夏の自由研究連載2024の1日目です。
生成AIが人気です。生成AIに対しては自然言語で指示を与えられますが、自然言語を構造化してやりとりする方法としてはよくMarkdownが使われます。その生成AIフレンドリーなMarkdownで設計ドキュメントを作るとしても、要約をしたりといった生成AIが得意なタスクではなく、コード生成だったり、構成チェックをする場合は生成AIではなく再現性の高い従来方式のツールを併用するといったことが今後行われそうな気がするので、ルール(テンプレート)に従ったMarkdownのパース処理の実装方法をいろいろ試した結果、パーサーコンビネーターが良いかなということで試してみた記録になります。
構文解析の実装方法
何かしらのルールに従ったドキュメントやソースコードなどのテキストをパースするにはパーサーを使います。パーサーを作る場合は、LR法などの構文解析のパーサーなど作ったりします。正規表現で頑張るひともいるかもしれません。トークン分割をして、その後トークンの順序が期待通りかどうかパーサーを使って検証して、抽象構文木(AST)を作ります。パーサー(と字句解析器)を作るには手で作成したり、パーサージェネレータを使う方法があります。こちらの方法は書籍もたくさん出ています。Go言語でつくるインタプリタとか面白いですね。僕が初めて読んだのはBison入門でした。初めて触るのであれば、PythonのPLYは大学教授のDavid Beazley(SWIGの作者)がおそらく授業用に作ったものでわかりやすくこの分野を学ぶのに最適です。
一方で、小さいパーサーをたくさん作って組み合わせるパーサーコンビネータというものもあります。こちらはネットで検索すると各言語の実装はちょろちょろ出てきますが、書籍などは出てません。あんまりきちんと調べていませんが、各実装の参考リンクなどを見た感じだと、parsecというHaskell実装があり、これを参考に各言語に移植されているようです。
旧来型のパーサジェネレータや既成パーサー利用のつらみ
20世紀に出ていたプログラミング言語の作成方法の本を見て不満だったのが、本のほとんどが構文解析で終わってしまい、実行部分は1筆書きで実装できそうな、逆ポーランド記法の計算処理程度しかないことでした。がんばって構文木を作ったとしても、そこから先のステップを作ろうとすると、構文木を歩き回るビジターパターンの実装はかなりヘビーで、超巨大なswitch文の関数が出来上がったりしますし、分割しようとすると、各ステップごとに別の新しい構文木を毎回作り直すような処理を手作りしないといけなかったりします。
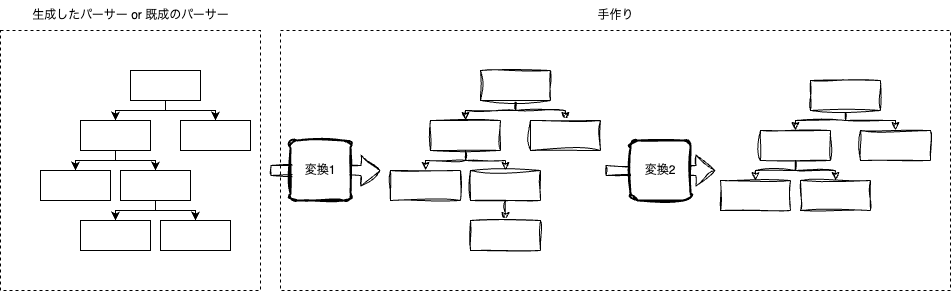
パーサールールをいろんな言語実装で共有できるような人気のライブラリのANTLRもありますが、パーサーを作った後は同じですね。最近は完全にゼロから作るのではなく、既成のパーサーを使い構文木だけは作って、それをプログラマブルな解釈もできますが、実際やってみるとやはり大変です。本エントリーでやろうとしたことを以前TypeScriptでやろうとしたことがありましたが、大変でした(いちおう動きはした)。
従来型のパーサーだと、Markdownの文法の妥当性を解釈するフェーズと、特定のドキュメント構造のルールを解釈するフェーズは同じにできず、ドキュメント構造のチェック部分は手作りする必要があります。
ようするに、構文解析部分はいろいろ便利ツールが出ていていも、それを解釈するところは便利なライブラリなどがなく、大量の手作業が必要となります。ESLint 9はその部分がAPIとして作られているのですが、そのルールエンジン相当の手作りが必要ということになります。
パーサーコンビネータのよさとつらみ
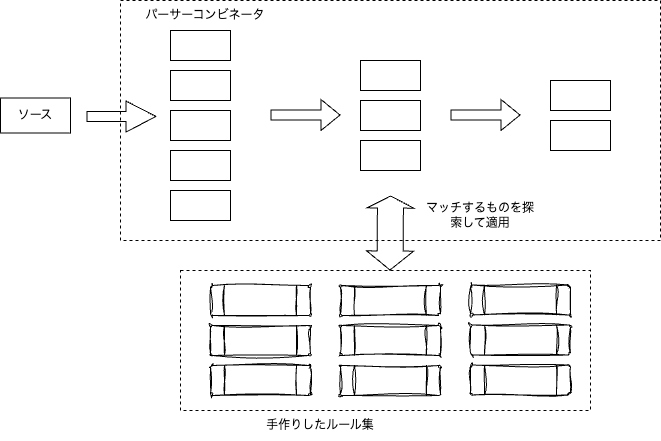
パーサーコンビネータのAPIを見ると、ちょっと複雑な構造を解釈するには良さそうです。例えば、Design Documentをテンプレート化するとして、初版だとHistoryが1つだが、改変が進むとHisitoryの項目が複数になるみたいな正規表現の+みたいなロジックだったり、パフォーマンスの懸念ががあったりなかったりする場合の*だったりとか項目数が柔軟に増えたり減ったり、存在を保証したりするような構造記述には便利そうです。つまり文法解釈と同じロジックで抽象構文木に対するルール記述ができそうです。
途中で渡るデータ形式は決まっており、それに対するルールセットを書いていけばマッチするものを探して適用してくれるため、巨大なswitch文で解釈していく必要はありません。
