はじめに
AWS StepFunctionsとLambdaを活用してバッチ処理を行う記事です。サーバレス連載企画の6回目です。
2020年はServerlessアーキテクチャが当たり前のように採用される時代になってきていると実感します。フロントエンドからアクセスされるBackendのAPIはAWS環境だと、AppsyncやAPI Gateway+Lambaの利用、IoTなどイベントドリブンなメッセージに対してはAWS IoT、その後続はKinesisを使い、さらにその後続でLambdaやKinesis AnalyticsでETL処理を行い、データストアとしてDynamoDBやS3に格納するといった一連の流れ全てフルマネージドなサービスに寄せて構築することも当たり前ですし、そういった事例も珍しく無くなってきました。
サーバレスのバッチ処理
そんな中で、バッチ処理(定時起動やユーザの非同期イベントで処理を行うジョブ)に関してはLambdaではなくECSなどを採用することが多いと思います。理由としてはやはり LambdaのTimeout時間が最大で15分 1 であるためです。また、ECSも非同期タスク起動ではなく常駐にしてHTTPリクエストなどでイベントを待ち受けるタイプに関しては、ALBであれば4000秒(約66分) 1なため、1h超えの処理時間になりうる機能は採用できないでしょう。ALBではなくNLBを採用するとこの制約からは逃げられるので、SecurityGroupなどの考えがややALBと異なりますがこちらを採用するチームもいらっしゃると思います。もしくは次の ecs-run-task で非同期にECSコンテナを呼び出している、という方式をとることも多いのでは無いでしょうか? 定期実行であれば、ECS Scheduled Tasksを利用することもできるので便利ですよね。
ECS Run Taskについて
ecs-run-taskで非同期(または定期的)にECSを呼び出す方法を取るメリットは多く、、
- Timeoutなどの各種制約を無視して実行できる
- 実質main関数を実装すれば良いので開発時にコンテナを意識することは少ない意味で難易度は高くない
- log出力も自由自在(直接ElasticSearchにログを投げつけることなど何でもできる)
- Fargateを用いるとサーバインフラを意識しないで済むため、実質Serverlessとして運用できそう
…と言ったことがあります。とは言えいくつかトレードオフもあります。思いつく限りだと…
- ECSタスクの終了を 待ち受けて 次処理を行うといったことがやりにくい
- 起動したECSタスクが終了したということを、通常はPolling的に監視する必要がある
- もしくは、ECSコンテナアプリの終了時に、SQSなどに実行終了したことを通知する必要がある
- 起動したECSタスクが終了したということを、通常はPolling的に監視する必要がある
- コンテナサイズに依存して起動時間のオーバーヘッドがある
- ECS TaskDefinitionの管理が大変
