はじめに
GlyphFeeds連載企画第2弾の記事となります。
はじめまして、TIG中神です。
メディア向けCMSクラウドサービス(以下、GlyphFeedsサービス)のインフラを設計・構築を行いました。メディアならではの特性や構成における重要なポイントについていくつかご紹介します。
メディアCMSの特性
メディアCMSサービスに求められる非機能要件の中で、特に重要なものとしては以下の3点があげられます。これらの要件はクラウドとの親和性が高いことからGlyphFeedsサービスではクラウドベースのサービスとして設計・構築を行っています。
- (1)高速なコンテンツ検索ができること
- (2)24時間365日稼働し、不慮のサービス停止によるダウンタイムを極力短くすること
- (3)処理量のスパイクに対応できて、かつ柔軟にスケール出来ること
(1)高速なコンテンツ検索
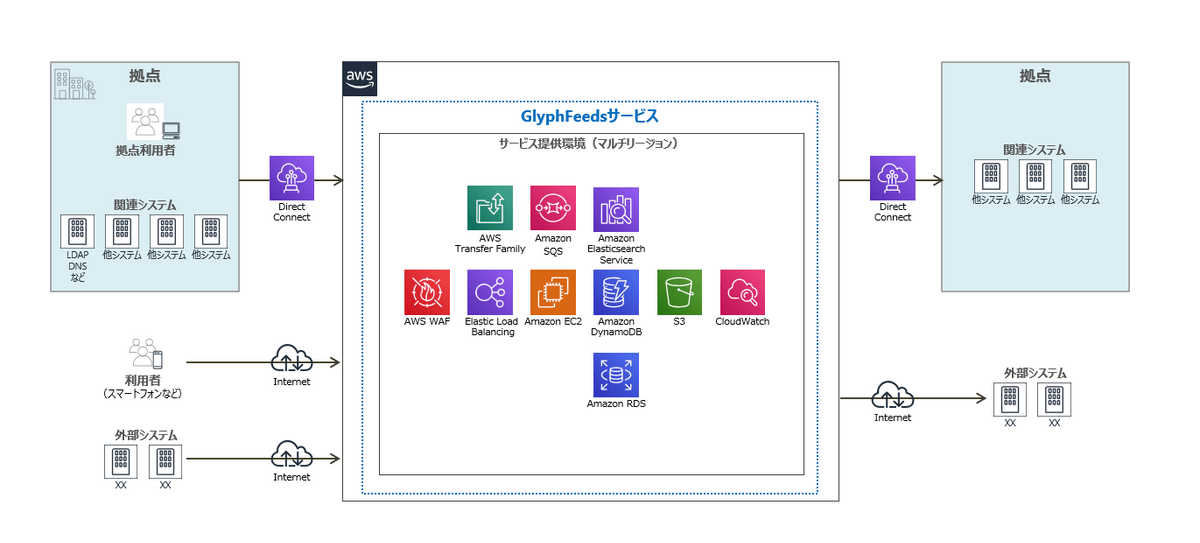
GlyphFeedsサービスの全体像としてはこのようなになっていて、大きく下記のサービス群で構成しています。
- 画面を提供するサービス
- APIを提供するサービス
- 非同期処理を行うサービス
- コンテンツの加工を行うサービス
- コンテンツデータの蓄積、検索、ステータスの更新を行うサービス
このうちコンテンツの高速検索においては上記の1、2、3、5のサービス群で実現しています。
これらのサービスを、EC2、ELB、Elasticsearch、DynamoDBといったマネージドサービスをベースに、なるべくディスクアクセスが入らないように設計・構築しています。
性能を引き出すために複数のレイヤーでチューニングを行っていますが、最後の最後までチューニングに苦労したコンピューティングの部分について記載します。
なぜコンテナ(ECS)ではなく仮想サーバー(EC2)を採用したか?