一方で、パーサーコンビネータも自分でいざやってみようとすると情報が少なく結構大変です。パーサーコンビネータのAPIを見ると、テキストにマッチする関数、改行にマッチする関数、前方一致、グループ化など、正規表現チックなテキストマッチのツールセットがあります(takenocoだと、GitHub.com/shellyln/takenoco/stringのパッケージが提供するAPI群)。これを使いこなそうとすると、細かい文法ルールに従った構文ルールを全部ゼロから実装する必要があります。Markdownでちょっと便利に設計ドキュメント書いて情報抽出したい、という程度のモチベーションなのに、Markdownパーサーをゼロから実装する手間がかかってしまうのは大変です。結果として大量のルールセットを実装する必要が出てきてしまいます。
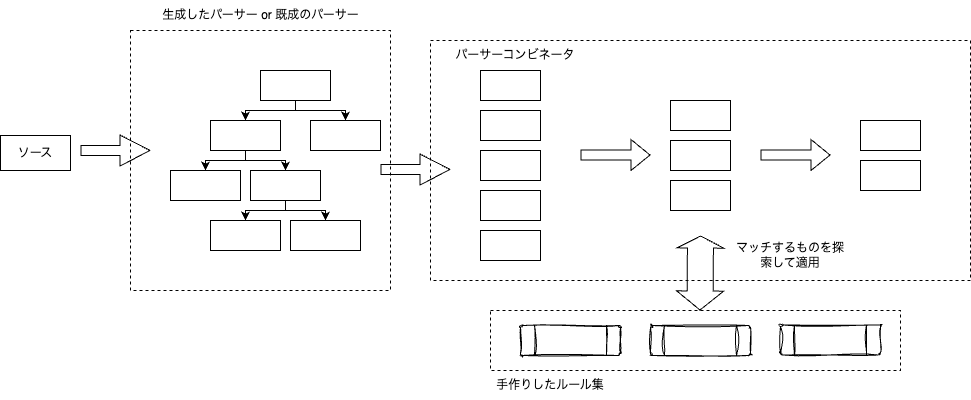
既成のパーサーとパーサーコンビネータを組み合わせてみる
パーサーコンビネータはいつか自作してみたいものの1つではありますが、パーサー・コンビネーター・ライブラリ「takenoco」入門という記事を見て興味を持ちました。文字列ではなく「任意の型のスライスの汎用的なパーサー群」が提供されている点が気になりました。これを使えば、既存のパーサーで字句解析し、その後の構文木の解釈フェーズだけはパーサーコンビネータに任せるということができそうです。そうすれば、Markdownの全部の細かい文法ルールを手作りする必要はなくなり、自分に興味のある文法要素の組み合わせだけを記述すればよくなります。
takenoco以外だとこのようなオブジェクトのインタフェースはないですが、既存のパーサーで字句解析したあとに、JSONLにでもしてあげて、その後パーサーコンビネータに入力してあげれば良さそうなので、この考え方は応用できるんじゃないかと思います。
Goで実際に実装してみる
Markdownのパースは安心と信頼と実績のgoldmarkを使ってみます。
goldmarkとtakenocoを接続する準備
まずはmarkdownファイルをパースして抽象構文木を取り出します。
md := goldmark.New(
goldmark.WithExtensions(extension.GFM),
)
f, err := os.Open(filePath)
source, err := io.ReadAll(f)
doc := md.Parser().Parse(text.NewReader(source))
|
takenocoは、AstSliceという1次元のトークン列に対して変換ロジックを適用していくことになります。AstSliceの各要素にはいくつかの属性があります。takenocoのパース処理は「この要素があるよ」という要素を書けば、それにマッチします。ただマッチするだけでは単にツリーの構造チェックでしかないので、マッチした結果を適切なClassとValueを持つAst要素に置き換えていく、というのが基本になります。
Value any: なんでも突っ込める。ここではgoldmarkのASTを入れているType: ノードの種類(ただしここでは標準のstring系APIを使ってないので全部Anyにしている)ClassName string: ノードの種類を表現するテキストAddress Box: 元のデータへの参照(っぽいがここでは使ってないのでnilにしている)SourcePosition SourcePosition: ソースの位置
まずは次のような1つのセクションタイトルのシンプルなMarkdownを考えてみます。
GoldmarkはXML風に表現すると次のような感じの階層構造をもったツリーを返します。位置情報(先頭からのインデックス)はブロック要素しか持っていません。
<document type="document">
<heading type="block" pos="2">
<text type="inline">素晴らしい機能</text>
</heading>
</document>
|
1次元配列にするイメージは次の通りです。木構造はenter/leaveの2つのノードとして表現することで1列にしています。
<document type="enter" />
<heading type="enter" />
<text type="single" />
<heading type="leave" />
<document type="leave" />
|
以下がそのロジックです。ちょっと長いコードに見えますが、定型処理でどのような文章構造でも変化しないコードです。インライン要素はフォーマット情報を落としてテキスト情報だけを抜き出しています。これはtakenocoレイヤーでもできますが、takenocoコードに寄せるのは(本番コードはともかく、このチュートリアル的文章)では複雑になってしまうと見通しが良くなくなってしまうのでこちらでやっています。
type MDNodeType int
const (
SingleNode MDNodeType = iota + 1
