
2023.10.5追記: Goチームからプロジェクトの目的に応じたディレクトリ構造についてのドキュメントが公式に公開されています。 https://go.dev/doc/modules/layout
2020/11/13 「やってみてよかったことまとめ」「やってみて困ったこと」「外部モックサービスを使ったユニットテストの未来」の章を追記
2020/11/18 「やってみてよかったことまとめ」にSNSでもらったフィードバック内容を追記
はじめに
こんにちは、TIG 真野です。秋のブログ週間連載の第9弾です。
1年弱ほどGo言語でWeb APIアプリケーション開発を行っていますが、かなり割り切った構成・テスト方針を採用しました。そろそろ1年弱になり機能開発も比較的落ち着き、保守運用フェーズの割合も徐々に増えてきた頃合いなので、やったこと・学び・反省といった振り返りを共有します。
Goのパッケージ
Goのパッケージ構成については澁川さんの以下の記事が社内でよく引用されます。
記事でも触れられていますが、GoでWeb APIで開発するときのパッケージは golang-standards/project-layoutや、Goでクリーンアーキテクチャを試す の記事を目にすることが多いと思いますが、今回はこれを採用しませんでした。
代わりに澁川さん記事に影響を受けて色々削ぎ落としつつ、開発スタイルも色々と割り切りました。割り切りはトレードオフなので当然、対象ドメイン・規模・期間・要員などに依存してその都度の正解は変わってくると思います。1つの実験結果として見てもらえれば幸いです。
(2021/04/28追記)golang-standards/project-layoutに関してはRussが言及していますね!
this is not a standard Go project layout #117 https://t.co/uF8QblkJdF #reddit
— Go News (@golang_news) April 27, 2021
採用したパッケージ構成
澁川さん記事でいう、いわゆる “最小構成” を採用しました。これを試してみたという記事は見当たらなかったのでレア度が高い記事かもしれません。チーム規模は3-5人程度がコンスタントに開発していました。内部ではこの構成をフラットパッケージと呼んでいます。
- 実行ファイルは
cmdフォルダ内にアプリケーション(今回はAWS LambdaとローカルでポートをListenするサーバアプリの2種類) - 自動生成系は generate の略で
gen配下に出力。アプリ本体と分離するためこちらはあえて分離 docs,testdataなどを除くと、後はフラット構成です
<projectroot> # projectrootパッケージ |
パット見、 <projectroot> の直下に Goファイルが増えすぎない? と思われた方もいると思いますが、そのとおりです。1年くらいで ls -l | grep .go | wc -l すると50ファイル弱と育っていました。
また、このパッケージ構成を採用するにいたり、同時にいくつかの 割り切り を行っています。
割り切り構成サマリ図
今回の構成図を示します。
同一パッケージとはいえ、Handler, Model, DBが存在します。それぞれファイル名の命名で縛り責務を分離しています。
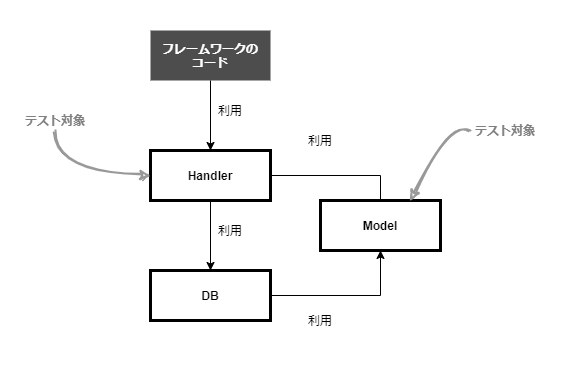
いくつか構成のポイントをあげます。
- Modelは独立させる
- Handler, DBはModelを利用する(Modelを生成したり、関数の引数に取る)
- DBのコードにのみデータアクセスライブラリをimportする(sqlパッケージやaws-sdkのコードはDB層にしか存在しないようにする)
- Handlerはフレームワークの求めるStructを引数や戻り値に取る
続いて割り切りポイントについて各レイヤーごとに説明していきます。
dbインタフェースを作らないこと
パッケージ構成とは別の話になりますが、永続化層などをインタフェース化 & 単体テストをモック化で素早くサイクルを回せるようにすることは良いプラクティスだと思います。しかし今回は採用しませんでした。理由は以下です。
- データ層をMock化すると、Mockコード開発の手間がある
- 慣れれば余裕だと思いますが、毎月新規参画者が入れ替わる環境だったので手間を減らしたかった
- Mockでは上手く動いても、実サービス(今回だとDynamoDBや、過去の経験だとRDB)に接続すると動かないケースが過去あった
- 実質的にモック環境と実サービス環境の2種類の動作確認が必要となり、すこし手間だなと感じた
- LocalStack という外部モックサービスをフル活用することで、ローカルに閉じてテストは可能
- 起動の手間はdocker-compose化することで抑えられる
- 結局モック用のデータを作るのと同様のテストデータ登録が発生するが、awscliなど永続化サービスの機能を経由することで、チームがデプロイ後の操作に早めに慣れることができる
これをやってみた感想を上げておきます(薄々やる前からわかることですが..)
