GCP連載の第3回目はCloud Operationsの機能を試してみます。DebuggerとProfilerを試してみます。本当は仕事で使っているGoでやってみようと思ったのですが、Debuggerのドキュメントをみたら、現時点でGoはまだ実験的サポートで、Cloud Runは非対応、Goのバージョンも1.9以下という状況でしたので、サポートが手厚いPythonで試しました。
gcloudコマンドの設定
まずGCPの環境で、gcloudコマンドを入れます。M1 macには入れていなかったので入れてみたのですが、こちらに従ってやりました。普通のインストールでは途中でエラーになり、この紹介記事と同じく、最後にinstall.shを自分で叩く必要がありました。
プロジェクトIDは自分で入力する名前に何か数値が後ろについたようなやつです。プロジェクト一覧に出てくるserverless-12345のようなものがIDです。
# 初期化とプロジェクトの選択 |
プロジェクトを作る
Cloud Runで試しで動かすプロジェクトを作ってみます。Poetryを使ってFastAPIなプロジェクトを作ってみましょう。作ったアプリケーションはCloud Runで実行します。
# 一度だけやるPoetryのインストール |
開発環境の設定
まず、ライブラリを追加します。なお、uvicornですが、最近になって、uvloopとhttptools、websocketといった依存ライブラリは明示的にインストールしないと実行時にエラーになるように変わったみたいです。
poetry add fastapi uvicorn uvloop httptools |
ここで.venvフォルダができ、ライブラリ類はそこにインストールされます。処理系がそこをみてくれるように設定すれば、コード補完とかが効きます。PyCharmであれば設定で検索ウィンドウにvenvとタイプするとインタプリタ選択がでるので、追加してプロジェクトフォルダの.venv以下を設定します。
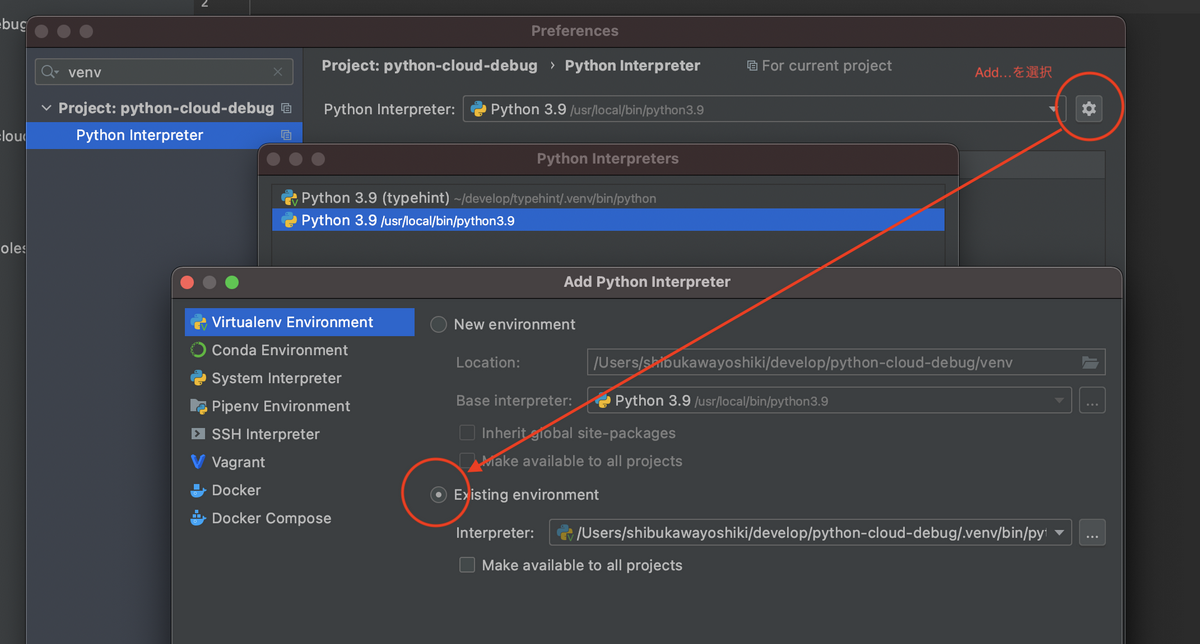
VSCodeは特になにもしなくてもよさそうです。開くだけで.venvフォルダを認識してオープンしてくれました。