EnterBlock
LeaveBlock
)
type MDNode struct {
Node ast.Node
Type MDNodeType
Text string
}
func flattenAST(n ast.Node, source []byte) AstSlice {
var nodes AstSlice
ast.Walk(n, func(n ast.Node, entering bool) (ast.WalkStatus, error) {
if n.Type() == ast.TypeDocument || n.Type() == ast.TypeBlock {
var pos int
var length int
if n.Lines().Len() > 0 {
pos = n.Lines().At(0).Start
length = n.Lines().At(0).Stop - n.Lines().At(0).Start
}
var nodeType MDNodeType
if entering {
nodeType = EnterBlock
} else {
nodeType = LeaveBlock
}
nodes = append(nodes, Ast{
ClassName: n.Kind().String(),
Type: AstType_Any,
Value: &MDNode{
Node: n,
Type: nodeType,
},
Address: nil,
SourcePosition: SourcePosition{
Position: pos,
Length: length,
},
})
} else if entering && n.Kind() == ast.KindText {
nodes = append(nodes, Ast{
ClassName: n.Kind().String(),
Type: AstType_String,
Value: &MDNode{
Node: n,
Type: SingleNode,
Text: string(n.Text(source)),
},
Address: nil,
})
}
return ast.WalkContinue, nil
})
return nodes
}
|
1つのセクションのみを含むMarkdownのパース
まず、最初のステップとして、先ほど挙げたシンプルなMarkdownのパーサーを作成していみます。
最初に単にマッチするだけのコードは次の通りです。FlatGroupは連続した要素の表現になります。
func title() {
return FlatGroup(
ObjClassFn(func(v any) bool {
node := v.(Ast).Value.(*MDNode)
return node.Node.Kind() == ast.KindHeading && node.Node.(*ast.Heading).Level == level && node.Type == EnterBlock
}),
ObjClassFn(func(v any) bool {
node := v.(Ast).Value.(*MDNode)
return node.Node.Kind() == ast.KindText
}),
ObjClassFn(func(v any) bool {
node := v.(Ast).Value.(*MDNode)
return node.Node.Kind() == ast.KindHeading && node.Node.(*ast.Heading).Level == level && node.Type == LeaveBlock
}),
)
}
|
これはマッチしたよ、しかわからないので、変換処理を加えます。Trans()でくくって、2つめにマッチしたあとのAstSliceを作成する変換関数を渡します。Ast{ class: title value: "素晴らしい機能"}というAstに置き換えます。
func title() ParserFn {
return Trans(
FlatGroup(
),
titleTransform,
)
}
func titleTransform(_ ParserContext, asts AstSlice) (AstSlice, error) {
return AstSlice{{
OpCode: 0,
ClassName: "title",
Type: AstType_String,
Value: asts[1].Value.(string),
Address: nil,
SourcePosition: asts[0].SourcePosition,
}}, nil
}
|