などがあると思います。kayac/ecspresso のようなECSデプロイツールや、ECS以外のサービスを採用しても学習コスト・インフラ保守コストはどうしてもかかるのでやや無理やり上げた感がありますがご容赦ください。
個人的にはジュニアなエンジニアがチームに多いのと、AWSに慣れていない新規参画者が多いという、「他アプリがLambdaで完結している場合に、ECSという別のアプリランタイムを入れたくない」 という技術スタックをなるべく増やしたくないという思いがあり、できる限りアプリ開発はLambdaでやりたいと思ってます(Dockerfileもなるべく書かせなく無ければ、 ECRやECSなどインフラ管理対象も増やしたくないし、CI/CDのバリエーションも下げて楽したいというのがあります)
Lambdaでバッチ処理をガンバル
起動時間の制約があるもののLambdaでバッチ処理をガンバル前提で進めます。
アプローチとしては色々あると思いますが、よく思いつくのは次の2つの手法です。
- Lambdaの実行時間をアプリ上で計測し、シンデレラタイムが近づきそうであれば自分で処理を中断、オフセットを引数にSQSに投げるか、非同期で次のLambdaをInvokeして処理を継続する(下図のLambda延命イメージ)
- 入力データを一定の大きさでパーティション化して、1と同じくSQSやLambdaをInvokeして後続の複数のLambdaで処理を行う(下図のLambda入力パーティションイメージ)
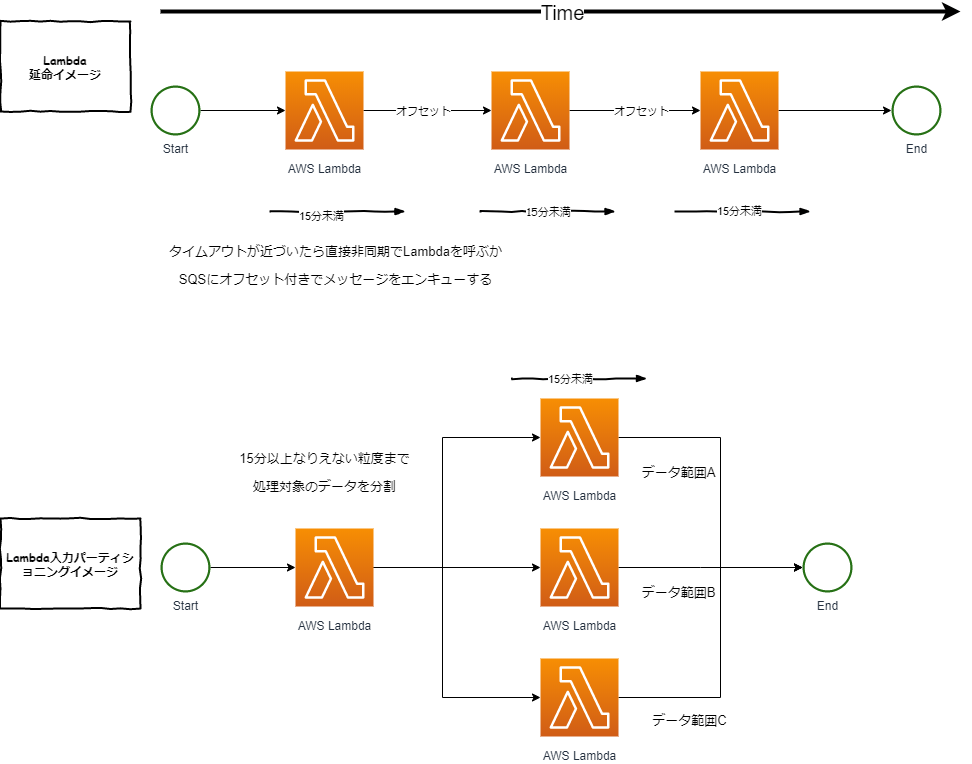
入力データを上手く分割実行できないものに関しては1でシーケンシャルに行う必要がありますが、そうでない場合は2のアプローチのほうが、後々並列実行したい場合にも転用できるので便利だと思いますので、2の方針で進めます。
コードについて
次からGoのコードをまじえながら進めていきます。記載するサンプルコードはimport文などを省略しています。全文は以下のリポジトリを参照ください。
https://github.com/laqiiz/servlerless-batch-example
入力がDynmaoDBの場合
DynamoDBはKVSという印象が強いですが、非常に多くの機能を持っています。いわゆるPK(HashKeyかHashKey+SortKey)を指定せずにレコードを取得する方法には、次の1,2がありますがバッチ用途だとおそらく1を利用することが多いと思います。ちなみに、2はGSIに対しても実施できます。
- Scan: HashKeyを指定せずフルスキャンする
- Query: HashKeyを指定してSortKeyに対して条件で絞る
1のフルスキャンですがアプリケーション側でPartitionKeyのようなものを持たせること無く、DynamoDBの機能として下図のように 並列スキャンが可能です。
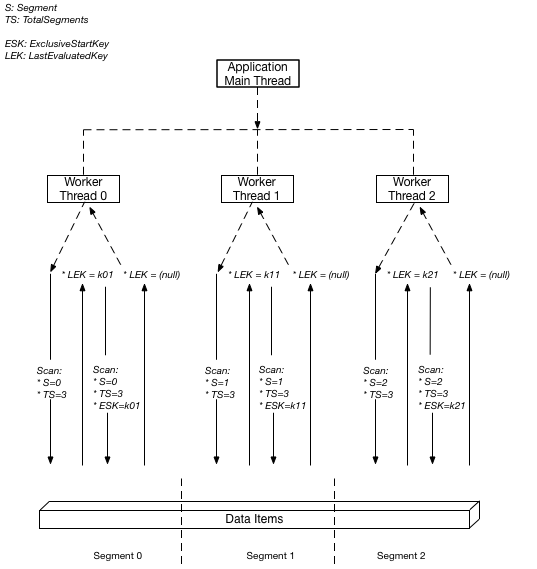
AWSのドキュメントから引っ張って来ましたが、 TotalSegments と Segment をリクエストに指定することで、DynamoDB側がデータを論理的にTotalSegmentsの数に分割してくれます。アプリケーション側では以下のように指定するだけでOKです。