コンピューティングの部分は、当初コンテナ利用を検討していましたが、導入前の性能テストにて、コンテナよりも仮想サーバーの方がインスンスの性能を使い切れるという結果となり、最終的には仮想サーバーを採用しました。
以下に検証の概要を記載します。
どのような場合もこの結果になるわけではなく、構成や処理特性・ワークロードにより結果は異なってくると思います。
■検証時の構成
EC2(Gatling) => ALB => コンピューティング(1) => NLB => コンピューティング(2) => Elasticsearch or DynamoDB
- Gatlingを動かすサーバーがボトルネックにならないように無理のないインスタンスタイプを選択して、念のためGatlingのOS Tuningも行っておきます。
- コンピューティング(1)(2)は下記の構成を基準にをベースに「インスタンス数の変更、インスタンスタイプの変更、CPUユニット、メモリの割り当ての変更、JVMヒープ値の変更、コンピューティング(1)のみEC2構成またはその逆のパターンなど」を様々な組み合わせとなるように変動していいきます。
コンピューティング(1)の構成
| 構成 | インスタンスタイプ | 数量 | OS | 稼働アプリケーション |
|---|---|---|---|---|
| ECSの場合 | m4.large(2vCPU 8GiB) | 2 | ECS-optimized AMI(Linux) | Spring Bootコンテナ ・FROM amazonlinux:2 ・割当500CPUユニット 1500MB ・各インスタンスで1つずつ稼働 |
| EC2の場合 | m4.large(2vCPU 8GiB) | 2 | Amazon Linux 2 | Spring Bootアプリケーション ・各インスタンスで1つずつ稼働 |
コンピューティング(2)の構成
| 構成 | インスタンスタイプ | 数量 | OS | 稼働アプリケーション |
|---|---|---|---|---|
| ECSの場合 | m4.large(2vCPU 8GiB) | 2 | ECS-optimized AMI(Linux) | gRPCコンテナ ・FROM alpine:3.4 ・割当500CPUユニット 1500MB ・各インスタンスで1つずつ稼働 |
| EC2の場合 | m4.large(2vCPU 8GiB) | 2 | Amazon Linux 2 | gRPCアプリケーション ・各インスタンスで1つずつ稼働 |
■検証結果
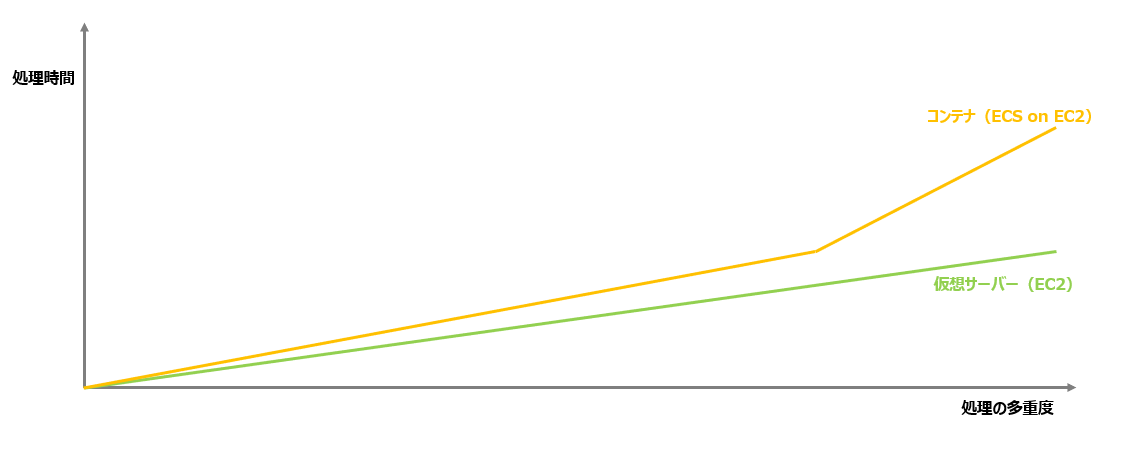
下記は検証結果のグラフの線形のイメージです。当然どちらの構成でも、処理の多重度があがると処理時間も増加してきますが、同等のインスタンスのスペックで見た場合、ECS構成の方が処理多重度が増えると処理時間の劣化が大きいという結論になりました。
平常時は大きな性能差はありませんが、高負荷時に処理時間が大きく劣化する可能性があるという結論のため仮想サーバー(EC2)構成の採用に至っています。
なお、ボトルネック調査のためネットワーク・OSの性能情報や処理のトレースなど各種情報を確認しましたが、処理の多重度があがるとコンテナ上のAPIが実行されるまでのタイムラグが徐々に大きくなっているようでした。ネットワークやホストOS側では異常値などは出ていなかったのですが、状況的にはDockerエンジン部分がボトルネックになっている可能性が想定されました。