これにエラー処理を加えたものが以下のコードです。Firstはorで、最初の要素にマッチします。Errorはエラーです。最初のセクションタイトルにマッチしなければエラーということですね。
func title() ParserFn {
return First(
Trans(
FlatGroup(
),
titleTransform,
),
Error("title not found"),
)
}
|
このように組み立てていくのが基本ステップです。これを増やしていきます。このボトムアップでエラー通知情報を入れられるのがパーサーコンビネータの一番のメリットかなと思います(うまくエラー行を渡す方法はまだ考え中)。
このタイトルのパース関数を組みこんでドキュメント全体のパーサを作りました。パース結果は構造体として情報をまとめます。一番外側のパース関数を実行するとパーサーが手に入ります。
type ParseResult struct {
Title string
}
func document() ParserFn {
return Trans(
FlatGroup(
Start(),
ObjClassFn(func(v any) bool {
node := v.(Ast).Value.(*MDNode)
return node.Node.Type() == ast.TypeDocument && node.Type == EnterBlock
}),
title(),
ObjClassFn(func(v any) bool {
node := v.(Ast).Value.(*MDNode)
return node.Node.Type() == ast.TypeDocument && node.Type == LeaveBlock
}),
End(),
),
documentTransform,
)
}
func documentTransform(_ ParserContext, asts AstSlice) (AstSlice, error) {
return AstSlice{{
OpCode: 0,
ClassName: "result",
Type: AstType_Any,
Value: &ParseResult{
Title: asts[1].Value.(string),
},
Address: nil,
SourcePosition: SourcePosition{},
}}, nil
}
var documentParser = document()
|
今まで作成した要素を組み合わせたものが次のコードです。構文木の要素にルールを適用し、Transに渡した関数を呼び出しつつ、結果の構造体に結果を格納できました。
slice := flattenAST(doc, source)
pc := NewObjectParserContext(slice)
matchResult, err := documentParser(*pc)
if matchResult.MatchStatus == MatchStatus_Matched {
result := matchResult.AstStack[0].Value.(*ParseResult)
fmt.Println(result)
} else {
fmt.Printf("Failed to parse:\n %s\n", err)
}
|
ちょっとしたヘルパー
今まではtakenocoのAPIをそのまま使っていましたが、goldmarkのAstがValueに入っている前提なのでちょっとしたラッパーを作ると便利になります。
func NodeFn(callback func(nodeType MDNodeType, node ast.Node, text string) bool) ParserFn {
return ObjClassFn(func(v any) bool {
node := v.(Ast).Value.(*MDNode)
return callback(node.Type, node.Node, node.Text)
})
}
|
パラグラフの中のインライン装飾はフラット化のときに削除するようにしていましたが、パラグラフの中にTextノードが複数個並ぶ構造になるため、それを1つにまとめるパーサのinlineText()を定義します。
func inlineText() ParserFn {
return Trans(
OneOrMoreTimes(NodeFn(func(nodeType MDNodeType, node ast.Node, text string) bool {
return nodeType == SingleNode
})),
inlineTextTransform,
)
}