例としてTotalSegments、Segmentを指定した場合のDynamoDB ScanのGo実装の例です。TotalSegmentsを4にする場合は、total=4にし、segに0,1,2,3指定した実行すれば排他的にデータを取得できます。何かしらのPartitionKeyとSortKeyを設定してGSIで上手くデータを分割すると言った考慮なしに利用できるため非常に便利だと思います。
アクセス方法を書いていきます。最初にDynamoDBを初期化しておきます。必要に応じて各種Config設定を行います。
var db = dynamodb.New(session.Must(session.NewSession(aws.NewConfig().WithRegion("ap-northeast-1")))) |
先ほど初期化したdbに対してデータ操作を行います。TotalSegments, Segment の指定が分割のキーとなります。
func ScanSegment(ctx context.Context, total, seg int64, startKey map[string]*dynamodb.AttributeValue) ([]Resp, map[string]*dynamodb.AttributeValue, error) { |
この ScanSegment 関数を呼び出すと、指定されたSegment番号のレコードのみ読み取る事ができます。呼び出し方は後述します。次のページングの考えと合わせて考慮する必要があります。
DynamoDBをバッチ処理で扱うときの注意
いくつか補足して、DynamoDBで大きなデータサイズのデータを扱う場合の注意を記載します。
ページングについて
DynamoDBの1度のScanでの最大サイズは1MBという制約があります。それ以上のデータを読み取りる場合は、 ExclusiveStartKeyで指定しているような ページング を行う必要があります。上記の実装であれば ExclusiveStartKey がそれにあたります。
ScanSegment の呼び出し側の実装例も記載しておきます。
func ScanWithLogic(ctx context.Context, total, seg int64) error { |
Scanの結果をページングを駆使しつつ最後まで読み取る場合は、 Scan結果の LastEvaluatedKey が存在しなくなるまで繰り返して呼び出すことになります。上記で segments=0 のデータをすべて読み取る事ができました。
単一プロセスでの分散実行
もし、ローカルで分散実行したい場合はGoであれば errgroupを用いると便利です。注意としてどれか1つのgoroutineが失敗した場合でも、それだけやり直すのではなく全てやり直すことになるので、アプリケーションを冪等に作って置く必要があります。
func main() { |
出力先をDynamoDBにする場合のスロットリング対策
