はじめに
こんにちは、TIG所属インフラエンジニアの市川です。
インフラ入門という記事のテーマについてvol.2との棲み分けをどうしようかと思っていたのですが、前職がゴリゴリのネットワークエンジニアということもあり、折角なのでネットワークを深掘りしたいと思います。
クラウド全盛期の今でも社内ネットワークや既存のオンプレシステムなどネットワークなしにシステムを語ることはできません。いつでも繋がるネットワークを構築するために、サービスをエンドユーザー様に快適に使っていただくために、冗長化設計は避けて通れません。とは言え、ネットワークは簡単に作り直せない分、古き良き? 構成が残ったままになりがちです。
お客様先でもまだまだ課題となっている冗長化構成の改善について、打ち合わせについていった新人さんが「なんだ、、、この呪文は、、、」とならないための入門記事をしたためようと思います。
⚠️[WARNING]この記事はとても長いです⚠️
過去記事について
- インフラ入門vol.1:インフラ全般に興味を持ってもらうためのアツい記事です。
- インフラ入門vol.2(ネットワーク):ネットワークって何さ? から仕様検討の上での入門知識が書かれた記事です。
- インフラ入門vol.3(ネットワーク冗長化構成):この記事。冗長構成にスポットライトをあてた若干ニッチな記事です。
なぜ冗長化???
そもそもなぜ冗長化なのでしょう。というか冗長って何でしょうか。
Wikipediaによると…
冗長化(じょうちょうか)とは、システムの一部に何らかの障害が発生した場合に備えて、障害発生後でもシステム全体の機能を維持し続けられるように、予備装置を平常時からバックアップとして配置し運用しておくこと。冗長化によって得られる安全性は冗長性と呼ばれ、英語ではredundancyと呼ぶ。
常に実用稼動が可能な状態を保ち、使用しているシステムに障害が生じたときに瞬時に切り替えることが可能な仕組みを持つ。障害によってシステムが本来の機能を失うと、人命や財産が失われたり、企業活動が大きな打撃を受けるような場合には、冗長性設計が必須となっている。
ナルホド。1段落目にとっても重要なことが書いてあります。
ネットワークが、サーバが、故障しました!
→ ヤバい! 予備がない!
→ 発注して、データセンタへの設置のために色々申請をして。
→ バックアップがあればそこから戻して・・・あ! 機器の構成管理してない!
→ 手動でコンフィグのインストールして・・・。
—— おそらくこの時点で2, 3ヶ月はかかっているでしょう。
何故こうなったか説明を求められるでしょうし、もしかしたら賠償になるかも。人命に関わることもあるかもしれません。まぁ、この例は流石に杜撰すぎますが。
今やネットワークインフラやその上で提供される数多のサービスは電気や水道のように生活になくてはならないライフラインです。一般的な日本語では冗長は「無駄」という意味合いがありますが、冗長設計をすることは決して無駄でなく、お客様とその快適な生活を守るために必要な最低限考慮すべき事項です。
何をどこまでやるのか
冗長化とはSPOF(Single Point of Failure / 単一障害点)を排除することだと認識しています。
SPOF排除における基本的な考え方は、
- 負荷分散及び障害時の迂回経路を提供するActive/Active構成
- 障害時に自動で切り替わるような迂回経路を提供するActive/Standby構成
上記はホットスタンバイといい、冗長機器は常に稼働し続け、「自動」での切り替わりを提供します。
一般にデータセンタや中・大規模な顧客拠点(オフィスネットワーク)、保守員のいない遠隔地ではこの構成が取られます。
また、小規模な顧客拠点などではコールドスタンバイという構成を取ることもあります。ホットスタンバイなActive/Standby構成をとった場合、Standbyの機器に通信がやってくるのは障害時かメンテナンス時くらいです。
もしかしたらラックのスペースがないかもしれませんし、電気が足りないかも・・・。お金もかかる。そういう場合には予め本番機同等の設定をした予備機を用意することで障害時に差し替えを行い、障害時間をある程度短縮するといった手法が取られます。
さて、上記の構成が取られることはわかりましたが、実際問題どこまで対策すればよいのでしょうか。
- LANケーブルや光ケーブル、電源を複数持たせればOK?
- 機器筐体そのものを複数もたせる?
- この際回線も複数もたせる? 衛星回線用意する?
- 回線事業者分けたり、通る収容局分けたり、収容される機器分けたり!?(どこまで対応してくれるかですが)。
- 都内数カ所とかにデータセンタを複数構築する?
- 大規模災害起きたらだから、BCP(Business continuity planning / 事業継続計画)拠点も作る?