アプリケーションを作ってみる
FastAPIのサンプルを持ってきました。
from typing import Optional |
次のように実行するとローカルの8000番ポートで起動します。ブラウザでlocalhost:8000にアクセスしたらJSONが表示ができることを確認します。
poetry run uvicorn python_cloud_debug.main:app --reload |
コンテナを作ってpushする
Dockerfileは以下の通りです。ちょびっと工夫したのは以下の2点
- 実行イメージでpip installするとイメージサイズが50MBぐらい違いますし、ネイティブコンパイルが必要なパッケージだと実行イメージにコンパイラを入れないといけないので、site-packagesをコピーする手法を選択
- Cloud Runの作法にはPORT環境変数でポートを変えよ、というものがあります。それをsh -cで実現しましたが、今度はCtrl+Cでシャットダウンが効かなかったので、execをつけたところうまくいきました(@moriyoshit さんに教えてもらいました)。
あとは、Python 3.7じゃないとうまくいかなかったので3.7にしています。
FROM python:3.7-buster as builder |
ローカルでビルドしてうまく動くことを確認したらpushします。リポジトリに入れてクラウドビルドをする方法も最近は使えます。とりあえず手元で動かしてプッシュしてみます。M1 macの場合は–platform linux/amd64が必要です。
# ビルド |
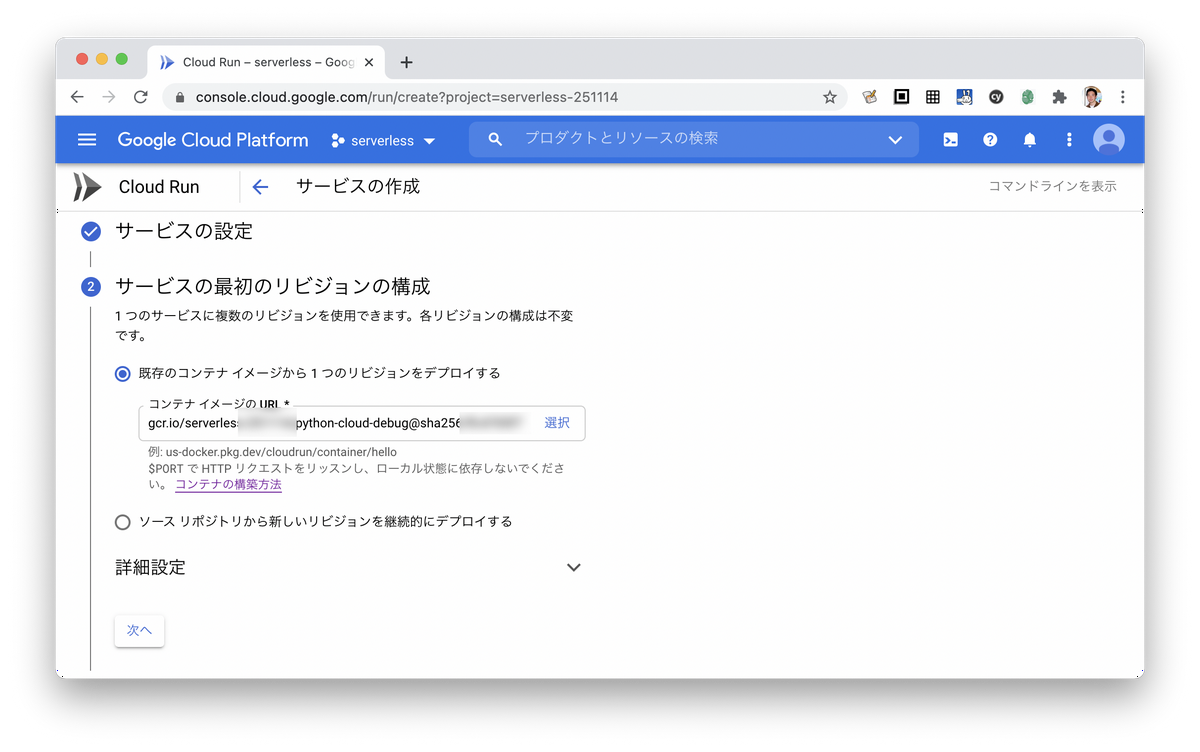
これを使ってCloud Runに登録して実行してみても良いでしょう。アプリケーション名を入れて、このpushしたイメージ名を選択して外部公開してあげれば簡単に起動できます。それ以外にはリポジトリと連携してCloud Buildする方法も選べます。デバッガーではソースコードを別にpushしないといけないのでそっちの方がいいかも?