今回、出力先についてはテーマではないですが、DynamoDBに対して行う場合はクセがあるため追記しておきます。
大量データをDynamoDBに書き込む場合は、BatchWriteItemを利用することが多いでしょう。このときDynamoDBのAPI制限 として、以下の25件の制約があります。
単一の BatchWriteItem オペレーションは、最大 25 の PutItem または DeleteItem リクエストを含むことができます。書き込むすべての項目の合計サイズは 16 MB を超えることはできません。
こちらは超過した場合には全件登録に失敗し、errorが返ってくるのでまだ良心的な制約です。
しかし、BatchWriteItemの仕様としてバッチの 部分的な書き込み成功 が発生することがありえます。テーブル名の指定など基本的なところが失敗していれば、全件失敗になるのですが、書き込みスループット超過エラーであれば UnprocessedItems としてレスポンスに含まれ、そのItemは書き込み失敗になります。最初はmjkと思い、いまでもmjkって思ってます。
そのため、下記の実装例のように、実行結果から UnprocessedItems を取り出し未処理の件数が0になるまで繰り返してBatchWrite要求を行う必要があります。
func BatchPut(ctx context.Context, puts []Output) error { |
ちょっと大変ですが、上記によってバッチ未処理の取りこぼし無くDynamoDBにデータを登録できます。逆にUnprocessedItemsを考慮せずに実行した場合、 err が発生せず正常終了するけどデータが実は未登録だった、ということがありえるのでご注意ください。
入力がS3の場合
前提としてS3に巨大な1ファイルに対して何かしらの検証やETLなどの処理を行うこととします。もし複数ファイルであればAWS Athenaのパーティション機能を用いた方が効率的だと思います。Athenaの場合はクエリ結果が非同期で取得することになるので内部で結果をポーリングするなど少し作り込みが必要だと思いますので、その点の考慮はご注意ください。
さて、S3の1ファイルを扱う場合で行単位でパーティショニングして読み取る方法は(調査した限りは)存在しません。入力がCSVやJSON Lineの前提だと S3 Select が利用できるので、こちらで対応します。
S3 SelectはS3の単一オブジェクトに対してのみ利用可能。SQLのテーブル名は s3object 固定になります。何かしらの数値項目に対して、 SELECT * FROM s3object WHERE (item_no % 4) = 0 とすれば対象のデータセットのみを扱えます。
CSVの入力に対しては、S3 Selectはデフォルト文字列で型判定するようなので、数値項目が存在する場合はSQL上でCASTが必要なので注意です。AWS Developer Blog - Introducing support for Amazon S3 Select in the AWS SDK for Goでは io.Pipe + csv.NewReader を使っている実装例が紹介されていますが、今回は折角なのでJSON Outputを使って実装してみます。