最近だとコンテナ構成の選択肢が増えたので、どのパターンが最もインスタンス性能を使い切れるのか、性能維持やスケールしやすいのか、性能が頭打ちになった場合の挙動はどうなるのか、フットプリントの軽いベースOSに変えた場合の差など機会があれば検証してみたいですね。
- Docker on EC2
- ECS on EC2
- ECS on Fargate
- EKS
- Anthos GKE on AWS
(2)できる限りダウンタイムを短くする
GlyphFeedsサービスでは、マルチAZ構成を取り各インスタンスは必ず冗長構成を取るようにしています。
さらにマルチリージョン構成を採用し、単一のリージョン障害に対する可用性を高めています。
このように可用性を高める構成を採用していますが、冗長構成を取っても絶対に停止しないわけではないので、OS上のサービスの自動復旧やEC2のAuto Recoveryなどリソースが落ちたらすぐに復旧するような方式を採用し極力ダウンタイムを短くするアプローチとしています。
■GlyphFeedsサービスにおける主要な要素
| カテゴリ | マネージドサービス | 用途 |
|---|---|---|
| コンピューティング | EC2 | Web、API、非同期処理、コンテンツ加工、データ操作API |
| コンピューティング | Lambda | マネージドサービス間連携、時刻起動処理など |
| データベース | DynamoDB | コンテンツ(テキスト)格納 |
| データベース | RDS | アプリケーションマスタ格納 |
| 分析 | Elasticsearch Service | 検索エンジン |
| ストレージ | S3 | コンテンツオブジェクト格納 |
どのような障害まで想定するか?
AWSだと、Well-Architectedフレームワークやベストプラクティスに沿って設計/構築するだけで比較的容易にAZ障害に対する対障害性を確保できます。また、東京リージョンを見ても複数のAZで構成されており、自然災害などの物理障害に対しては極めて高い耐性があると思います。
では、ダウンタイム最少化のためにどのような障害まで想定するか? というところですがAWSでいうと多少検索するだけで過去にどんな障害があったか検索できます。
過去にマネージドサービスが長時間停止する障害が数回発生していますね。また、それらは単一リージョンに閉じた論理障害です。
(センター内の物理的な障害が起因して論理障害になったパターンもあるようですが)
そのため、複数のリージョンでサービスが稼働する構成の場合は、サービスを継続できていた可能性が高いと想定されます。GlyphFeedsサービスでは単一のリージョンダウンまでは発生しうると想定し、マルチリージョン構成を取ることにより、リージョン停止レベルの大障害が発生しても別リージョンに切り替えることによりダウンタイムを最小化しています。
構成のポイント
上記のようにマルチリージョン構成を取ることにより可用性は向上します。