インフラ入門vol.2(ネットワーク)にもありますが、「機械の故障等による停止はどの程度まで許容できるのか」が重要なポイントです。モノの納期や金銭的問題、例えばBCP発動時の手順の整備・訓練など対策を講じれば講じるほど運用は難度を増します。
非機能要件定義の段階で十分にお客様と調整を行いましょう。
※よく打ち合わせなんかでMTBFとかMTTRなんて言葉も出てくるので、覚えておきましょう。
- MTBF: Mean Time Between Failures / 平均故障間隔
- MTTR: Mean Time To Repair / 平均復旧時間
具体的な設計について
前置きが長くなりました。
さて、冗長構成はレイヤごとに分けて考えるとたくさんやることがあります。
よくインフラ屋さんが使う言葉にOSI参照モデルというものがあります。いわゆるネットワークの統一規格で下記の7層に分けることができます。
| レイヤ | 層名称 | 役割 |
|---|---|---|
| 1 | 物理層 | LANケーブル、光ケーブル、無線などの信号規約などを提供する |
| 2 | データリンク層 | 機器間のデータ伝送や経路選択を提供する |
| 3 | ネットワーク層 | 複数のネットワークにまたがった経路選択を提供する |
| 4 | トランスポート層 | ネットワーク接続された端末間のエンドツーエンドの通信を提供する |
| 5 | セッション層 | 通信の開始から終了の規定を提供する |
| 6 | プレゼンテーション層 | 文字コードや圧縮形式、暗号化の方法などを提供する |
| 7 | アプリケーション層 | サービスプロトコル(HTTP/FTPなど)にネットワーク機能を提供する |
ここからはそれぞれのレイヤごとに対策を見ていきましょう。
※筆者はCisco機器を扱うことが多かったので、Cisco用語がそれとなく出てきます。あしからず。
レイヤ1(物理層)
※実際は信号規約なのでアレですが広義に捉えます。広い心で。
電源冗長(RPS / Redundant Power Supply)
ネットワーク機器やサーバにはモジュラタイプの電源を複数搭載可能なモデルがあります。
筐体(機械)の本体を開けたりドライバーがなくても引っこ抜いて差し込む作業だけで電源の交換が可能です。
RPSを利用するなら最低限電源を取得する分電盤もPS(Power Supply)ごとに分けるようにしましょう。
FAN冗長
コレは割とオマケですが、サーバの中には冗長FANを搭載できるモデルがあります。
熱で死んでいった機械をたくさん見てきたので、CPUぶん回す処理が多いことがわかっていたら備えておきましょう。
そもそも空調設計的なものもかかわってきますが。
レイヤ2(データリンク層)
Teaming / Link Aggregation
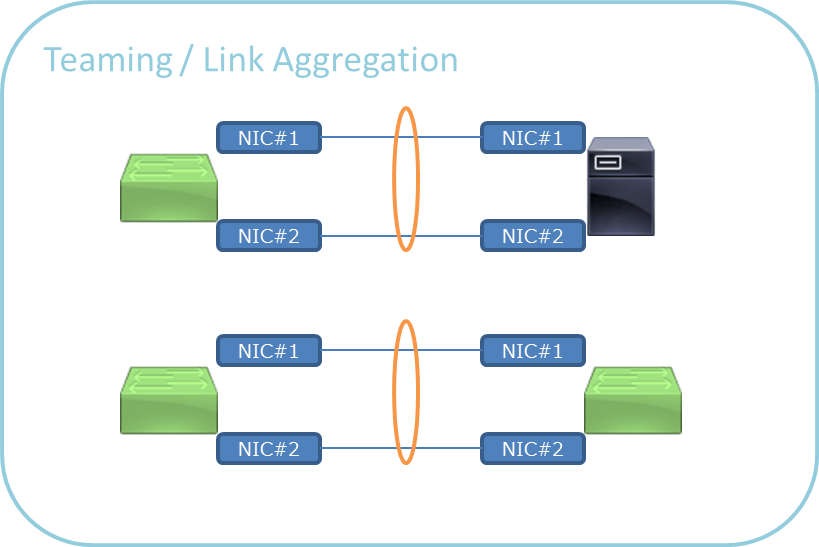
NIC(ネットワークインタフェースカード)を複数搭載した機器同士の物理リンクを束ねて一本の物理リンクとして取り扱う機能で、NICやケーブルの障害対策、あるいは負荷分散のために利用されます。
ちなみにドキュメントに記載された名称がベンダーによって違います。
