
はじめに
こんにちは。TIG DXユニット所属の村上です。
最近データ分析絡みでDynamoDBを触る機会が多く、DynamoDBが体の一部みたいになってきました。
本記事の結論はこれです。
大量に取得したいデータに共通して存在する値の属性をGSIとして設定しよう
予備知識から順に解説していきます。
ScanとQuery
DynamoDBにはScanとQueryという操作が存在します。それぞれ簡単に説明すると、以下のようになります。
- Scan:DB全体を取得する操作
- Query:指定した属性に指定した値を持つデータのみを抽出して取得する操作
取得したいデータがDBに存在するほとんど全てのデータであれば、Scanで取得するのが効率的なのですが、必ずしもそのような状況であるとは限りません。Queryによって、特定の値を持つデータのみを取得したい場合もあると思います。
今回は後者の場合を想定し、Queryによって特定の値を持つ大量のデータを効率的に取得する方法について解説します。
DynamoDBの制限
DynamoDBから効率的にデータを取得するにあたり、DynamoDBに存在する制限を知っておかなければなりません。今回対象とするQuery操作には、1度のQuery操作での取得サイズ上限は1MBという制限が存在します。詳しくは公式ドキュメントをご覧ください。
この制限を超えるサイズのデータを取得する場合、Query操作を繰り返し行うことによって全てのデータを取得することになります。従って、大量のデータを取得する場合は1回当たりのQueryで上限の1MBをしっかりと使い切ることが、効率的なデータの取得につながります。
GSI(グローバル・セカンダリ・インデックス)を工夫する
DynamoDBから特定の条件を満たすデータを大量に取得する場合は、GSIを工夫することが重要となります。これについて順に解説していきます。
GSIの特徴
GSIには重複が許されるという特徴があります。実際にDBを操作しながら見ていきたいと思います。
今回の実験では最近愛用しているNoSQL Workbenchというアプリを使います。これはクラウドやローカルのDynamoDBをGUIで操作、可視化できるツールで、AWS公式から配布されています。ダウンロードはこちら。
