
Terraform 連載2025の5日目です。
Terraformは、インフラ構築をコードで管理できる強力なツールですが、BigQueryのデータ管理においては、特有の課題に直面することがあります。本記事では、TerraformでBigQueryを扱う際に陥りやすい落とし穴と、データ管理の品質を高めるための対策について、サンプルコードを交えながら解説します。
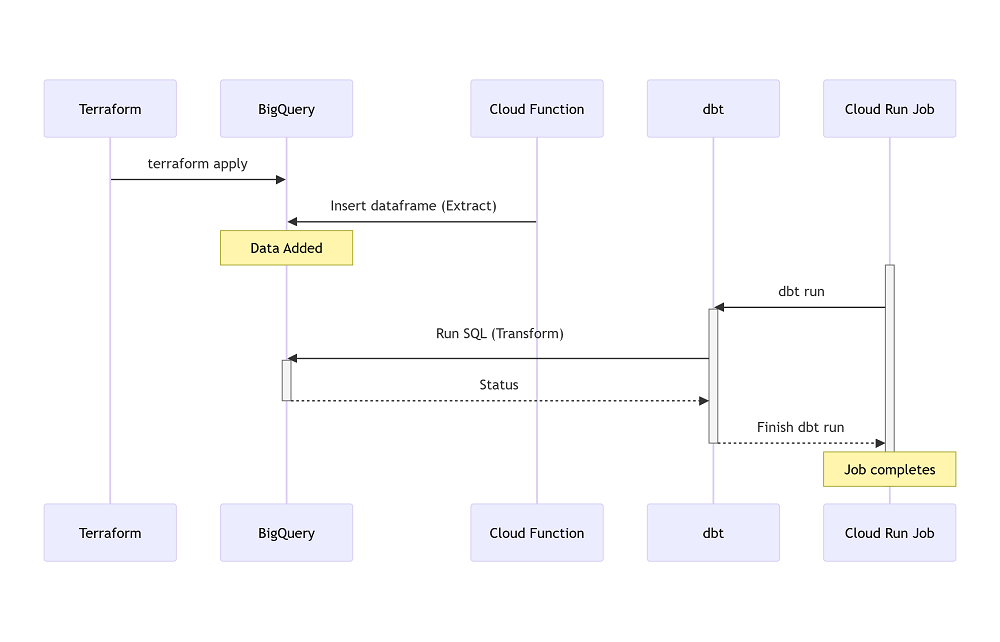
ちなみに、以下の構成の前提で解説するため、事前にご了承ください。
1. テーブルのライフサイクル管理
課題: テーブルの意図しない変更によるデータ損失
Terraformは、リソースのライフサイクルをコードで管理できますが、以下のいくつのケースの際に、テーブルを再度自動作成されるため、意図しないデータ損失が発生します。
- Terraform上のスキーマ変更を適用したとき
- Cloud Functionなどでデータを洗い替えされ、再度
terraform applyを実行されたとき(BigqueryAPIのJobConfigによって事前に防ぐことができます。詳しくは3.の項で)。
対策
lifecycleメタ引数を利用して、prevent_destroyを設定し、意図しない削除を防止します。
ただし、このタグの関係で、意図したスキーマ変更を実行する際に、Instance cannot be destroyedエラーが発生するために、プロジェクトを立ち上げる初期は、スキーマ変更が頻繁に発生する場合、おすすめしません。
ある程度で変更頻度が落ち着いた頃、あるいは、データの保持が必要になった頃に導入することがおすすめです。
resource "google_bigquery_table" "my_table" { dataset_id = google_bigquery_dataset.my_dataset.dataset_id table_id = "my_table" lifecycle { prevent_destroy = true } #その他の設定 } |
2. スキーマ定義と管理
課題: スキーマ定義の不整合、変更に伴うデータ移行の複雑さ
Terraformで管理する場合、スキーマ定義の不整合や変更に伴うデータ移行が複雑になることがあります。体系的にスキーマを管理する必要があります。
対策
各スキーマをTerraform内でベタ書きでなく、Terraformのfile関数を利用してJSONスキーマを外だしで管理すること。
また、for_each機能を利用して、各テーブルの差分(別々に管理したいプロパティ)のみをパラメータ化し、テーブルの設定に一貫性をもたせます。
locals { table_setting = toset([ { dataset_name = "my_dataset" table_name = "my_table" description = "テストテーブル" # 別々に管理したいテーブルのパラメータのみ }, # その他のテーブル ]) } |
resource "google_bigquery_table" "my_table" { for_each = {for k, v in local.table_setting : k.table_name => v } dataset_id = each.value.dataset_name table_id = each.value.table_name schema = <<EOF ${file("${path.root}/schemas/${each.value.dataset_name}/${each.value.table_name}.json")} EOF # その他固定化する項目 } |
3. スキーマの変更管理(望ましくない変更がないように)
課題: データの不整合、品質劣化
BigQueryのスキーマは柔軟に変更できますが、その反面、テーブルにインサートするとき、意図しないスキーマ変更が発生します。
一例として、BigqueryAPIで以下のJobConfigで設定したときに、データだけでなく、スキーマまで上書きされる現象が起こります。
writeDisposition = WRITE_TRUNCATEかつautodetect = True
詳しくは以下のリンクを参考しくてださい。
- python - Google BigQuery WRITE_TRUNCATE erasing all data - Stack Overflow