- ❌ LocalStackのテストデータ登録・削除がボトルネックになる
- 外部サービスにテストが依存するので、並列でテスト実行が行えず make test待ちになることしばしばです(現在4分程度かかります)
- go test -v -run CreateArticleTest などと開発対象を絞って実行しますが、デグレ防止で全テスト実行したいときは待ち時間が億劫になります。開発規模によっては部分的にモック化するとか、LocalStackのテストテーブルをテストごとに作成するなど工夫が必要になってくるかなと思います
- △ そこそこリソースがあるPCじゃないと、LocalStack起動が重い。メモリ16GBあれば問題なしですが、8GBとかだと厳しいと思います
- 現在の社内支給PCだと問題にならなかったですが、4,5年くらい前だとスペック的に厳しい人もいたかも
- ◎ インタフェースを作らない≒handlerとdb の紐付けは1:1になるので、mainパッケージなど外部からのインジェクションが不要になり、コードがスッキリする(体感的に何割か記述量が減って激減、見通しが良くなりました)
handler, db はStruct化しない
これもパッケージ構成とは別の話になりますが、handler, dbはStruct化しませんでした。あくまで呼び出す関数だけそのまま公開しています
例えばDB層は以下のような構成です。
package <projectroot> |
DynamoDBなどのコネクションなどはどこで扱うかですが、db.goで初期化しています。
package <projectroot> |
この変数dbを、各xxx_db.go は直接参照しています
package <projectroot> |
いわゆる 変数db はグローバル変数のように影響度が大き過ぎるかもしれませんが、実用上は非常に楽でした。
今までは変数dbの初期化をmainパッケージかそれに近いところで行い、articleDB := NewArticleDB(db) のような初期化を行っていましたが、そもそもDB層のインタフェースも辞めたのでStructを作る必要もなくなり、上記のような初期化コードもなくなり、さらにコード量が減りました。
これをやってみた感想を上げておきます。
- ❌テストごとにdbを切り替えたいといった柔軟なことはやりにくい
- dbを切り替えると、アプリケーションの永続化層の全てが影響を受けるためです
- 例えば、あえて接続NGになるdbを設定して、異常系のテストを行うなどは行いにくいですし、今は行えていません
- ◎永続化層の機能追加が、≒関数追加になるので、思考が楽
- 関数を追加するための、Structを作って初期化して~などがなくなるで、思考のオーバーヘッドは楽になりました
- 過去はこの辺を自動化するgeneratorを作っていましたが、それすら叩かなくて良いのも良いです
- 関数を追加するための、Structを作って初期化して~などがなくなるで、思考のオーバーヘッドは楽になりました
- その他
- 変数dbを書き換えたりといった、お作法破りの開発者は現れなかった
- テスト時はLocalStack上のDynamoDB Localに代入するだけで楽(以下に例をあげます)
package <projectroot> |
Usecase層を無くした
xxx_handler.go はフレームワークにロックインされる(echo, go-swaggerなどのパッケージが入るという意味)なので、usecaseという安全地帯を作ろうという考えも最初はありましたが、結局は廃しました。理由は以下です。
- フレームワークを切り替えるときは別途工数を取るとことで開発オーナーと合意
- Goはhttptestなど標準ライブラリのテスト用のパッケージが存在し、仮にフレームワークを乗り換えたとしてもadaptorコードを書けばなんとか動きそう
- httptestを上手く使えば思ったよりポータブルなテストコードが作れた
- echo, go-swaggerなどGoのWebアプリケーションフレームワークは、handlerのテストをサポートしていて、テスタビリティはusecaseを切っても変わらない
- メンバーがusecaseを利用した開発に慣れている訳でもない
ここまでをまとめると、handler(Endpoint) --> usecase --> repository といったオーソドックスなスタイルではなく、 handler(Endpoint) --> dao的な何か という流れになりました。
こうすると、usecaseを再利用するような場合に困るんじゃないのと思います。困るときも多いのですが対策としてはなるべく model にビジネスロジックを寄せるという対応を取っています。下手にusecaseが存在しないので、modelはよく真ん丸と天高く馬肥える秋です。
やってみてよかったことまとめ
