はじめに
GCPをテーマにした連載企画を始めるということで、初回はStackdriver Loggingの活用方法をまとめます。1記事でまとめるには手が余るほど様々な機能があるため、初回はログの出力とビューア周りといったアプリケーション開発者視点での機能に絞って説明していきます。利用コードはGoで書かれていますが、汎用的な内容なので他の言語でもある程度通じる内容にしているつもりです。
連載企画は以下の10本をほぼ連日投稿する予定です。お楽しみに!
- Stackdriver Loggingへ良い感じのログ出力方法を考える(この記事です)
- Istio on GKEではじめるサービスメッシュ
- Goでサーバーレスな管理画面アプリを作る
- Cloud Life Sciencesを見てみた
- 【もう鍵なくさない】GCPのSecret ManagerとBerglasで幸せになる
- Forseti Config Validator
- s3→BigQuery
- Firewall Ruleのタグ命名規則について考えて
- 初めてのGCP 画像AI(VISION API)をさわってみた
- Cloud Deployment Manager
Stackdriver Loggingについて
Stackdriver Loggingは、GCPやAWS(!)からのログの収集、検索、分析、モニタリング、通知といった機能を持つGCPのマネージドサービスの1つです。ユーザからするとログの収集・蓄積し、それらを検索するためのログ基盤を自前で構築するのはかなり大変ですが、全てStackdriver Loggingサービス側が面倒見てくれるため、よりアプリケーションなど自分たちの関心事に集中できるようになります。
なお、2020/02/04時点ではログデータがプロジェクトごとに最初の50 GiBが無料で、 その後は$0.50/GiB の費用がかかります。
Stackdriver Loggingにログを流す方法
Stackdriver Loggingへ直接ログデータを流し込むには、Logging Client Librariesが存在します。こちらは内部的にStackdriver LoggingのWeb APIのエンドポイントをコールしてログデータを流し込んでくれます。
Logging Client Librariesを利用しなくても、CloudRunやFunction上にアプリケーションをデプロイし、それ上で標準出力/標準エラーでログを出せばStackdriver LoggingにGCPサービス側で連携できます。CloudRunは標準出力/標準エラーに加えて、 /var/log やsyslog(/dev/log) に出力しても連携されます 1。
また、Stackdriver Logging Agent というfluentdベースのツールを導入することで、ローカルファイル出力されたログも収集させることができます。
今回はアプリケーションからLogging Client Librariesを 利用しない ケースで調査しています。
ログレベルについて
ログレベル(Stackdriver Loggingのコンテキストではseverity)によって、ビューアで表示する見た目を変更できます。
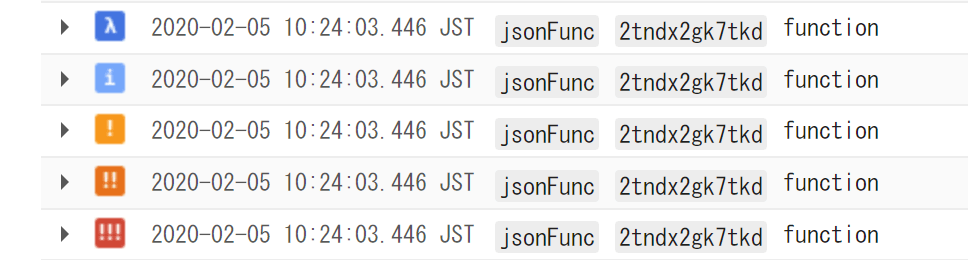
上から、DEBUG、INFO、WARN、ERROR、CRITICALです。Stackdriverは各種検索Filterも充実していますが、ログ量が増えるとちょっとしたことで見落としが発生しうるので、障害時の運用フローを整備する前にSeverityは正しく設定したほうが良いでしょう。
severity設定方法は、標準SDKを利用する以外だと、ログ出力レイアウトをJSONにすることが必要になります。
GoでJSON形式でログ出力と聞くと、最近では “rs/zerolog” か “uber-go/zap” がオススメですが、今回はわかりやすさ優先で心をこめてjson.Marshalする方式で説明を進めます。
JSONのログレベル項目は severity という名称です。
// Cloud FunctionのEndpoint関数 |
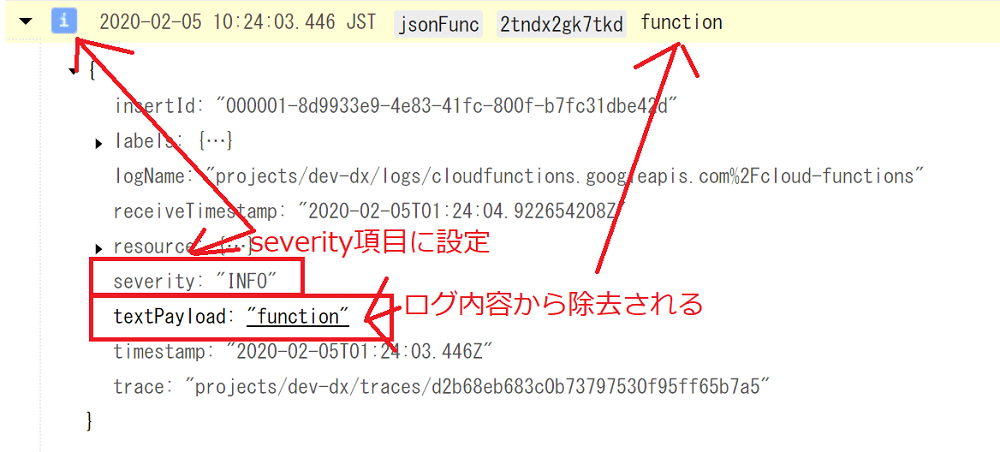
このCloudFunctionをデプロイし、テスト実行などから実行するとログ出力をお手軽に確かめることができます。