- Job | BigQuery | Google Cloud
また、Terraformでカラムの型を定義する際、下記の例で示しているように、Bigqueryでaliasとして定義されたData Typeにもかかわらずに、自動的に右側の型に変換されることがあります。そして再度terraform applyを実行される際に、Terraform側で差分として認識されてしまいます。
‐ INT64でなく、INTEGER
‐ FLOAT64でなく、FLOAT
‐ DECIMELでなく、NUMERIC
対策
Terraformのgoogle_bigquery_tableリソースを利用して、データ型、制約、説明などのメタデータを検証したうえで適切に定義します。また、定義可能な型の範囲もプロジェクトごとにしっかり決めておくこともおすすめです。
[ |
4. パーティショニングとクラスタリング
課題: パフォーマンス劣化、コスト増大
BigQueryのパーティショニングとクラスタリングは、クエリのパフォーマンスとコスト効率を向上させる重要な機能ですが、Terraformでの設定を誤ると、パフォーマンス劣化やコスト増大を招く可能性があります。
対策
クエリのパターンに合わせて、適切なパーティションキーとクラスタリングキーを選択し、パーティション分割の粒度を適切に設定し、不要なスキャンを減らします。
Terraformのtime_partitioningとclustering引数を適切に設定し、パフォーマンスとコストを最適化します。順番も、先にパーティションを設定してから、クラスタリング。また、2025年4月時点、パーティションの上限が10000で、おおよそ27年分(10000÷365日)のデータを保存できます。
https://cloud.google.com/bigquery/quotas?hl=ja#partitioned_tables
resource "google_bigquery_table" "my_partitioned_table" { dataset_id = google_bigquery_dataset.my_dataset.dataset_id table_id = "my_partitioned_table" time_partitioning { type = "DAY" field = "date" } clustering { fields = ["name"] } } |
5. 権限管理とセキュリティ
課題: 意図しないデータアクセス、セキュリティリスク
BigQueryの権限管理は、データセキュリティ・データ活用の面において非常に重要です。とはいえ、必ずしもデータオーナーがコードベースで権限を管理できるわけではありません。Terraformでの初期設定をどこまですればいいか、非常に悩ましいことです。設定を誤ると、意図しないデータアクセスやセキュリティリスクを招く可能性があります。
対策
データオーナーがコードまでいじれないため、各テーブルに対して、テーブルグループを事前に設けることによって、データ閲覧者をあえてTerraformでのデータ管理から切り離します。
そして、Terraformの中で、google_bigquery_dataset_accessまたはgoogle_bigquery_table_iam、リソースを利用して、最小権限の原則に従って各テーブルグループに対して、対応するテーブルの閲覧権限のみを付与します。
初期設定として、テーブルグループの中で自動的に規定した各データオーナー部門のみを招待し、日頃の運用上、データオーナーがコードやリポジトリーではなく、グループ画面だけでデータ閲覧者の管理を行えるようになります。
resource "google_bigquery_dataset_access" "my_dataset_viewer" { dataset_id = google_bigquery_dataset.my_dataset.dataset_id role = "roles/bigquery.dataViewer" user_by_email = "dataset_id@my-domain.com" } |
まとめ
Terraformは、BigQueryのデータ管理を効率化するための強力なツールですが、適切な設計と運用が不可欠です。本記事で紹介した5つのよくある落とし穴とサンプルコードを参考に、Terraformを活用してBigQueryのデータ管理を最適化し、データ品質とセキュリティを向上させましょう!