はじめに
最近仕事でLLMサーバーを構築することになりました。
雰囲気をお伝えすると、HuggingFaceの transformers をFastAPIのようなフレームワークでラップしたものです。
from fastapi import FastAPI, Request |
curl -X POST http://localhost:8000/generate \ |
これらをECSでホストするべく Python のベースイメージでコンテナ化したのですが、LLM関連のパッケージをインストールしたコンテナイメージは非常に大きくなります。
例えば、 huggingface/transformers-pytorch-gpu は約10GBです。
# nerdctl images |
中身を調べてみるとcudaやpytorchなどが重量級です。
4.8G /usr/local/cuda-12.6 |
さらに私の場合、モデルの重みをイメージに同梱していたためサイズが肥大化していました。コンテナイメージサイズの削減を頑張るべきかもしれません。例えば思い付きですが、モデルの重みはイメージに含めずにボリュームとして切り出してマウントするなどが考えられます。
しかし、今回はECSなどでコンテナの起動を高速化することを目標に、イメージを遅延して読み込むLazy-pullingな技術に目を向け、LLMコンテナに対し効果があるのかどうかを検証します。
CNCF連載 ということで取り上げるのはGraduatedなプロダクトであるcontainerdです。
containerdとSnapshotter
docker runしたときの処理の流れをざっくりおさらいすると、
- イメージを取得して展開
- ファイルシステムをホストと分離
- いろいろ名前空間を分離しつつプロセスを起動する
…です。この上半分くらいを担当するのがcontainerdに代表されるCRIランタイムというものです。DockerやKubernetesの影にいます。
containerdの機能はpluggableです。例えば 下半分くらいを担当するOCIランライムはOCIランタイム仕様に則っていれば切替可能です。
今回着目するイメージの展開やファイルシステムを管理するコンポーネントはSnapshotterと呼ばれ、これも差し替え可能になっています。
デフォルトはoverlayfsですが、lazy pull対応のsnapshotter(Remote Snapshotterといいます)に差し替えることでその機能を利用する形です。
Snapshotterはデーモンとして起動させunix domain socketごしにcontainerdと通信します。
Lazy Pullingとは
通常のコンテナ起動では、イメージ全体をダウンロードしてから展開・プロセス起動という流れですが、コンテナ起動時に全てのファイルが必要なわけじゃないよね、という観察があります。
この手のツールのREADMEでよく参照されているHarter et al.によると、コンテナ起動時間の76%がイメージダウンロードに費やされている一方、実際にコンテナが開始するのに必要なデータは平均で6.4%だそうです。
なので、Remote Snapshotterは初回起動時は必要なファイルだけをpullしてプロセスを開始してしまいます。レジストリはFUSEを介してマウントしておき都度取得する、という仕組みです。
ところでコンテナイメージのレイヤーのフォーマットであるtar.gzにおいては、全てのファイルを展開せずに特定のファイルのみにアクセスし取得する、ということができません。イメージのレイヤー内のすべてのファイルがtarにアーカイブgzipで圧縮されており団子状態なためです(Seekableではないという言い方をします)。
ということでRemote Snapshotterを使うにはコンテナイメージをSeekableなイメージに変換する必要があったり、どのファイルがどのレイヤーのどのオフセットに含まれているのかのインデックスをメタデータとして持たせたりする必要があります。
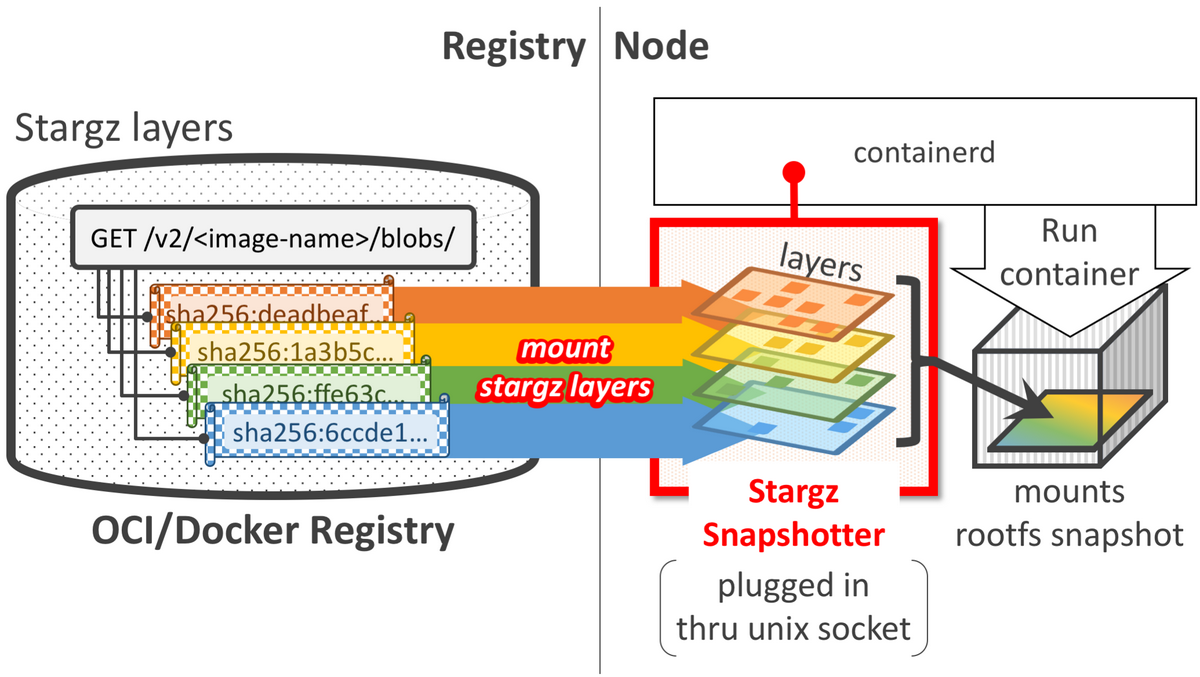
Containerd Stargz Snapshotter Plugin Overview
今回検証するのは以下の2つです。
- eStargzというイメージフォーマットでlazily-pullableを実現します
- AWSが提供していてECS・Fargateで使えます
- AWSのブログはこちら
実験してみた
