はじめに
TIG DXユニット 1真野です。
個人利用など、ごく小さなサービスなどでない限り、複数件のレコードを一括でデータストア層へ登録する必要は出てくると思います。この時1件ずつループ処理で登録するのではなく、効率性などの観点で各データストアが提供する一括登録の仕組みを利用すると思います。
RDBであればバルク(Bulk Insert)とかバッチ(Batch Insert)の登録手段が存在すると思います。PostgreSQLであればCopy句で、OracleであればSQL*Loaderを使ってCSVを直接読み込ませる方法があります。
この記事ではCSVなどの一括登録ではなく、Batch Insertの実装について触れていきます。タイトルはバッチ登録ですがバッチ検索でもバッチ削除でも同じように役立つ内容かと思います。
バッチ登録を行う側で気をつけること
例えばAWS DynamoDBであればバッチ登録(BatchWriteItem)では1操作で最大25項目までしか対応していません 2(RDBであればこうした分かりやすい数値的な上限はないかと思いますが、クライアントとDBサーバ側の主にメモリ資源を使いすぎないように、例えば1000件ずつなど小分けして登録することが多いかと思います)
つまり、DynamoDBであれば120件のデータをBatchWriteItemで登録するためには、最低でも5回(25件×4回+20件×1回)の操作が必要です。
こうした、1操作で登録しきれない件数のバッチ登録(Batch Put)するときの実装方法ですが、書く人によって色々種類があることに気が付きました。すこし面白かったので本記事ではまとめます。データストアはDynamoDBを利用しますが、どのデータストアでも伝わる部分があると思います。DynamoDBって何か気になって先に進めない方は、富山さんの【入門】私を苦しめたDynamoDB記事がおすすめです。
コードはこちらにまとめました。
各イディオムで用いる共通部分
各イディオムに入る前に永続化に用いる関数を用意します。ローカルでも動かせるようにLocakStackを利用します。これの実装は本題じゃないので読み飛ばし推奨です。
func BatchWrite(ctx context.Context, writes[]Forum) error
BatchWriteの実装についての詳細(※👈クリックで開く。読み飛ばしてもOK)
// LocalStackを用いるための初期化部分(読み飛ばしOK) |
dy を用いて以下の永続化用の関数を用意します。25件以上であるときはエラーにしていること以外は、UnprocessedItemsの救済の為に少し処理を追加しています。
// 永続化関数(読み飛ばしOK) |
永続化対象の Forum テーブルを示すモデルですが、AWS SDK for Goのドキュメントに書いていた構造です。
// 永続化対象のモデル(読み飛ばしOK) |
(1)素朴なバッチ登録実装
本題のイディオムです。まずは素朴にループを回す実装です。何も考えずに実装すると多くの人が最初にこのコードを実装するのではないでしょうか? LoadForums は[]Forumを返す、数百~数千件くらいのCSVを読み取るような処理をイメージください。
func main() { |
最初のfor文で1行ずつスライスに要素を追加し、指定件数(今回だと25件)になったタイミングで BatchWrite を呼び出し永続化します。最後の if文のブロックでは、1件以上かつ25件未満のケースを救済しています。
便宜上、素朴と表現しましたが、IteratorパターンのようにHasNext/NextしかAPIを公開されておらず次のレコードの有無がわからない場合はこういったアプローチを取るしか無い場合もあるので、利用シーンも少なからずあるかと思います。
(2)すこし進化したバッチ登録
さきほど書いた素朴なコードですが、少し冗長な部分があります。for文とif文のBatchWrite呼び出し部分が重複しており冗長ですね。ここをスッキリさせたバージョンが次です。
func main() { |
for文の中のif文で、BatchWrite を呼び出す条件を変えました。スライスが25件に達した時に加え、 最終行の場合にも 分岐を通すようにします。for文の後にあった BatchWrite の分岐を消せました。かなりスッキリです。
今回は、処理対象のレコードがすべてスライスになっている(メモリに読み込んでいる)状態ですが、これが巨大なCSVファイルを入力とするケースでは、1, 2の実装のように逐次的な処理をする必要があると思います。
(3)少しエレガント実装
新規にスライスを宣言せず、読み取ったスライスから部分スライスを作成する実装です。少しトリッキーに見えるかもしれませんが、そんなに難しいことをしていないです。ポイントはループ変数 i ~ i+25(end) で部分スライスをループ毎に作るというアプローチでしょうか。
func main() { |
イメージしにくい方のために、バッチサイズを5、処理対象のレコード数が13での動作イメージを書きました。
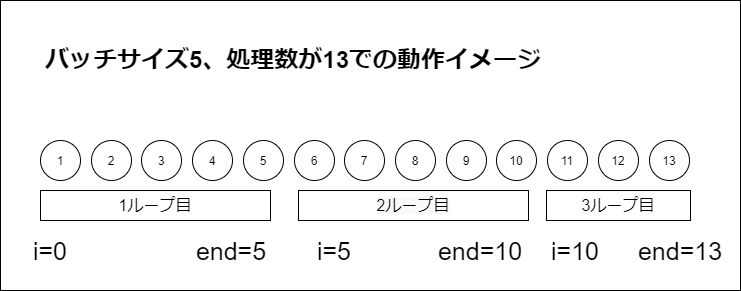
もしも、最初から BatchWrite したいレコードがスライスの状態にある(メモリに載っている)のであれば、この実装方法が可読性もそこまで落ちず、かつ最も効率が良さそうです。
まとめ
- バッチ登録のイディオムはいくつかパターンがある
- メモリに載っている場合は、(3)のように元のスライスからサブスライスを作る方法が良さそう
- 入力データが巨大な場合は、(1)、(2)のような逐次的な処理を入れる必要が出てきそう
Goだとgoroutineとチャネルを利用してこうした複数チャンクに分割しつつ、並列にデータ登録することも容易にできそうですね。そのあたりも機会があれば書いていこうと思います。
- 1.Technology Innovation Group(TIG)は、「最先端、且つ先進的なテクノロジーのプロフェッショナル集団」「プロジェクト品質と生産性の向上」「自社サービス事業の立ち上げ」を主なミッションとする、技術部隊です。 ↩
- 2.https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_BatchWriteItem.html ↩