そうすると、ビューアの textPayload から severity の項目が除去され、上位のフィールドにセットされていることがわかると思います。
ちなみに、利用できる Severityのレベルは以下の種類です。
| ENUM | Level |
|---|---|
| DEFAULT | (0) The log entry has no assigned severity level. |
| DEBUG | (100) Debug or trace information. |
| INFO | (200) Routine information, such as ongoing status or performance. |
| NOTICE | (300) Normal but significant events, such as start up, shut down, or a configuration change. |
| WARNING | (400) Warning events might cause problems. |
| ERROR | (500) Error events are likely to cause problems. |
| CRITICAL | (600) Critical events cause more severe problems or outages. |
| ALERT | (700) A person must take an action immediately. |
| EMERGENCY | (800) One or more systems are unusable. |
どのレベルをどのような場合に出力するかはチームごとにコンセンサスを取ったほうが良いでしょう。
わたしたちは、だいたいDEBUG, INFO, WARNING, ERRORの4種類をアプリケーションコードで利用することが多いです。
開発環境ではDEBUG、プロダクション以上ではINFOレベルでログ出力させ、ERROR以上でSlackやメールに通知するようにしています。
うまく行かないケース
ログ出力内容をJSONではななくただのテキスト形式、例えば fmt.Println("[INFO] call any method") にしてもStackdriverはseverityを認識してくれません。
func StartFunc(w http.ResponseWriter, r *http.Request) { |
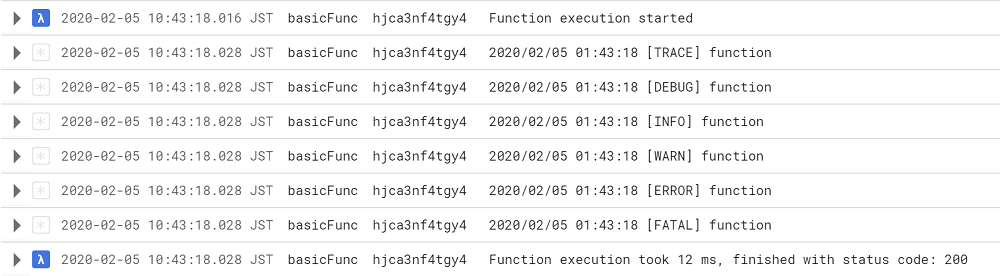
上記のキャプチャ画像を見るとseverity は空っぽなので、見た目も特に色が付いていません。
ログエントリをドリルダウンして、severity のレベルを確認しても空っぽです。
また、標準エラー出力にログを書き込むと、severityが変わってくると期待しましたが、こちらも変化なしです。
func StartFunc(w http.ResponseWriter, r *http.Request) { |

こういったログ出力ポリシーになっている場合は、文字列ではERRORというラベルが見えますが、ビューア上は何も変化しないため見落としに注意ください。
ログ取得時間について
ログレベルの severity 同様に time というJSONフィールドを設定すると、ログ上のタイムスタンプを上書きできます。指定しない場合はおそらく現在時刻が設定されます。
時刻フォーマットはprotobufでいうTimestamp で、RFC 3339に則れば良いとのことです。
func StartFunc(w http.ResponseWriter, r *http.Request) { |
このようにすると、先程の severityと同様に、textPayloaのJSONからtimeフィールドが消え、上位のtimestampが書き換えられます。
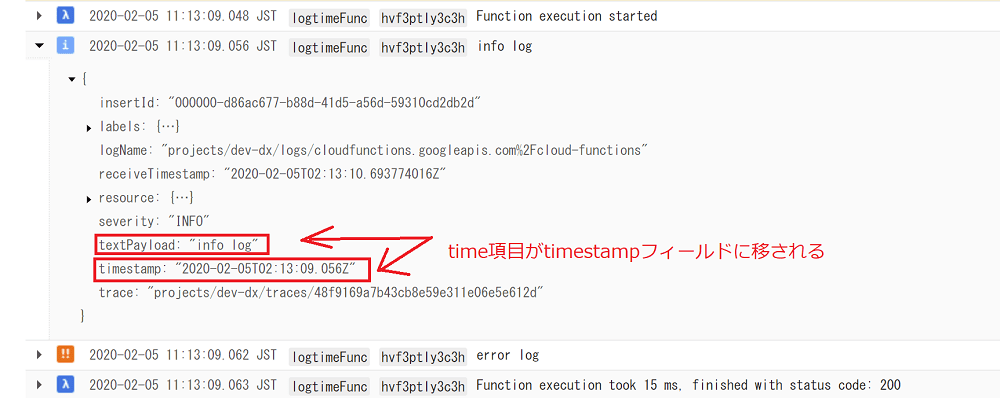
timeフィールドは任意項目ですが、ローカル実行での確認時にも便利なため特に理由がなければ付けたほうが良いと思います。
Stackdriver Traceとは

Stackdriver Traceはアプリケーションからレイテンシ データを収集して Google Cloud Platform Console に表示する、分散トレースシステムです。