デバッガーを使ってみる
それでは本題のGCPのAPIを使ってみます。必要なライブラリを足しつつ、先程のコードのapp = FastAPI()の前に次の内容を入れます。ローカルでは外部依存なく気軽にテストしたいので、poetryの依存に入れず、実行イメージの中でのみ追加して、LOCAL=trueという環境変数があればロードしないようにします。
pip3の行を次のように書き換えます。
RUN pip3 install poetry google-python-cloud-debugger |
アプリへの追加はこれだけです。
if "LOCAL" not in os.environ: |
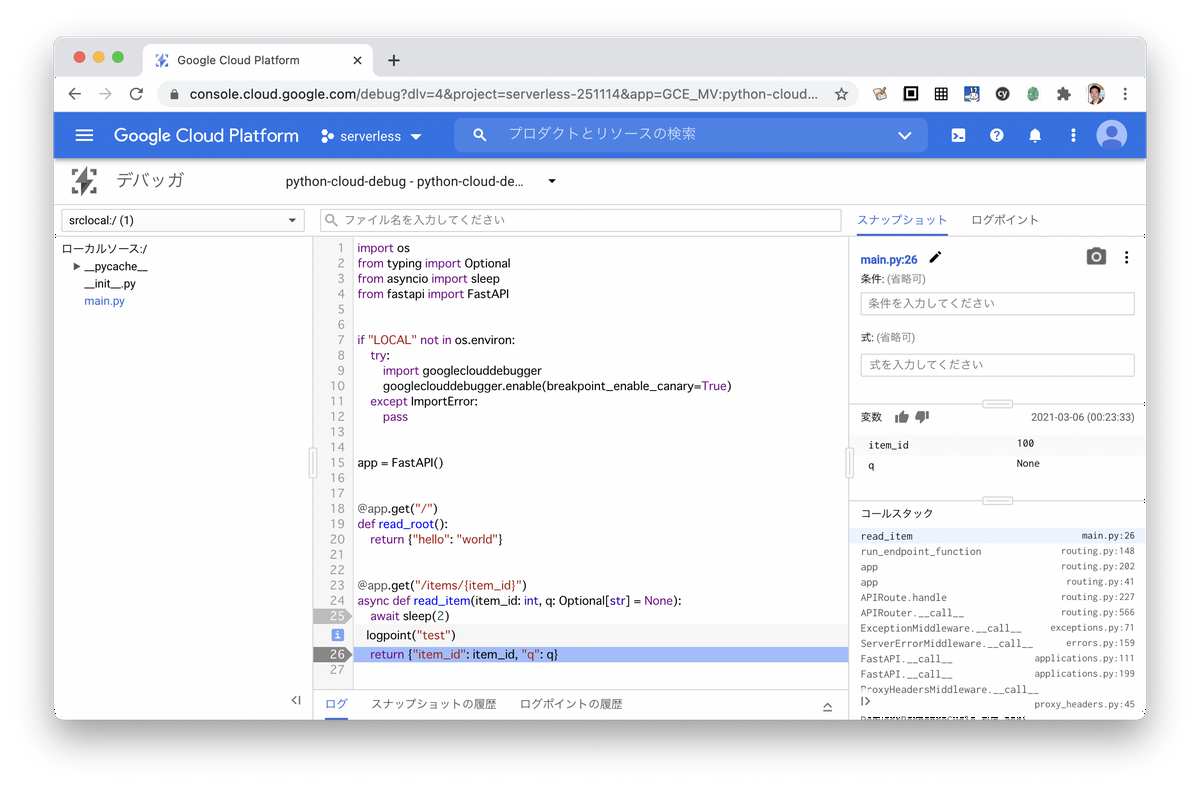
これをビルドしてCloud Runを実行してみたらDebuggerの画面を開きます。まず開くと、ソースコードをアップロード白、と出てくるのでpython_cloud_debugフォルダを選択してアップしました。クラウドビルドだとこの手間なくできるみたいですね。