- Windows系 → チーミング(Teaming)
- Linux系 → ボンディング(Bonding)
- Cisco系 → イーサチャンネル(Ether channel) ※Port channelと呼ぶことも。
- その他(1) → リンクアグリゲーション(Link Aggregation) ※この呼び方をよく使っていました。LAGですね。
- その他(2) → ポートトランキング(Port trunking) ※ProCurveなどがこの呼び方。
また、束ねるケーブルがFastEther(100Mbps)だとFEC、GigabitEther(1Gbps)だとGECとか言ったりします。
重要なのが、サーバではNICそのものの障害、L2SW/L3SWではASIC(Application Specific Integrated Circuit / スイッチング用の専用回路)の障害、シャーシ型の場合はスイッチングモジュールの障害を念頭に置く必要があります。
せっかく冗長化しててもPCIeスロットが同じNICを使ってたり、同じASICやスイッチングモジュールに所属するポートを利用していては可用性が低下します。サービスレベルによっては上記のような点もしっかり抑えておきましょう。
【動作モード】
Teaming / Link Aggregationでは静的あるいは動的に同じグループとして束ねられるポートを選択します。
また、ややこしいことにこのモード次第で負荷分散方式が変わったりします。
「スイッチに依存しない」モード
- 負荷分散を行わないActive/Standby構成(フォールトトレランス)やActive/Active構成でもサーバから送信されるトラフィックのみ負荷分散を行うモード。
「静的 / static」モード
- Active/Active構成で送受信ともに負荷分散を行うが、機械にネゴシエーションをさせず、手動で割当を決める方式。
- 正直後述のLACPに対応してるなら選定することはほぼないかなという所感。
「動的 / LACP」モード
- Active/Active構成で送受信ともに負荷分散を行い、障害時にメンバーポートをLAG(Link Aggregation Group)から切り離します。
- Cisco独自のPAgPというモードもありましたが、機器を選ぶので選定することはないはずです。
【ハッシュポリシー】
負荷分散の際に何を基準にして分散するか、を選択できます。ちょっと脇道なので、サラッと説明しますが、Layer2、Layer2+3、Layer3+4などの種類があります。詳しくはRHELのドキュメントに・・・
推奨はLayer3+4ですが、IPパケットフラグメントなど無視できない問題があったりするので、Layer2+3を選ぶことが多い印象です。
スパニングツリー(Spanning Tree)
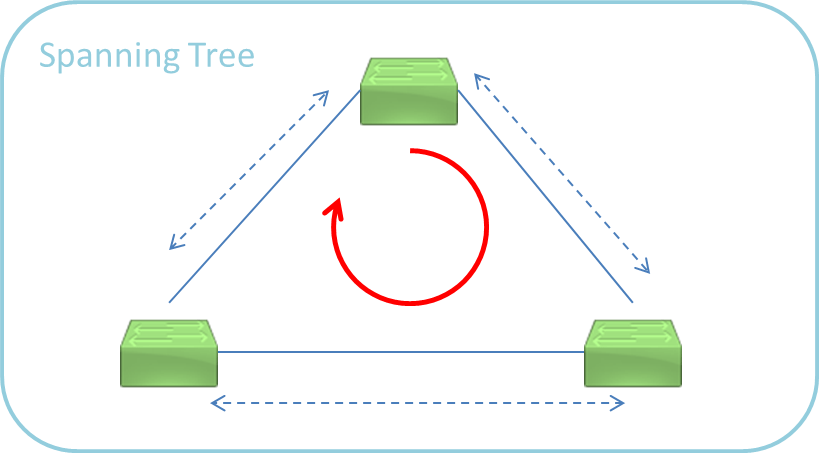
L2スイッチでは通常、受信したフレームの宛先が不明な場合など特定の状況下で、一旦すべてのポートにそのフレームを転送します(フラッディング)。
上図のようにその動作を円環(ループ構成)で行ったらどうなるでしょう。
