 2.30 |
| t3.large | 0.250 | 0.1088 | 2.30 |
| r6g.large | 0.313 | 0.1216 | 2.57 |
| r6g.xlarge | 0.627 | 0.2432 | 2.58 |
| r5.large | 0.350 | 0.152 | 2.30 |
| r5.xlarge | 0.700 | 0.304 | 2.30 |
だいたいRDSはEC2の2~3倍のコストがかかるようです(ストレージ・通信等は除く)。
もちろんリザーブドインスタンスを用いたり、不要な時間帯は停止する等で節約することは可能です。
基本的な利用料金が高いからこそ、不要な課金をしないよう管理する必要があります。
7日間しか停止できない
罠です。記載の通り、RDSは7日間しか停止できません。
例えばこの記事が公開される2022年6月6日にRDSを停止した場合、7日後の6月13日に自動的に再起動されます。
もちろん停止時には以下のように停止可能期間について案内されるため、管理者はこの仕様について把握できます。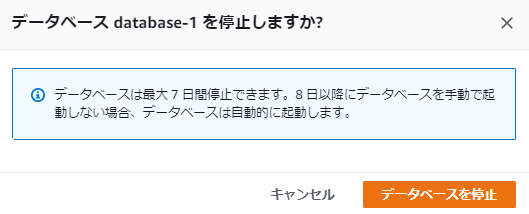
この仕様について、公式ドキュメント3には
DB インスタンスは最大 7 日間停止できます。7 日後に DB インスタンスを手動で起動しなかった場合、DB インスタンスは自動的に起動されるため、必要なメンテナンス更新が遅れることはありません。
と記載されていますが、個人的には「最大7日間しか停止できません」と書くべきだと思います。7日後に自動で再起動される理由としては、ハードウェアやRDBMS等のメンテナンスにインスタンスが遅れないようにするため、とのことです。
2022年5月時点でRDSを7日間以上停止し続ける方法は存在せず、Lambda等で定期的に再起動・停止をスケジューリングする4等の方法でしか長期的なRDSの停止はできないようです。
失敗談
ここまでの記載内容で私が何をやらかしたか、予想が付いている方も居られるかとは思います。
検証用に立ち上げ、不要になったため停止したDBが7日後に自動で再起動・利用料金が発生してしまったのです。
しかも必要以上に大きなインスタンスサイズで構築してしまっていたため、発生した余分コストは高額でした。
悲劇の発生経緯
- EC2との接続検証用にRDSのインスタンスを1つ(すぐ落とす想定だったため、インスタンスサイズはxlargeを選択)立ち上げ、無事検証を終えました。
- 検証が完了したため、このRDSインスタンスは不要となりました。しかし追加で検証が必要になることが予想されるため、ここではインスタンスの削除ではなく停止を選択しました。
- 結果として、追加検証は不要であったため、結局インスタンスが再利用されることはありませんでした。
- 停止から7日後、RDSは自動でインスタンスを再起動しました。
- このとき、私の頭には既にこのインスタンスの記憶はありません。
- RDS周りの検証は完了しているため、RDSのマネジメントコンソールにアクセスする理由も無いので、インスタンスの再起動に気づくことはありません。
- 各種構築が完了し、最後に念のため請求書を確認したところ、想定外の請求が発生している事に気づきます。
- 明細を見ると、よくわからないRDSインスタンスについての請求が・・・
おおよそ上記のような流れで悲劇は発生・検知されました。
検知後の対処にも2やらかしぐらいあるのですが、こちらは技術話では無いのでここでは割愛します。
どうすればよかったのか
ここまで失敗談について記載しましたが、ではどうすればこの悲劇は回避できたのでしょうか。
この悲劇に限らず、大体の事象において以下2つの対応が重要と考えます。
- 根本原因を取り除き、悲劇が発生しないようにする
- 事象を早期検知し、悲劇を発展させない
根本原因を取り除き、悲劇が発生しないようにする
悲劇が発生しないよう、根本原因を排除できれば悲しむ人は生まれません。
今回の悲劇に関しては、これはとても簡単で、RDSは停止せず、削除すればよいです。後で再利用することが予想される場合は、バックアップを取得した上でインスタンスはためらいなく削除してしまいましょう。
停止→再起動に比べるとバックアップからの復元の方が多少手間はかかりますが、確実に勝手に再起動されることはありません。バックアップもストレージ分のコストはかかりますが、Auroraの場合月額 0.023USD/GB5 と軽微です。
また、これはRDSに限らずですが、そもそもインスタンスサイズは必要最小限に設定しましょう。
事象を早期検知し、悲劇を発展させない
万一悲劇が発生してしまっても、早期に検知・食い止めることが出来れば最小限の悲しみに抑えられます。
一方検知が遅れれば利用料金と共に悲劇は発展し続けます。
詳細はこの記事には記載しません(いつか別記事として書くかも)が、早期検知には以下のような対策が考えられます。
- システムで検知
- AWS Budget、AWSコスト異常検出を適切に設定し、想定外の請求が発生した際に検知・通知する
- 停止中のRDSがあれば検知・再起動までの期間を通知するLambdaを作成・定期実行する
- 運用で検知(検知システムの構築ができない場合)
- 定期的(日次・週次など)に請求額を確認する。可能であればリソース毎の請求内容も確認する
- 定期的(日次・週次など)にRDSマネジメントコンソールを確認し、想定外インスタンスが存在しないことを確認する
なお、利用サービスに種類や検証などの用途に問わず、利用金額の通知周りについては、AWSアカウントを作成の初期段階で常に設定を行っておくとよいでしょう。
おわりに
私の失敗談は以上です。
インフラコストにまつわる悲劇は様々な原因で起こり得るものです。今回の内容はRDSの、それも自動再起動に特化した内容ではありましたが、対策についての考え方は様々な悲劇に共通するものです。
どうすれば悲劇を予防できるのか、早期検知できるのかについて考え続け、少しでも悲劇を抑えられると良いと思います。
失敗談連載2022 明日は辻さんのAWS Lambdaの初期化処理と初期化タイミングの考慮不足によるはまりどころです。
- 1.Amazon RDS の料金 https://aws.amazon.com/jp/rds/pricing/ ↩
- 2.Amazon EC2 の料金 https://aws.amazon.com/jp/ec2/pricing/ ↩
- 3.一時的に Amazon RDS DB インスタンスを停止する https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/USER_StopInstance.html ↩
- 4.Amazon RDS インスタンスを 7 日以上停止する方法を教えて下さい。 https://aws.amazon.com/jp/premiumsupport/knowledge-center/rds-stop-seven-days/ ↩
- 5.Amazon Aurora の料金 https://aws.amazon.com/jp/rds/aurora/pricing/ ↩