以下のようにS3 Select部分にSQLを記載します。
resp, err := svc.SelectObjectContent(&s3.SelectObjectContentInput{ |
上記を実行すると、resp.EventStream から実行結果を取得できるので、次のように処理します。
OutputSerialization で JSON を指定すると JSON配列ではなく、JSON Linesでデータが取得できるため、1行ずつ読み込みJSONをデコードします。
for event := range resp.EventStream.Events() { |
これにより、S3 Selectレベルで分割されたレコードに対して何かしらの処理を行うことができます。今回はJSON Outputを用いましたが、入力がCSVの場合はCSVそのままで処理したほうが性能は良いかもしれません。
S3 Selectを使う上での注意
バッチ処理に限らずですが、2020/04月時点ではAthenaのようにS3 Selectは外部スキーマを参照できないようなので、Structへのマッピングで数値項目が来た場合は、SQL側でCASTするのが手間でした。真面目にプロダクションで運用することを考えると、AWS Athenaを利用するほうが Schema on READ になるもの型の恩恵を受けられ良いかもしれません。
Step Functions
AWS Step Functions はAWS の複数のサービスに対してワークフローを組むことができるサービスです。ワークフローはステートマシンとして表現することでLambdaの実行管理を任せることができます。
ワークフローをJSONベースの構造化言語であるAmazon States Languageで記載するという点がツラミとして挙げられることが大きもしますが、定義したワークフローは即座にプレビューで可視化されますしそれをSVGなどでExportもできるので、JSON力を鍛えながら開発できます。
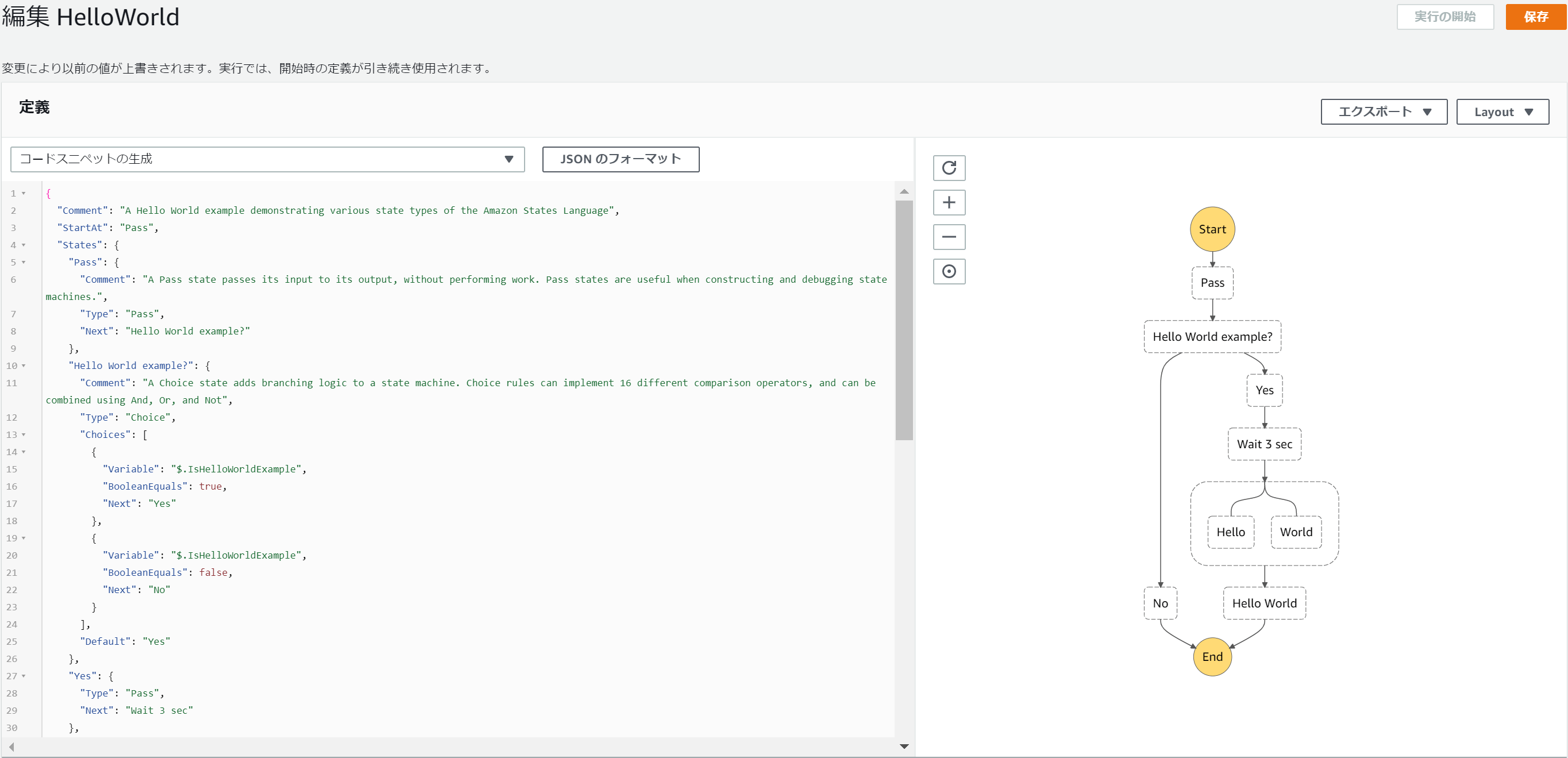
※HelloWorldのStep Functionsの開発イメージ
Step Functions × Lambda
Lambdaの実行時間制約をStep Functionsで突破しようという試みです。実際には以下のようなイメージです。前提として、処理件数が事前にある程度分かっている場合においては、単純にN個にタスクを分割してStep FunctionsからLambdaを呼び出せば良いです。この分散したLambdaそれぞれでDynamoDBのあるSegmentだけを担当させるイメージです。
DynamoDBやLambdaの場合はスケールアウトさせやすいサービスのため、固定であればParallelステートを利用して並列実行できます。
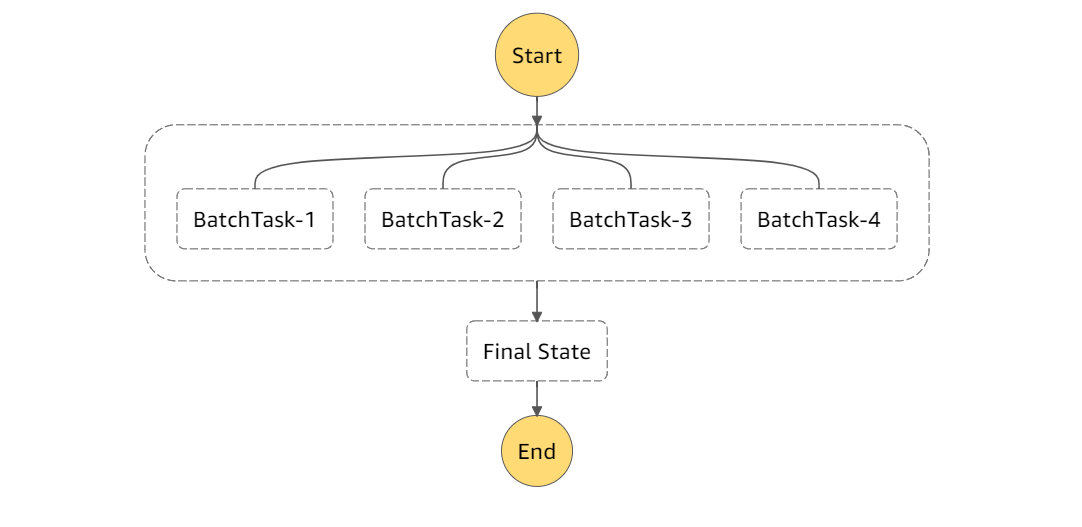