フレームはぐるぐると機器間を回り続け、ネットワークが使用不可になってしまいます(ブロードキャストストーム)
これを防ぐためのプロトコルがSpanning Tree Protocolと呼ばれるものです。
簡単に説明すると下図のように「利用可能な経路の1つをバックアップ用として利用不可にすることでループ構成を排除する」というものになります(いくつかのルールによって木構造を構成します)。。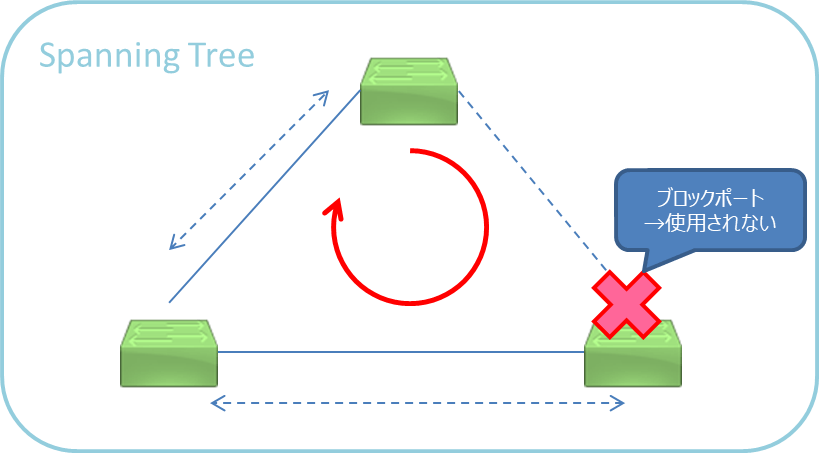
非常に単純なプロトコルなのですが、ベンダーごとの(というかCiscoの)独自実装や既存機器の設定によって影響を受けることもあり、数多くのネットワークエンジニアを泣かせた機能だと(勝手に)思っています。
STP関連のプロトコルは実装は複数あり、
- CST(Common Spanning Tree): すべての仮想LAN(VLAN)で同じ木構造を取る。
- PVST+(Per Vlan Spanning Tree Plus):各VLANで個別の木構造を取ることが可能。
- RST(Rapid Spanning Tree):CSTの高速化版。障害発生時最大50秒の通信断が発生していたが、RSTPでは1秒未満に短縮。
- RPVST+(Rapid Per Vlan Spanning Tree Plus):PVSTの高速化版。障害発生時最大50秒の通信断が発生していたが、RPVST+では1秒未満に短縮。
- MST(Multiple Spanning Tree):RPVST+と似た実装。設計は複雑になりがちだが、RPVST+より負荷が軽く、効率が良い。
遅いCSTやPVST+を積極的に採用することはないですが、小型機はこれらしかサポートしてない場合もあります。
そして厄介なことにSTPトポロジ内に一個でもCSTやPVST+が混ざっていると、全体がそちらに引っ張られて収束が遅くなるので注意・・・・。
中規模でCiscoロックインであればRPVST+(一部HPEのスイッチなどは互換性がある)。、Vlanの数が非常に多い、あるいは複数ベンダー機器が混在する場合はMSTで実装すると良いでしょう。
とはいえ、既存ネットワークの状態、運用者のスキルにもよるので、ヒアリングを欠かさないこと。
STPの構成ではどうしても1つ利用されない経路が存在します。これを利用するようにするにはPVSTやMSTでもある程度解決できますが、より実装が複雑になったり、思わぬ動作を引き起こす場合があります。
帯域の利用率が非常に高いネットワークでは後述のスタックなど、別な方法で冗長化構成を取るべきです。
スタック、バーチャルシャーシ(StackWise / VSS / IRF)など
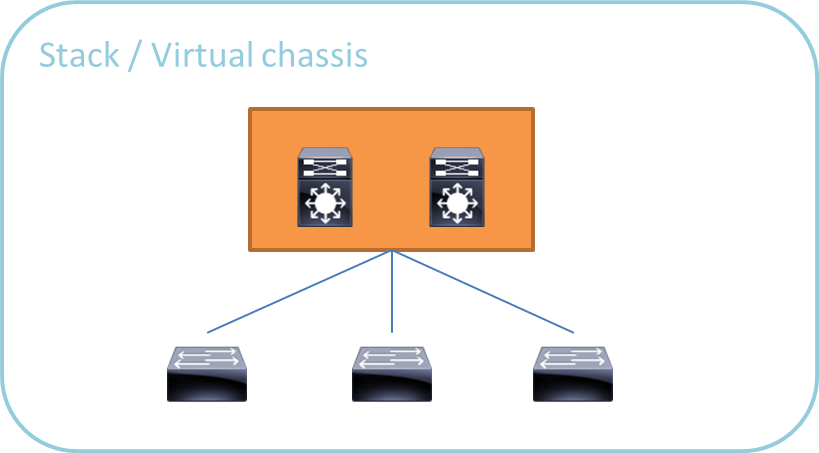
スタック、バーチャルシャーシは物理的に2台のスイッチを仮想的に1台として扱うことのできる技術です。
コンフィグの管理も1台分だけすればよく、設定管理などが簡素になります(機種によっては3台以上をまとめることも可能)。
また、未使用帯域が存在するなどのSTPの問題を解決する構成が可能となります。
スタックは通常BOX型のスイッチの、バーチャルシャーシはシャーシ型のスイッチでの呼び方となります。