では、具体的にどのような構成にするか? というところですがDRシナリオにも複数のパターンがありGlyphFeedsサービスでは、コストと効果のバランスを取り、パイロットライトとウォームスタンバイの間くらいの可用性になるように設計し、データのリカバリポイントは5分以内、切替/切戻は60分程度というサービスレベルになっています。
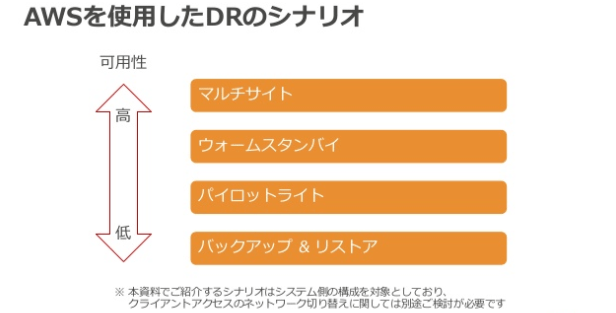
設計やバックアップサイトへの切替についても様々な方式があるので、サービスに適した方式を採用することで切替自体は比較的容易に実現することが可能です。
どのDRシナリオにしてもポイントになってくるのは非機能要件とクラウド利用料などコストを考慮して最もバランスの良い構成をとること、とデータも含めてメインサイトへの切戻ができることがあげられます。
より高可用な構成としてマルチクラウドによる構成なども考えられますが、果たしてサービスレベルはあがるのか? 意図したように切戻も出来るのか? などこちらも機会があれば検証を行ってみたいですね。
(3)柔軟なスケール
メディアCMS特有かもしれませんが、上の方で記載した特性の中で最も要件として定義が難しく、ぶれやすいのが、処理量のスパイクやデータ量の増加をどう見るか? という点です。メディアCMSでは繁忙期・閑散期というような概念はほぼなく、開催されるイベントの大きさによって著しく処理量や連携データ量(記事、写真、音声、動画などの数量)が増加します。さらに年々の機材の進化で取り扱うデータそのもの(写真、音声、動画など)のサイズが爆発的に大きくなってきています。
このように外部要因を含めてのサイジング難易度が高いことから、柔軟に自動でスケール出来るマネージドサービスを最大限に活用します。人手を介さず自動でスケールしてくれるという点で多大なメリットがありますがいくつか注意点もあります。
オートスケールの注意点
マネージドサービスの裏側ではコンテナやインスタンスが起動してくるので起動が完了するまでの待ち時間が発生します。待ち時間はマネージドサービスにより変わってくると思いますがマネージドサービスによってはスケールが完了するまで数分のタイムラグが発生します。
短い時間(数分など)に想定の何倍もの処理量が発生するような場合はスケールが追い付かなく、スロットリングが発生しその後タイムアウトや処理遅延が発生する可能性があります。
以下のような線形が発生し、あと数回スパイクが発生したら処理のタイムアウトが発生すると思います。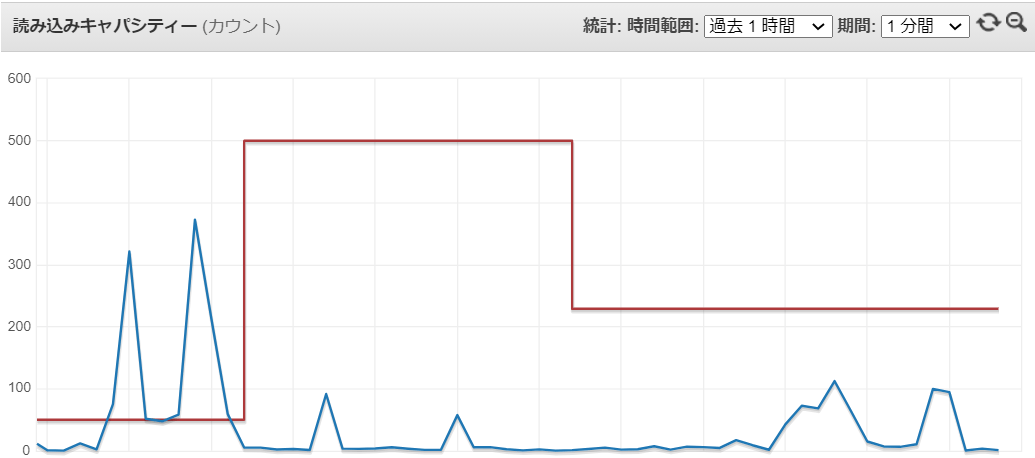
システムのスパイク特性やベースの性能をどう定義するか? スケール条件の閾値をどう定義するか? オートスケールを利用する場合でも完全に任せきりではなく、事前のシミュレーションや性能検証によるチューニングが必要だということになります。
最後に
当社の中では、自社サービスを展開しながら運用保守で上がってきた課題をダイナミックに改善していくという機会はなかなかないので貴重な経験となりました。設計してきたものが想定通り動いているのか? どの部分が乖離しやすいのか? なぜ乖離したのか? どう改善するか? などは長期的な視点が必要となるのでプロジェクトベースの仕事とは異なる知見が得られたと思いました。
また、システム特性を見極めることや、非機能要件を定義しどうコントロールしていくかというのは結局オンプレでもクラウドでも同じだなーと改めて思いました。