ただ、Parallelステートだと分散するタスク自体をJSONで定義する必要があり、同時実行数を増やすたびにStepFunctionsの定義を更新する必要があり手間です。次の動的並列の機能を今回は利用したいと思います。
動的並列する場合
Step Functionsは Amazon Web Services ブログ - 新機能 – Step Functions が動的並列処理をサポート で紹介されているMap 状態を用い、ワークフローでスキャッターギャザーメッセージングパターン(分散して集約するようなパターン)を行うことができます。
今回はこちらを採用して、最初にScatterLambdaというタスクで、分散情報を動的に生成し、TaskLambdaでDynamoDBをScanし、最後にGatherLambdaで実行件数をカウントするというフローを組むことにします(下図)。
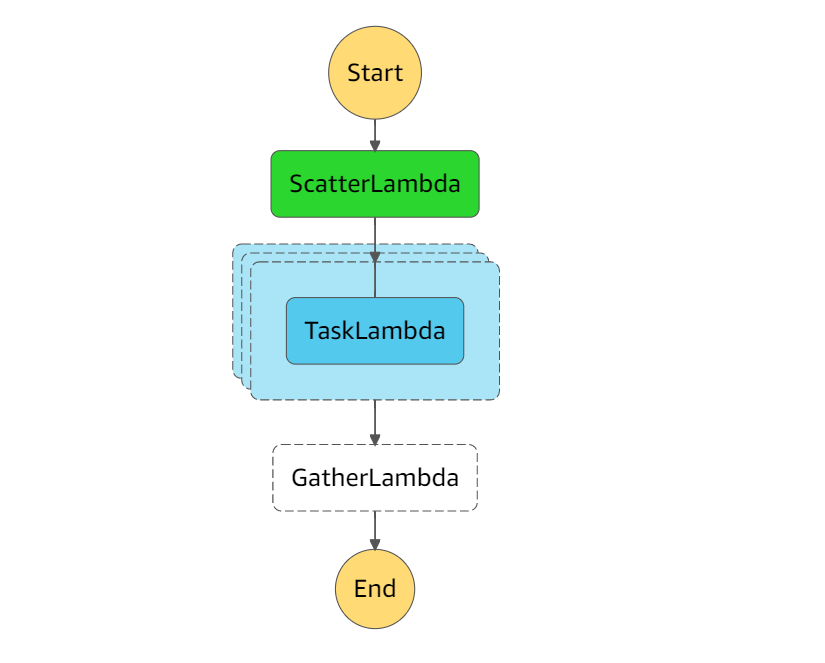
※水色のオブジェクトが重なっているところが並列実行されるタスクです。この各LambdaでDynamoDBのあるSegment数だけ担当させるイメージです。
Lambdaの In/Out 設計
3つのLambdaを利用しますが、概念的にそれぞれの入力・出力を示します。

実装について
上図のような状態遷移図は、下記のJSONで表現できます。ProcessAllSegments の Type: Mapと Iterator の部分がミソで、これによって動的に tasklambda 並列実行できます。
{ |
Scatter, Task, GatherのLambdaはそれぞれ以下のような概要です。
Scatter部分
Scatterは入り口のLambdaで、InEvent を引数に持ちます。並列数を受け取ることができこれに応じたTask定義を作成して、後続の TaskLambda に渡します。
type InEvent struct { |
出力のイメージは、例えば4並列であれば次のようなJSON配列になるイメージです。
{ |
このJSON配列 task_definitions の1要素ずつ後続のLambdaに渡します。
TaskLambad
TaskLambdaは実際にDynamoDBにアクセスして、バッチ処理を行うメイン処理です。今回はただScanして件数を計算するだけですが実際は、外部のAPIサーバに問い合わエンリッチしたり、集約して計算したり、他のデータストアに書き込むなどを行います。引数である InEvent が示す通り、ScattterのLambdaで生成されたDynamoDBのSegument情報を受け取り利用します。
type InEvent struct { |
1つ1つのLambdaの出力は以下のようなシンプルなものです。
{"count": 6293} |
並列実行された全てLambdaが終わると、最後にGatherのLambdaが起動します。
GatherLambda
最後に集約するLambdaです。TaskLambdaではScanした件数を出力しているので、それを集約して総件数を計算だけすることにします。 引数の InEventが配列になっているのは、今回Iterationで並列実行されたため複数のOutputがあるためです。