パーティションキーとソートキー
DynamoDBにはパーティションキーとソートキーという概念があります。GSIのパーティションキー、ソートキーと呼び方を区別するために、本記事ではプライマリパーティションキー、プライマリソートキーと呼ぶことにします。
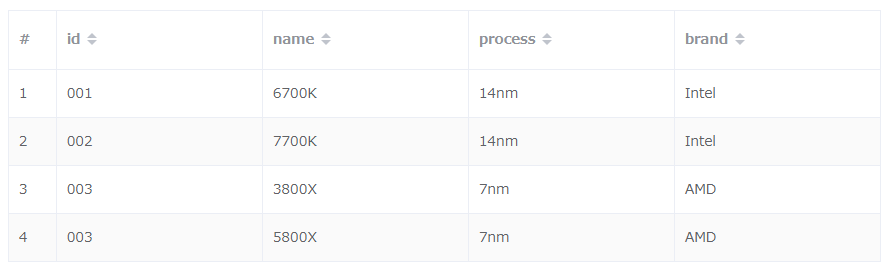
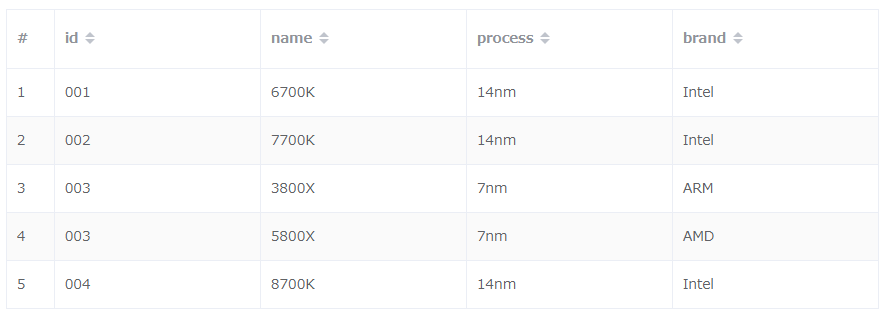
基本的にはこれらの値の組み合わせが重複することは許されません。例えば以下のような設定と内容のテーブルに対してこれらが重複したデータを追加しようとしたらどうなるか試してみます。
テーブル設定
| データ項目 | キー |
|---|---|
| id | PK |
| name | SK |
| brand | GSI PK |
| process | GSI SK |
※PK:パーティションキー、SK:ソートキー
テーブル内容
実験
既存のデータと同じキー値
- id:003
- name:3800X
に対して、brandだけ違う値にしてPutItem操作を実行してみます。
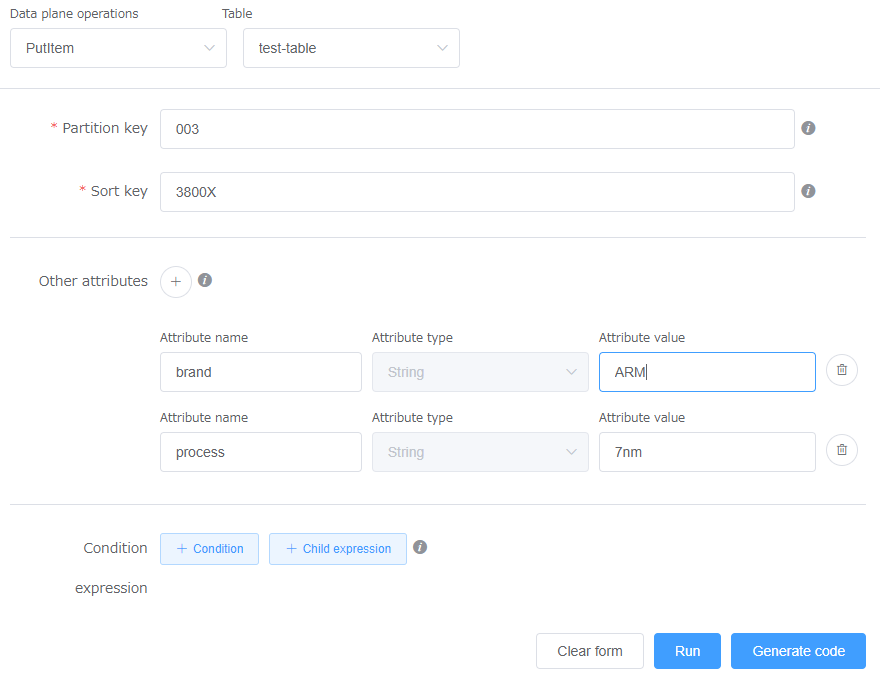
PutItem操作実行後のテーブルの様子です。データ数は変わらず、同じキー値を持つデータが上書きされています。
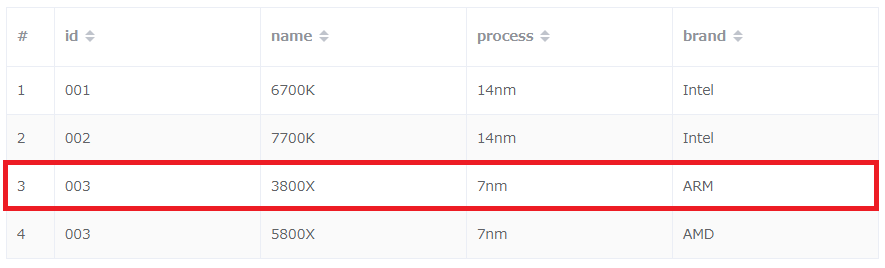
このように、プライマリパーティションキーとプライマリソートキーの同じ組み合わせに対する重複は許されておらず、同じキー値でデータを追加しようとすると、そのデータが上書きされます。
GSIのパーティションキーとソートキー
一方GSIのパーティションキーとソートキーの組み合わせに対しては、重複が許されています。従って、先ほどのテーブルで1行目と2行目のデータのbrandとprocessは全く同じですが、brand、processをそれぞれGSIのパーティションキー、ソートキーに設定しても、片方のデータが消えることはありません。テーブル設定に記載の通り、すでにこれらのGSI設定は適用済みです。
ここにさらにbrandとprocessが重複するデータを追加してみたいと思います。