最も有効な構成としてはLink Aggregationと組み合わせた構成があります。
下図の構成では、三角形のループ構造のように見えますが、実際は上図と同じ様にループフリー構成として運用が可能です。
MECとありますが、Multi Chassis Ether Channelの略です。

が、この技術も若干デメリットが有り、下記の制約があります。
- 同じファームウェアバージョンである必要がある
- フィーチャーセット(機能レベル)が同じ必要がある
- SDMテンプレートが同一である必要がある(Ciscoの場合)
上記制約のため、機器が対応していない場合は容易にOSのアップデートができない、メンテナンス時の通信の片寄時に通信断が発生する可能性があるなどの問題が発生する場合があります。
なお、スイッチ間をつなぐケーブルにはDAC(Direct Attach Cable)と言われるSFP+と光ケーブルがセットになったケーブルや、個別にSFP+と光ケーブルを購入してつなぐ、などのパターンがあります。購入し忘れに注意しましょう。
Ethernet Fabric
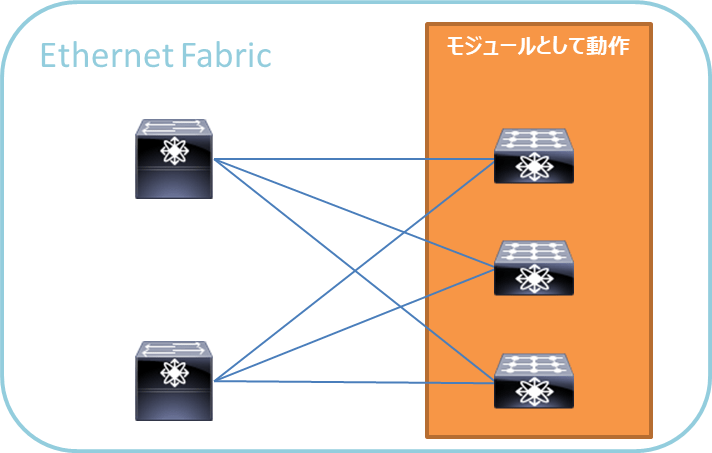
これまではツリー型構造を前提としたネットワーク構成での冗長化がベースでしたが、より大規模なデータセンターネットワークにおいてレイヤ2の概念を置き換える考え方が登場しました。
ツリー構造ではなくメッシュ構造に近く、非常に柔軟なネットワークを提供できます。
ベースとなっているのは以下の技術です。
- Trill(Transparent Interconnect of Lots of Links)
- SPB(Shortest Path Bridging)
ざっくりというと下記の特徴があります(ベンダーごとに細かい拡張があるのでそこは割愛)
- STPフリー:L2スイッチのような筐体はモジュールとして動作するため、仮想的に1つの筐体のポートとして扱える。
- コンフィグの一元化:スタック同様、中央集中的にコンフィグの管理が可能
機器が非常に高価なのと、高密度に集約されることでケーブル配線やラック配置の設計難度があがります。
レイヤ3(ネットワーク層)
VRRP / HSRP / GLBP
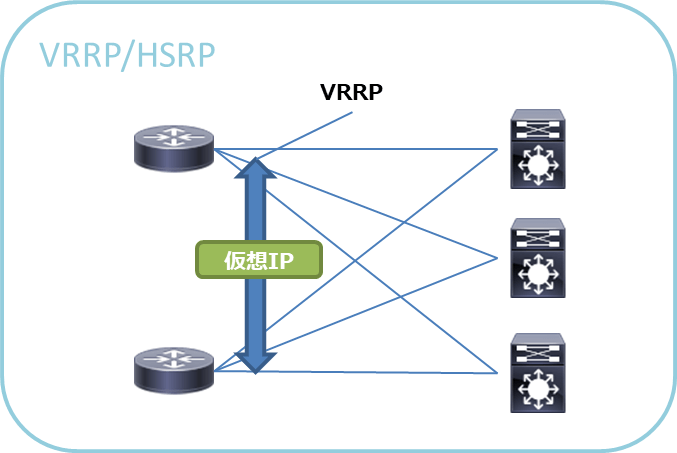
VRRP(Virtual Router Redundancy Protocol)とHSRP(Hot Standby Router Protocol)は基本的にActive/Standbyのゲートウェイ冗長化機能を提供する機能です(2台以上での冗長化も可能)
- HSRPはCisco独自機能で、VRRPは標準規格です。若干の仕様の違いはあれどすごく雑に言うと概ね同じ仕組みで動作します。
- VRRPではMulti-Group、HSRPではMultiple実装があり、グループごとに主系/副系を変えることで簡易的にActive/Activeな構成を取ることも可能です。