func inlineTextTransform(_ ParserContext, asts AstSlice) (AstSlice, error) {
var builder strings.Builder
for _, ast := range asts {
builder.WriteString(ast.Value.(Ast).Value.(*MDNode).Text)
}
return AstSlice{{
OpCode: 0,
ClassName: "text",
Type: AstType_String,
Value: builder.String(),
Address: nil,
SourcePosition: SourcePosition{},
}}, nil
}
|
こちらは複数のパラグラフを1つにまとめます。class引数の変数をAstのClassNameに指定し、Valueはパラグラフごとの文字列のスライスを設定します。
func paragraph(class string) ParserFn {
return Trans(
ZeroOrMoreTimes(
Trans(
FlatGroup(
NodeFn(func(nodeType MDNodeType, node ast.Node, text string) bool {
return node.Kind() == ast.KindParagraph && nodeType == EnterBlock
}),
inlineText(),
NodeFn(func(nodeType MDNodeType, node ast.Node, text string) bool {
return node.Kind() == ast.KindParagraph && nodeType == LeaveBlock
}),
),
singleParagraphTransform,
),
),
paragraphTransform(class),
)
}
func singleParagraphTransform(_ ParserContext, asts AstSlice) (AstSlice, error) {
return AstSlice{asts[1]}, nil
}
func paragraphTransform(class string) func(_ ParserContext, asts AstSlice) (AstSlice, error) {
return func(_ ParserContext, asts AstSlice) (AstSlice, error) {
var result []string
for _, ast := range asts {
result = append(result, ast.Value.(string))
}
return AstSlice{{
OpCode: 0,
ClassName: class,
Type: AstType_String,
Value: result,
Address: nil,
SourcePosition: SourcePosition{},
}}, nil
}
}
|
先ほどは手で作成したタイトル処理ですが、共通化したヘルパーを作ります。パラグラフにつける名前を明示したいだけでASTが持つ情報が欲しくない場合と、さきほどのタイトルのように情報が欲しい場合があります。また、存在を省略可能なセクションとかもあるでしょう。その辺りを引数で設定できるようにしています。
type RequiredFlag int
const (
Required RequiredFlag = iota + 1
NotRequired
)
func heading(class string, level int, required RequiredFlag, prefix ...string) ParserFn {
parser := Trans(FlatGroup(
NodeFn(func(nodeType MDNodeType, node ast.Node, text string) bool {
return node.Kind() == ast.KindHeading && node.(*ast.Heading).Level == level && nodeType == EnterBlock
}),
inlineText(),
NodeFn(func(nodeType MDNodeType, node ast.Node, text string) bool {
return node.Kind() == ast.KindHeading && node.(*ast.Heading).Level == level && nodeType == LeaveBlock
}),
), headingTransform(class, prefix...))