スナップショットを設定すると、その行が実行されたときにローカル変数やコールスタックが表示されます。またログポイントでログ出力を挟み込むこともできます。実行環境にそのまま差し込めるのは便利ですね。
プロファイラを使ってみる
せっかくなのでプロファイラも使ってみます。こちらはPythonであっても、Cloud Runはまだサポートされていません。ドキュメントにはグーグルのサービスではCompute Engine、GKE、GAEのみが対象となっています。ただ、自分でクレデンシャルを設定したらGCP外からも使えるとは書かれていて、この手順を試して成功したのですが、やっていることはプロファイラのエージェントのロールを付与しているだけなので、Cloud Run実行のサービスアカウントにプロファイラエージェントのロールをつければいけます。
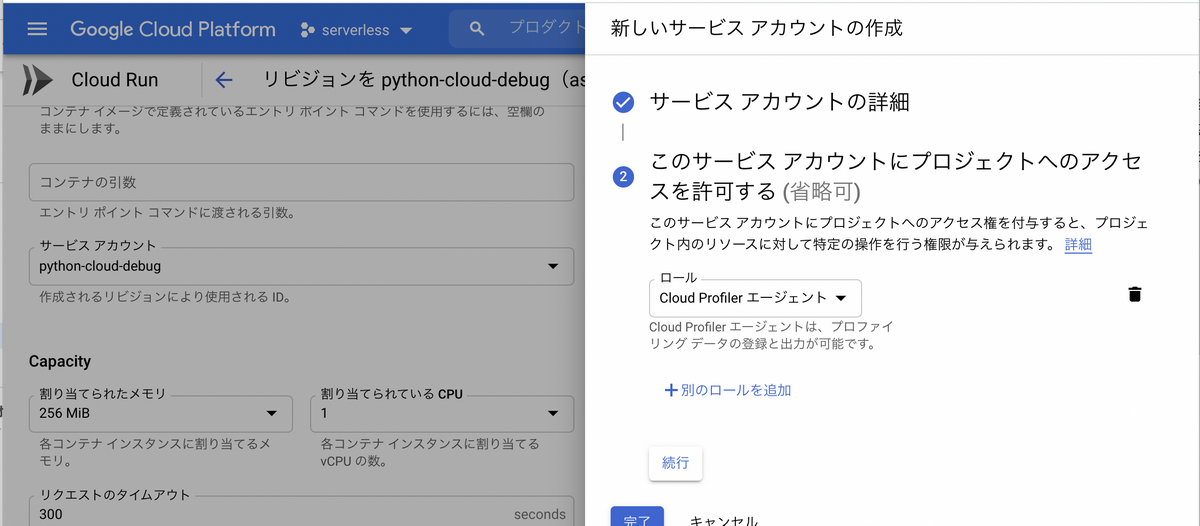