- GLBP( Gateway Load Balancing Protocol)は、またものすごくざっくりいうとゲートウェイに対応したMACアドレスをラウンドロビン方式で順番に返すことで標準でActive/Activeな構成を取る事ができるCisco独自機能です(変更可能)
基本的にはVRRPが後発でプロトコル実装的にIPパケットで動作するので、VRRPを使うことが多いです。
※HSRPはUDPで動作しますので、若干のオーバーヘッドを嫌いたくなります。
※GLBPは上述のEthernet FabricのCisco版で使うことがあるかも(使ったことはないですが・・・)
ECMP(Equal Cost Multi Path)
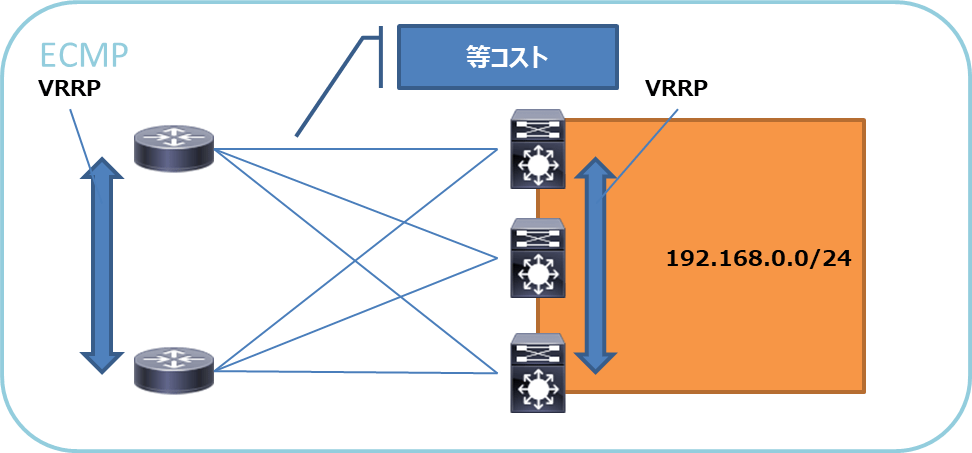
動的ルーティングプロトコルでは経路交換時に同じ宛先の経路が複数ある場合、最もコストが低い経路をルーティングテーブルに読み込みます。
このとき各経路のコストが等しい場合、複数の経路をルーティングテーブルに持ち、負荷分散することが可能です。これをEMCPと呼びます。
EMCPはそのバランシングにより下記の2つの実装があります。
Per packet ECMP
- パケットごとに経路を振り分けてくれる。
- 理想的にバランシングされる一方、リンクに求められる遅延差がシビアで、実は障害に弱い(影響を受けやすい)。
- TCPやUDPにおいてフラグメントされたパケットの処理やパフォーマンスに問題が出ることも。
Per flow ECMP
- フローごとに経路を振り分けてくれる(フローの定義はベンダーによって異なる)
- Per packet ECMPで起きる問題が発生しない。
- バランシングを完璧にこなすのは考慮事項が多く、非常に困難。
- 一般的にはこちらが採用されている。
よく利用されるルーティングプロトコルにはBGP、OSPFがあり、概ね以下の区分けです。
- OSPF(Open Shortest Path Fast):内部ネットワークでの経路交換に利用されるプロトコル。
- BGP(Border Gateway Protocol):外部ネットワークとの経路交換に利用されるプロトコル。最近内部ネットワークでもレイヤ2排除のために使われる。
レイヤ4(トランスポート層)/レイヤ7(アプリケーション層)
主にロードバランサ、ファイアウォール、セキュリティアプライアンス系がこの層に該当します。
図がシングル構成になっていますが、コレまで紹介した機能と心の目で冗長化してみてください。
ロードバランサ
ロードバランサ(LB)の構成は通信経路の途中に横付けするワンアーム構成(LANが1本だから)と経路に挟み込むツーアーム(インライン)構成があります。
大まかにワンアームとツーアームはどっち選べば!?という点については個人的にはワンアームが良いと考えています。
現状動作しているネットワークにLBを挟み込む場合でも物理構成に変更を与えることなく追加が可能な点と、経路上にLBが存在しないため、メンテナンスし易いことが挙げられます。
ワンアーム(One-arm)構成/SNAT/DSR構成
ワンアーム構成1つとっても(知ってる限りで)3つの構成を取ることができます。
1つ目はリアルサーバ、バーチャルサーバ、デフォルトGWを同一セグメントにする、あるいはリアルサーバのデフォルトGWをバーチャルサーバ(LB)のIPアドレスを指定する場合です。