LLMで文を生成するスクリプトをコンテナ化し、レジストリにpushしておき、以下の3パターンのsnapshotterでdocker runの時間を計測しました。
- overlayfs: 通常のsnapshotter
- stargz-snapshotter
- soci-snapshotter
検証環境構築
今回の検証環境はこんな感じです。
docker runするホスト
- EC2
- m5.large
- Ubuntu
- 東京リージョン
コンテナレジストリ
- ECR
- 東京リージョン
今回LLMを実行しますが、GPUは使わないことにしました。
containerdとそのクライアントのnerdctl(docker CLIのようなもの)などをインストールします。このあたりはcontainerdのgetting startedの手順通りです。
https://github.com/containerd/containerd/blob/main/docs/getting-started.md
snapshotter設定をstargz-snapshotterを例にざっくり記載すると、まずsnapshotterをインストールしてデーモンとして起動します。
tar -C /usr/local/bin -xvf stargz-snapshotter-${version}-linux-${arch}.tar.gz containerd-stargz-grpc ctr-remote |
conatinerdのconfigを設定してデーモンを再起動します。
version = 2 |
systemctl restart containerd |
soci-snapshotterも大体同様です。
実験用のコード
LLMのモデルをロードし、文を生成させるだけのスクリプトを用意します。
from transformers import pipeline |
コンテナのエントリポイント用のスクリプトを用意します。イメージをpullする速度とPython実行の速度を分けて計測したい意図でshellscriptでラップすることにしました。
|
以上をコンテナ化します。ここでLLMのモデルをあらかじめpullしてイメージに同梱しておきます。アンチパターンな気もしますが…。
FROM python:3.11-slim |
ちなみにイメージサイズは5GBくらいでした。
nerdctl images |
それぞれのsnapshotterに対応させるためイメージフォーマットの変換や、インデックスの作成します。
# stargz フォーマットに変換 |
計測項目
以下を計測します。
- イメージpull + containerd初期化時間(
time nerdctl run) - コンテナ内でLLMが起動して実行終了するまでの時間(entrypoint.shで計測)
各snapshotterでの実行コマンドは以下の通りです。
# overlayfs(通常) |
結果
結果はこんな感じでした。
| snapshotter | pull時間 | LLM実行時間 | 合計時間 |
|---|---|---|---|
| overlayfs | 101.8s | 9.6s | 111.4s |
| stargz-snapshotter | 1.4s | 195.1s | 196.5s |
| soci-snapshotter | 0.5s | 73.5s | 74.0s |
sociは速くなってますが、stargzはむしろ遅くなってますね!
結局イメージサイズに対し支配的なcudaやpytorch系のライブラリへのアクセスが必要なので、総実行時間としてはガンっと速くなったりはせずむしろ遅くなるケースもあるということなんでしょうか。チューニングの余地はありそうです。
検証は若干いい加減なので追試が待たれます。
ちなみに echo hello みたいなコマンドを実行させるケースだと stargz、sociは一瞬で終了しました。試してないですがWebサーバーの起動などだと、遅延読み込みの嬉しさが感じられるのかもしれません。
# stargz |
おわりに
LLMサーバーをホストするにあたって、コンテナ起動を高速化するLazy-pulling技術について検証しました。sociはAWSで導入しやすいし効果もありそうなのでいいなと思いました。
本ブログのネタの構成には以下のKubeCon + CloudNativeCon Japan 2025セッションを参考にしました(現地参加しておらず見ていないのですが)。
KubeConセッションと同じ内容のブログ記事も公開されています。