import ( |
今回はGatherのLambdaで終了なのですが、何かしら戻り値を定義しておくとStepFunctionsのコンソール画面から実行結果を確認できるので便利です。もし、集約処理が不要な場合はこのLambdaをなくしてそのままEndしてしまうのも手だと思います。その場合はScatter&Gatherというよりは、Fan-Outパターンと言うようです。
Deploy
それぞれ、それぞれのLambdaをデプロイして、StepFunctionsのJSONのARN部分を書き換えると実行可能です。ただし、TaskLambdaだけはDynamoDBにアクセスするためIAM RoleにDynamoDBのScan権限を付与してください。いくつかのコマンドは https://github.com/laqiiz/servlerless-batch-example にも記載しているので参考ください。
性能検証
作成したStepFunctionsがどれくらい処理性能がスケールするか検証しました。分散数を1, 2, 4, 8, 16 で計測しています。
テストデータ
- 件数:約10万件
- 1ドキュメントあたりのフィールド数:15項目
- 1ドキュメントあたりのデータ量:JSON表現で300[KB]弱
実行結果
処理時間と[ms]と分散数1との比率を表にしました。大体10万件のDynamoDBをScanするのに1並列だと30秒程度かかります。DynamoDBをScanするだけの処理では完全にリニアにスケールするというわけではないですが、本来はこの読み取ったレコードに対して、なにかしらの追加処理を行う時間が加算されるはずなのでほとんどのユースケースでは問題ないと思います。
| 分散数 | 処理時間[ms] | 分散数1との比率[%] |
|---|---|---|
| 1 | 31077 | 100 |
| 2 | 15414 | 49.6 |
| 4 | 9035 | 29.1 |
| 8 | 5047 | 16.2 |
| 16 | 3402 | 10.9 |
ちなみに、16並列では各実行数が6203~6577の間でScanできていたのでかなり件数は平準化できていました。
まとめ
長いエントリーを最後まで読んでいただきありがとうございます。
- ServerlessのBatchといえばFargateがメジャーだと思うが、Lambdaも工夫次第で十分戦える
- DynamoDBの並列Scanが便利で、10万件Scanが1並列で30秒ほどが目安
- S3が入力だとしてもS3 Selectで入力を分割する設計で対応できる
- StepFunctionsの動的並列実行を利用することでLambdaの実行時間制約に引っかからないように、事前で入力を分割しそれぞれのLambdaに渡す仕組みが作れる
サーバレス連載の6本目でした。次は加部さんのAWSサービストリガによるLambda起動です。
- 1.2020/04/26時点の話です。将来的に伸びる可能性が高いとは思っています。 ↩