すべての通信はわかりやすくLBを通過するため、セグメントに余裕があれば構成しやすいのがメリットかなと思います。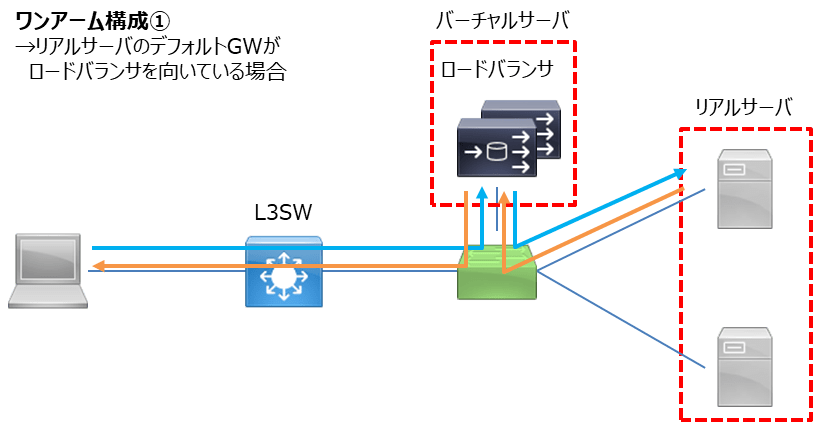
2つ目はSNAT構成です。例えばリアルサーバ群がVMなど横にスケールする構成で、もうIPの空きに余裕がない、とか、通信要件でリアルサーバのGWはL3SWでないとダメ。といった場合にはSNATという機能を使います。
行き帰りの通信経路が異なる場合、LBはセッションを確立できないため、NAT(Network Address Translation)機能を利用して、送信元IPをLBのIPに変換することで強制的にLBを通すということが可能です。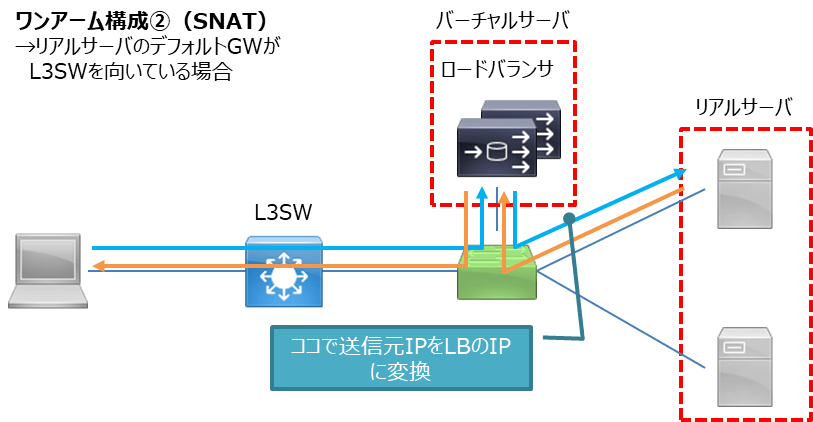
3つめはDSR(Direct Server Return)構成です。
DSRはその名の通り、ロードバランサに着信したクライアントからのパケットを帰りはLBを経由せずに直接クライアントに返す構成です。イマドキのLB構成においてDSRは敢えて選択する方式ではないという認識です。
ちなみにこの構成もL3DSRとL2DSRです。
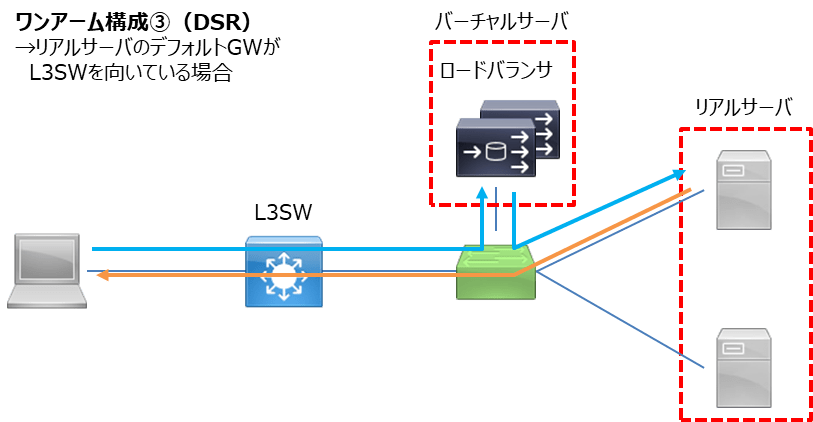
メリット
- LBでSNATなどの処理を行う必要がなくなるため、リソースに余裕ができる&スループットが向上する。
デメリット
- L4ロードバランサとしてしか利用できない(SSL終端とかは無理)
- みんな大好きARP/GARP(L2機能)を使うため、面倒を見るレイヤがちょっと広くなる(L2DSRの場合)
- 方式によるが、MTU(トンネル方式)やDSCP(DSCP方式)の値に制限がでる(L3DSRの場合)
そもそも最近の(大手だと)BIG-IPやA10のロードバランサは十分な処理速度があり、SSLもなんならLBのアクセラレータを通したほうがスループット向上に寄与したりするので、必要でなければDSR以外を選びたいところです。
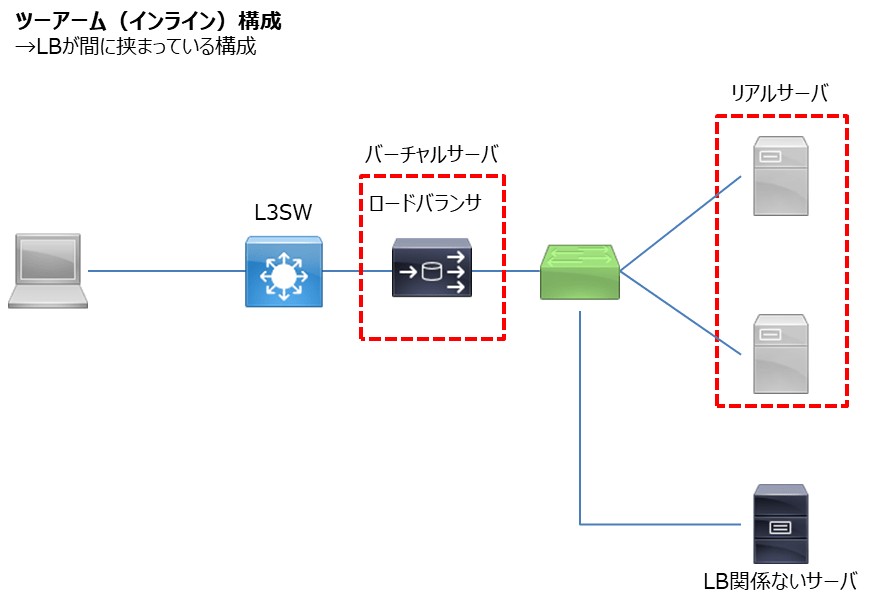
ツーアーム(Two-arm)構成
ツーアーム構成はその名の通り2本の腕で通信経路中に挟み込まれる構成です。
ネットワークエンジニアとサーバエンジニアが分かれているときなど、ネットワーク屋さんだけでLBを構成する場合はこちらの構成が単純で問題も少ないです。
こんな構成にするんじゃない、って話ですが、下図のような構成をとったときにLBに関係ないサーバもLBを通るという状況が発生しますので注意が必要なのと、帯域は十分に確保したほうが良いです。
だってL3SWに空きポートが無いんだもんとか、歴史的理由によりサーバは子のSW配下にしかつけちゃダメとかの背景でやむを得ずこんな構成になったり
セキュリティアプライアンス
ニッチ&ニッチですが、Fire eyeなどのセキュリティアプライアンスを導入する場合も構成方法が複数あります。
当然ですが、セキュリティアプライアンスはそれを通過するパケットを監視します。したがって、何らかの方法でパケットをセキュリティアプライアンスに入れてあげることが必要です。