https://cloud.google.com/trace/
分散トレースって何? という方はこちら↓の記事を参考ください。
https://future-architect.github.io/articles/20190604/
分散トレースの機能の1つには、下図のようなウォーターフォールチャートを出すことができます。これを利用して、アプリケーションのボトルネック調査などに活かすことできます。

Stackdriver TraceとStackdriver Loggingの連携
連携の前準備として、アプリケーションのロールに Cloud Trace エージェント のロールが必須になります。
コードはまず、OpenCensus経由でStackdriver Traceに連携します。
trace.ApplyConfig(trace.Config{DefaultSampler: trace.AlwaysSample()}) はテスト用に毎回トレースを行うような指定です。通常は毎回実施するとコストが高いため、動作確認時以外は設定しないほうが良いと思います。
var client *http.Client |
Cloud Functionの途中でHTTPリクエストを発行するものとして、http.Clientも同時に生成しています。
続いてCloud Functionのメイン処理です。trace.StartSpan(r.Context(), "root function") でSpanという、計測の単位を作成できます。処理の途中でinit で生成した http.Client を利用すると、OpenCensusライブラリ側がHTTP Request/Responseをキャプチャして、 Stackdriver Trace側に送信してくれます。
func StartFunc(w http.ResponseWriter, r *http.Request) { |
Stackdriver Trace側のログのリンクを見ると、Stackdriver Loggingでログを確認できます。
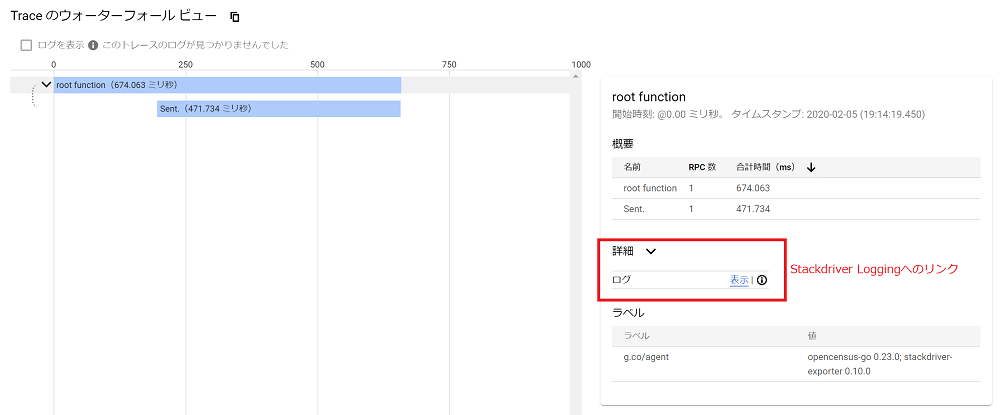
リンクをクリックすると、Stackdriver Logging側の該当するログに遷移できます。

今回のサンプルコードには記載していないですが、ログ側に検索条件や処理件数を出力しておくと、その処理時間が妥当なのか、想定外なのか判断ができるため、性能調査などを行う場合には非常に有用だと思います。
GCP以外でアプリケーションを動かす場合
GCP以外のリソース上でアプリケーションを動かす場合は、trace と、spanId のフィールドを利用するとStackdriver TraceとLoggingを紐付けることができるようです。その場合はログ出力部分を以下のように書き換えれば良いと思います。 こちらはまだ未検証なので参考程度にお願いします。
https://cloud.google.com/logging/docs/reference/v2/rest/v2/LogEntry
func FmtJSON(logLevel, message string, span *trace.Span) string { |
その他
Stackdriverの LogEntry のドキュメントを読むと、他にも labels や traceSampled などのオプションが存在します。 traceSampled はデフォルト false ですが、 trueにするとサンプリングされて Stackdriver Trace側に連携されるようです。このあたりの使い分けは別途調査したいと思います。
まとめ
- Stackdriver Loggingで視認性を上げるためには、JSON形式でログを出力しseverityを設定する
- time項目も設定しておくと良い
- Stackdriver Traceを設定するとパフォーマンス可視化とログが紐づくと捗るのでオススメ
話しが少しそれますが、一度Stackdriver Traceでビジュアライズを始めるとのウォーターフォールビューの見た目にこだわりたくなります。これらをうまく出すコツについてはまた別途ブログ化したいと思います。
- 1.CloudRunのその仕様はドキュメント読むまで気が付かなかったです。https://cloud.google.com/run/docs/logging ↩