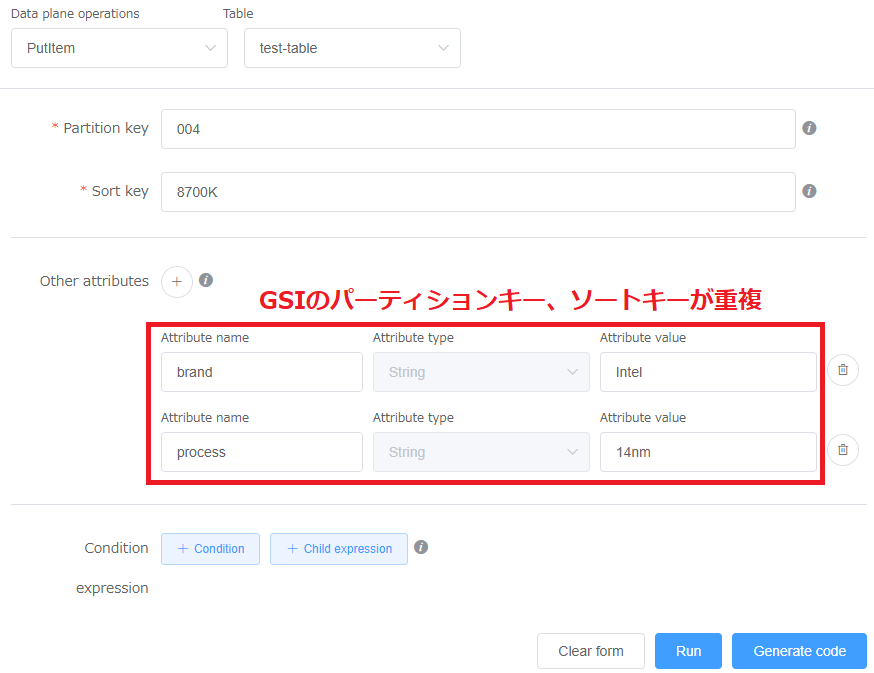
PutItem操作実行後のテーブルの様子です。データが上書きされることなく、追加されている様子が確認できると思います。
GSIの大量データ取得への応用
以上の実験により、以下のことがわかりました。
- プライマリパーティションキー、プライマリソートキーの組み合わせの重複は許されない
- GSIパーティションキー、GSIソートキーの組み合わせの重複は許される
これらの性質より、大量に取得したいデータに共通して存在する値の属性をGSIとして設定することで、欲しいデータをごっそり取得することが可能となります。
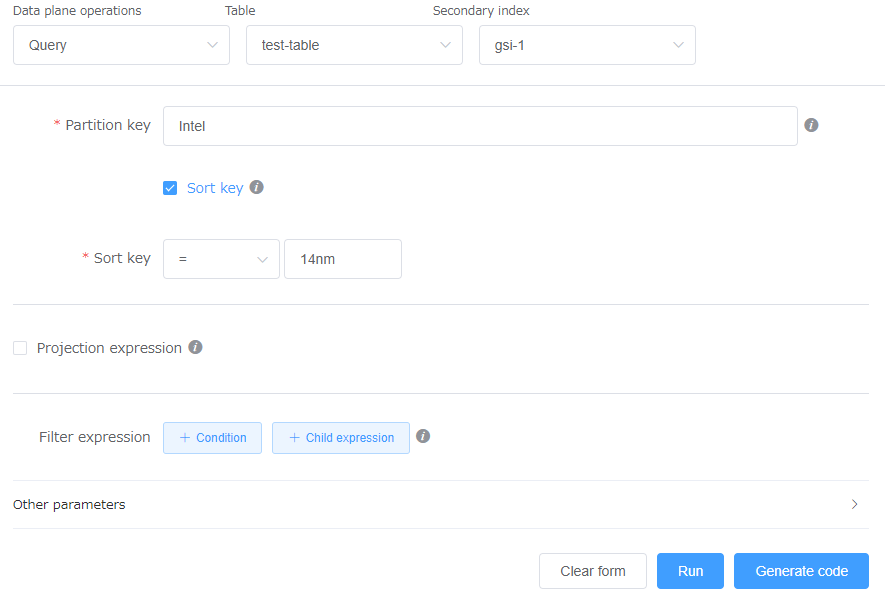
実際にこの性質を利用してQueryしてみたいと思います。
GSIパーティションキーであるbrandにIntel、GSIソートキーであるprocessに14nmを指定します。
Query操作の実行結果です。
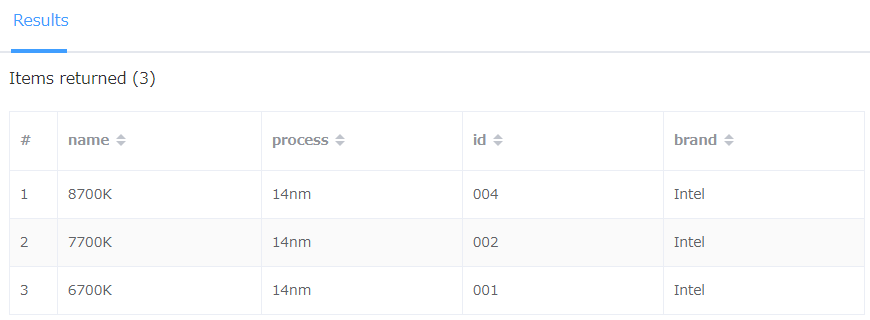
指定した値を持つデータを1発で全て取得できました。
今回の例ではそもそものデータ数が少ないため、1度のQueryで目的のデータを全て取得できましたが、実際には大量のデータを取得することを想定していますので、冒頭で説明したQueryの1MB制限に引っ掛かることが前提となります。よって、Queryを繰り返し行って目的のデータを全て取得することになります。この時、1MB制限を上限いっぱいまで使うことができるため、効率的であると言えます。
備考
そもそもプライマリパーティションキー、プライマリソートキー自体が「大量に取得したいデータに共通して存在する値の属性」であれば問題ないのですが、一般的にDynamoDBでプライマリパーティションキーとプライマリソートキーをこのような観点から設計することはあまりないと思います。また、GSIは後から追加できるという拡張性の高さからも、GSIの工夫が重要となります。
まとめ
今回はDynamoDBから特定のデータを効率的に大量に取得する方法について解説しました。
他にも「こんな方法があるよ」などのご意見ありましたら是非教えていただけると嬉しいです!