スパン・タップ構成
ネットワーク機器にはSPAN(Switched Port Analyzer)という機能が存在する機種があります。
要は特定のポートを通過したパケットを別なポートにコピーする機能です。当然といえば当然ですが、SPANはCPUを使った処理になるので、ルータやスイッチの負荷が上がりがちです。
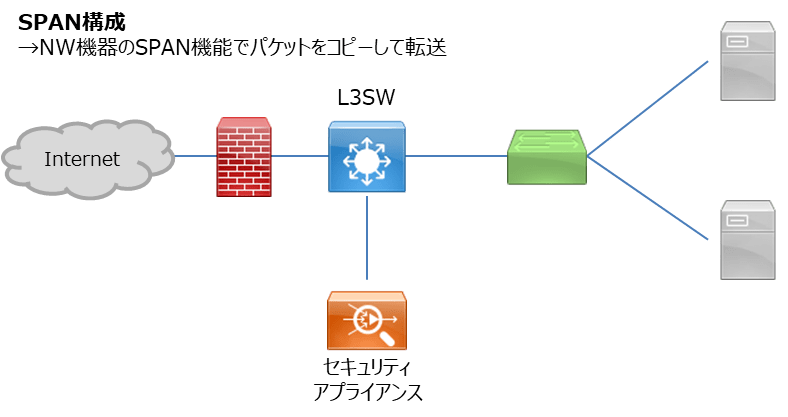
上記問題を解決するためにタップという機器もあります。通信経路に挟み込んで信号を分岐するための機器で、電源故障時も通信をバイパスすることで可用性を下げることなく(機種によります)導入することが可能です。高価ですが・・・。
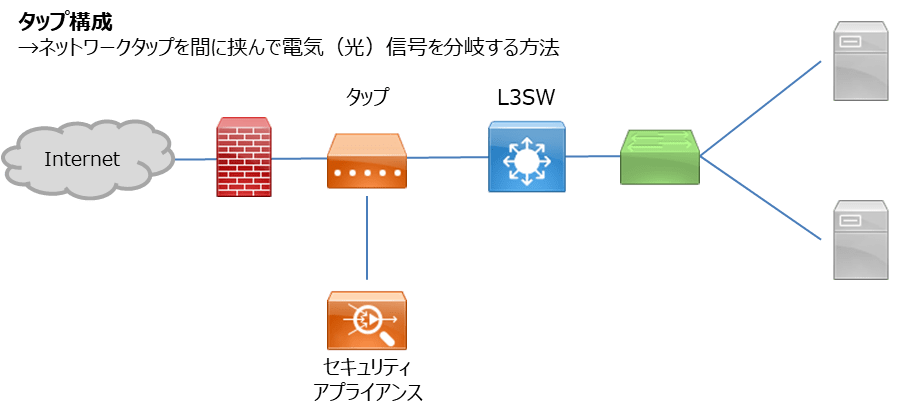
通信に影響をあたえることがないため、インライン構成よりこちらの構成がおすすめです。ネットワーク的には。
とはいえ、セキュリティアプライアンスの機能をフルに活用する場合にはインライン構成の方がベターだったりしますので、要件次第ですね。
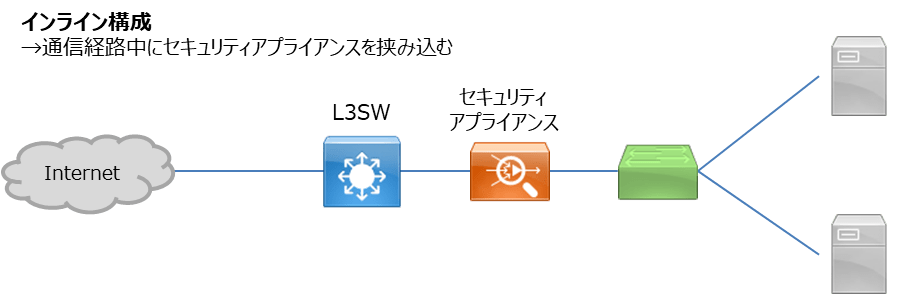
インライン構成
セキュリティアプライアンスに搭載されている冗長化(HA)機能を利用することが一般的です。
構成としてはLBと同じくとてもわかり易いですね。
ファイアウォール
前提としてステートフルフェイルオーバーに対応しているか否かを事前に確認しましょう。
だいたい対応しているとは思いますが、対応していない場合はVRRPでの冗長構成が一般的ですが、そもそもセッションなどのステート(状態)を引き継がないため、切り替わり時に通信断が発生するなど、辛い現実を突きつけられることも。。。
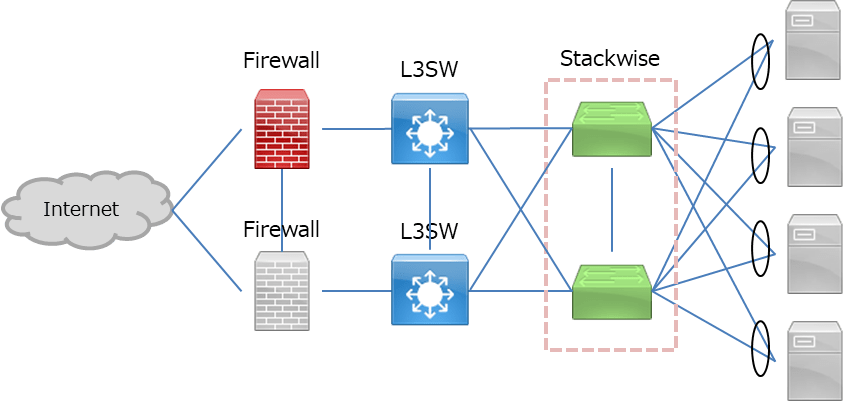
Active/Passive
この構成は単純で、よくある構成です。
ステートフルフェイルオーバーに対応したファイアウォールではスタンバイ機への同期は常に行われ、障害時の切り替わりに備えています。
OSのバージョンアップなどのメンテナンス行為もしやすく、通信路の帯域などが許す場合はこちらがおすすめです。
Active/Active
この構成では常に両方のファイアウォールでのトラフィック検査を行います。
ステートフルフェイルオーバーに対応したファイアウォールでは相互にセッションのやり取りを同期します。
機種によっては行き帰りのトラフィックが異なるファイアウォールを通る場合、破棄される可能性があります。十分に検証しましょう。
まとめ
まとめと言ってもとっちらかってしまうのですが、ココまで読まれたアナタは鋼のメンタルがあるのでぜひ一緒にインフラ屋さんをやりましょう。
動いて当たり前なネットワークインフラの背景にはネットワークエンジニアがアレコレ頭を捻ったネットワークトポロジが存在しています。
前述しましたとおり、クラウドサービスの台頭でなかなかガッツリ触ることのなくなってきたネットワークですが、ネットワーク技術がなくなることは今後もないでしょうし、オンプレのネットワークに触れるときがあればこんな記事があったな、と思いだしてもらえると幸いです。