先程のDockerfileにプロファイラのライブラリのインストールも追加します。また、先ほど作ったクレデンシャルのファイルも登録して、そのファイルのパスを環境変数に設定します。本当は環境変数でファイルの内容を渡して、Pythonコードでそれをまずファイルに落としてあげる、環境変数はCloud Runの設定に入れてDockerイメージに入れない、みたいなことをやった方がセキュアな気がしますが、手取り早くファイルを足してしまいます。
RUN pip3 install poetry google-python-cloud-debugger google-cloud-profiler |
デバッガーの設定のところでプロファイラを開始する関数の呼び出しを追加します。
if "LOCAL" not in os.environ: |
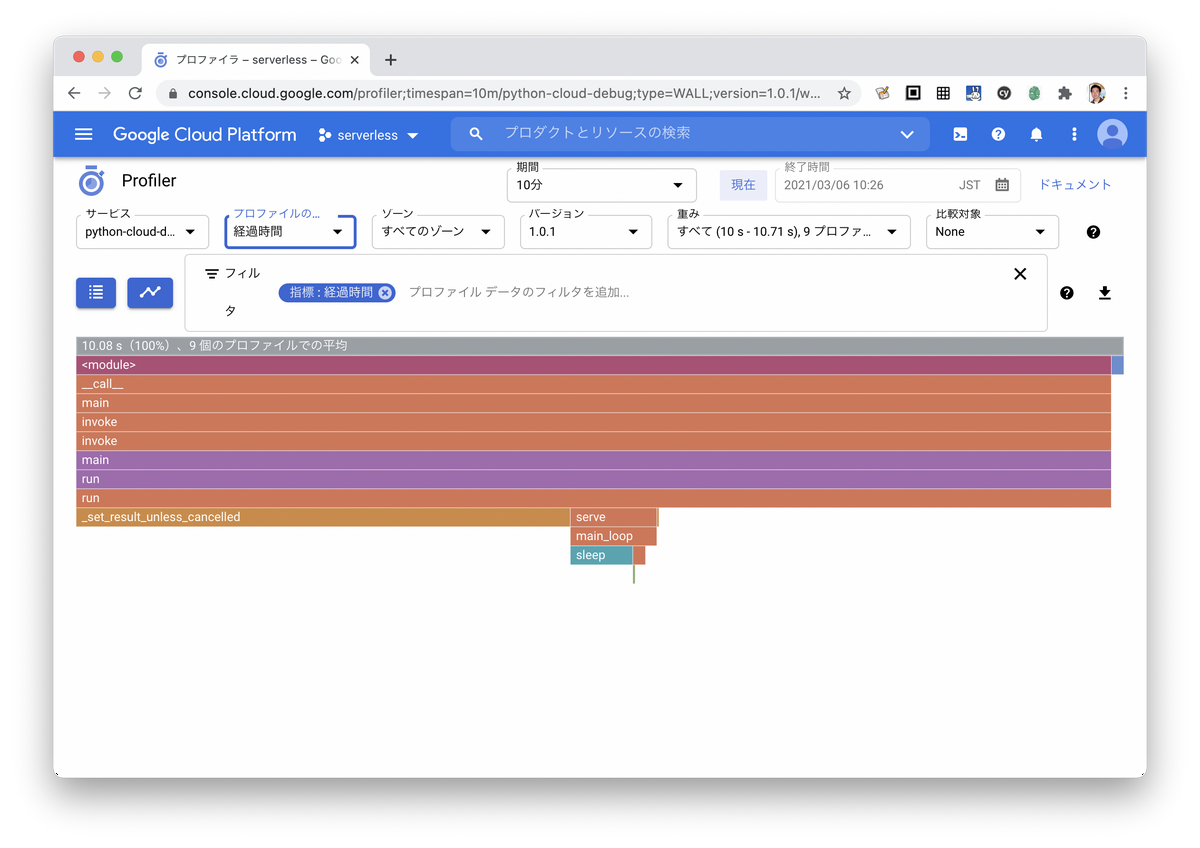