すでにいくつか書いていますが、改めてよかった点をまとめます。
- コード量が激減した(パッケージ、Struct、インタフェースを無くした効果)
- ボイラープレートコードが激減しました
- 当然、見通しもかなり良くなりまし、新規参画者の学習コストも下がりました
- 規模にもよりますが、ファイル数が100未満なら次も迷わずフラットパッケージ構成を採用したいと思っています
- .goのファイル数が200,300になるとサービスを分割しそうなので、サービス分割ポリシーと合わせればフラットパッケージでまず考えるのは悪くない選択肢かもしれません
- パッケージでレイヤーを無くしただけで、論理的なレイヤーがあるため、可読性はそこまで下がらなかった(コード規模にも寄りそうですが)
- パッケージを切ったとしてもどのみち責務を守っているかのチェックは必要なので、さほどやることは変わらないという表現が正しいかもしれません
- テスト用のMockを手作りすることに比べて、インテグレーションのトラブルは無くなった
- 副次的にAWS CLIなどの操作にメンバー全員が早期になれることができた
- Mockコードをgo generate することもないので、開発規約が減った
- ある意味、よくも悪くも初心者のメンタルモデルにとって “自然な構成” であるため、学習コストが低く、即戦力化しやすい
- 永続化コードの追加や呼び出しは本当にシンプル
やってみて困ったこと
- 関数宣言で、名前空間がかぶりがち
- Handlerで CreateArticle という関数を宣言したとき、 DBにも CreateArticle という関数を宣言しがちです。同一パッケージなのでバッティングするのは少し困るときがありました。今回はHandler側はHTTP Method名を先頭に付与するルールなので、 handlerはPostArticle、DBは CreateArticleと住み分けることにしました
testdataはフラットにしない方が良い- 実はtestdata以下のファイルもフラットにしていましたが、そちらは1テスト関数にN個のデータを作るので、現在150ファイル超えです
- 120~130ごろから探すのが面倒だなと思ってきます。そのため、testdata配下はフォルダを切った方が良いと思います
- なるべくmodelにロジックを寄せる(テストを寄せる)
- テストケースが増えるとどうしても実行時間が増えるのでビジネスロジックはmodel側に寄せる方針になりました
- handler, db, model内でのみ利用する関数を小文字始まりにするなど命名規約は最初に作ったほうが良さそう
- 全て同一パッケージなので、関数のパッケージPrivateにしてもアクセスできてしまうためです
外部モックサービスを使ったユニットテストの未来
gocloud.devのGo CDKのような、外部アクセス周りのインタフェースを統合したソリューションを上手く使うと今回LocalStackを用いた苦しみは減ってくると思います。GoCDKではDynamoDBのようなKVSにアクセスを抽象化してくれますが、メモリアクセス版に切替可能です。コレクションとかテーブルにsuffixをつけて並行にテストを実行するとおそらく今の100倍くらいテスト時間を高速化できるのでは? と考えています。
Go CDKについては過去の連載があります。
私もこのあたりでDynamoDBアクセスについて調査しました。
単体テストの自動実行はメモリモード、通常の開発時はLocalStackにアクセスするなどの使い分けができると未来が広がりますね。
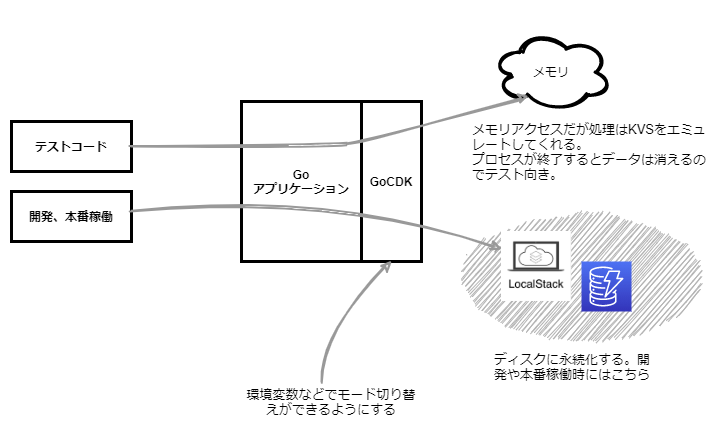
Go CDKのDocStoreのインタフェースは少しクセがあるので乗りこなすまで準備が必要そうですが、それによって得られるメリットはモックコードを利用せずユニットテストの高速化が可能ということなので、次のチャレンジに期待ください。
まとめ
簡単にまとめです。
- .goのファイル数が100未満であれば、フラットパッケージ、オススメです
- パッケージもシンプルにして、同時に極力Struct, Interfaceを排除した
- handler(Endpoint) –> usecase –> repositoryといった流れで制御フローが流すことが世の中多そうだが、endpoint側にロジックを実装、repositoryは無くして直接db層の関数を呼び出した。初期化はdb.goにdbのclientを初期化してそれを使う
- modelになるべくロジックを寄せたた
- testはhandlerの関数単位で行う
- DB層をインタフェースを経由せずに扱うことはLocalStackなど外部モックサービスを利用すれば問題にならなかった
上記によって色々柔軟性は失われたかもしれませんが、少なくてもコード量はグッと減り開発スピードの向上に寄与できるかもしれません。
最後まで読んでもいただき、ありがとうございました!