if required == NotRequired {
return parser
}
return First(
parser,
Error(fmt.Sprintf("'%s' header is required", class)),
)
}
func headingTransform(class string, prefix ...string) func(_ ParserContext, asts AstSlice) (AstSlice, error) {
return func(_ ParserContext, asts AstSlice) (AstSlice, error) {
text := asts[1].Value.(string)
if len(prefix) > 0 {
if !strings.HasPrefix(text, prefix[0]+": ") {
return nil, fmt.Errorf("%s heading should have '%s: ' prefix, but not ('%s'), %w", class, prefix[0], text, ErrTransform)
}
return AstSlice{{
OpCode: 0,
ClassName: class,
Type: 0,
Value: strings.TrimPrefix(text, prefix[0]+": "),
Address: nil,
SourcePosition: asts[0].SourcePosition,
}}, nil
}
if text != class {
return nil, fmt.Errorf("header should be '%s', but '%s' %w", class, text, ErrTransform)
}
return AstSlice{}, nil
}
}
|
ちょっと複雑なドキュメントのパース
次のようなドキュメントのパースをしたいと思います。Caveats, Referencesというセクションは省略可能とします。
# Design Document: 2WaySQL
## Goal
SQLを柔軟にする
過度なラッパーにしてSQLを隠すことはしない
## Background
SQLはみんな読んだり書けるものとする
ちょっとした検索条件の有無でSQLファイルが大量にできてしまうのを防ぐ
テストのためにSQLファイルとして正当なものであってほしい
## Overview
SQLを生成するテンプレートエンジン
コメントでディレクティブを表現
## Detailed Design
変数置き換えのディレクティブがある
条件の有無でコードブロックを丸ごと取り除くディレクティブがある
## Caveats
PostgreSQLのprepareは複数回実行されないとキャッシュされないためバリエーションが増えるほどキャッシュされにくくなる
プリペアードステートメントはコネクションごとにキャッシュされるためコネクションが増えるとメモリ使用量が増える
|
先ほど作ったヘルパーを使ってトップレベルのdocument()を書き換えます。document()一箇所で複雑なMarkdownもパースできるようになりました。
type ParseResult struct {
Title string
Description []string
Goal []string
Background []string
Overview []string
DetailedDesign []string
Caveat []string
Reference []string
}
func document() ParserFn {
return Trans(
FlatGroup(
Start(),
NodeFn(func(nodeType MDNodeType, node ast.Node, text string) bool {
return node.Type() == ast.TypeDocument && nodeType == EnterBlock
}),
heading("title", 1, Required, "Design Document"),
paragraph("description"),
heading("Goal", 2, Required),
paragraph("goal"),
heading("Background", 2, Required),
paragraph("background"),
heading("Overview", 2, Required),
paragraph("overview"),
heading("Detailed Design", 2, Required),
paragraph("detailed-design"),
ZeroOrOnce(
FlatGroup(
heading("Caveats", 2, NotRequired),
paragraph("caveats"),
),
),
ZeroOrOnce(
FlatGroup(
heading("References", 2, NotRequired),
paragraph("references"),
),
),
NodeFn(func(nodeType MDNodeType, node ast.Node, text string) bool {
return node.Type() == ast.TypeDocument && nodeType == LeaveBlock
}),
End(),
),
documentTransform,
)
}
func documentTransform(_ ParserContext, asts AstSlice) (AstSlice, error) {
result := &ParseResult{}
for _, ast := range asts {
switch ast.ClassName {
case "title":
result.Title = ast.Value.(string)
case "description":
result.Description = ast.Value.([]string)
case "goal":
result.Goal = ast.Value.([]string)
case "background":
result.Background = ast.Value.([]string)
case "detailed-design":
result.DetailedDesign = ast.Value.([]string)
case "caveats":
result.Caveat = ast.Value.([]string)
case "references":
result.Reference = ast.Value.([]string)
}
}
return AstSlice{{
OpCode: 0,
ClassName: "result",
Type: AstType_Any,
Value: result,
Address: nil,
SourcePosition: SourcePosition{},
}}, nil
}
|
まとめ
今回の実装では、文章構造はdocument()という関数の中に集約されているため、ちょっとした構造はこの関数をカスタマイズすれば対応可能です。可能であれば、Markdown形式で構造も定義してこのdocument()関数自体を動的に実行時に構成とかできて、結果をテンプレートエンジンに渡してテキスト生成とかすると、Goをまったく書かずに構造化Markdownを使った情報管理ができる、みたいなことも可能なんじゃないかと思います。
このことも含めて今後やってみたいことリストを次に書いておきます。
document()をテキストテンプレートから動的生成- わかりやすいエラーメッセージ
- リスト、コードフェンス、テーブルのパース
- テンプレートをもとにしたVSCodeの動的エラーチェック
- 将来的にはANTLRのルール定義からパーサーコンビネータのコードを生成
これぐらいの構文解析であれば、正規表現で書いても簡単だよ? と思われる方も多いと思います。しかし、コードブロックの中の#記号は表題として扱わないなどの例外処理を入れていくとすぐに複雑なコードになってしまいます。安全側に倒していくと、きちんとしたパーサーが必要になって、今回のようなロジックが必要になります。
もちろん、文法とは別に、書き方のガイドラインを厳密に作ってそれに従わないのはエラーとするという方法もありますが、そのようなツール都合のルールは利用者にとってストレスです。文法上正しいテキストは余計な制約なく利用したいと思うのが人情です。