プロファイル画面をみてみたら、フレームグラフが出ました。ちょっとスリープを挟んでみても、自分で書いたコードのフレームが出てこないのですが、きっとCPUヘビーなコードが出てきたらすぐにわかるんじゃないですかね。すくなくとも、time.sleep()でも、asyncio.sleep()でも結果には出てきませんでした。
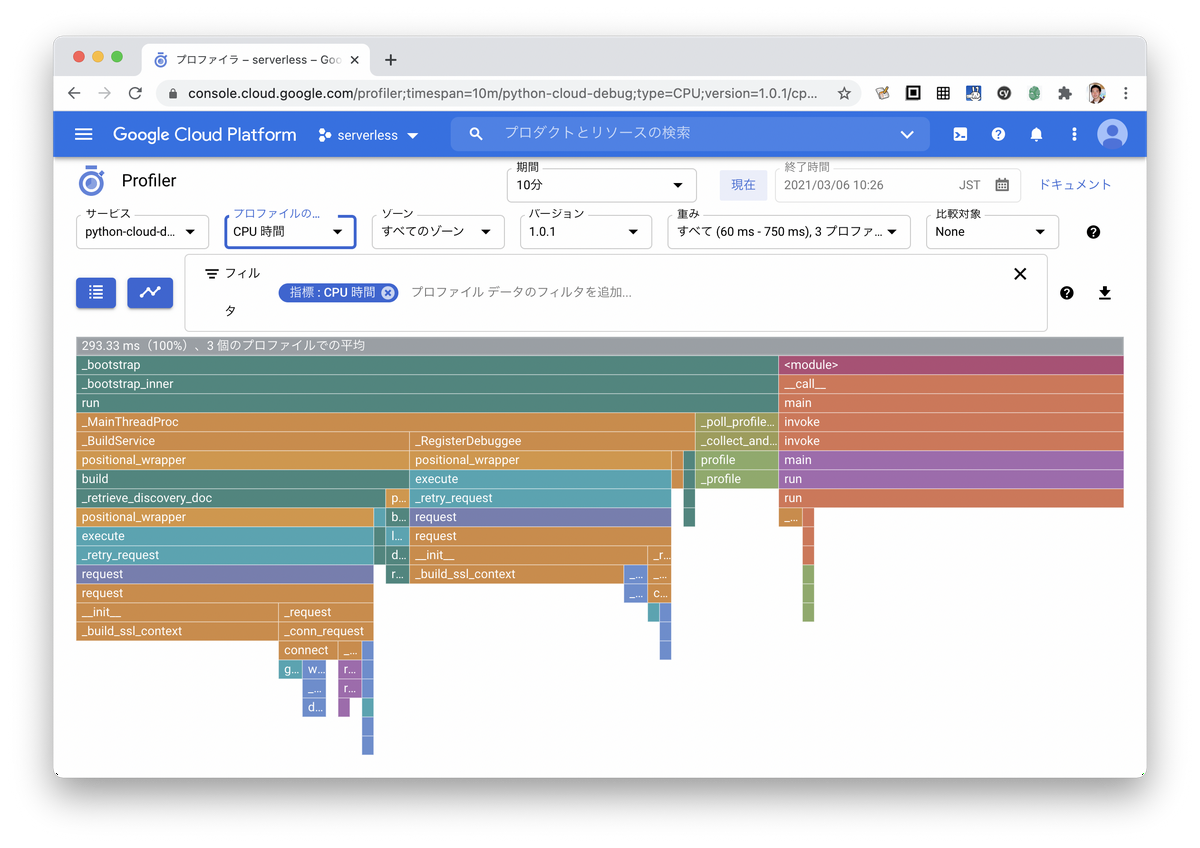
CPU時間のグラフはこんな感じです。きっとプログラムがヘビーになったら活躍してくれるはず。
まとめ
StackdriverあらためCloud OperationsのDebuggerとProfilerを試してみました。Goサポートがまだだったり、Cloud Run対応がまだだったりとかはありますが、OpenCensus/OpenTelemetryなみに頑張らなくてもちょっとmainのところにコードを足すだけで本番環境の中身を覗いたりプロファイルが取れるのは面白いですね。そのうち、ローカルのデバッグよりもリモートの方が簡単、みたいになってくれそうな気がしました。
明日は村瀬さんのText To Speechです。