TIGのDXユニットの渋川です。Serverless連載2021の最後の記事になります。sam周りとかLambdaの挙動については@r_rudiさんに色々教えていただきました。ありがとうございます。
巨大な学習済みの機械学習モデルとか、検索用インデックスをデプロイする場合に、どうやってデプロイするか、というのは色々選択肢があります。以前、ちょびっとだけ「どうやってデプロイしましょうかね」というのを悩んだ時期があったのですが、今回、こんな方式が考えられるんじゃないか、というのを改めて調べてリストアップしてみました。
それぞれの容量は2021年6月現在の数値ですので、最新情報は各々リンク先を確認してみてください。AzureとかAlibaba Cloudとかは仕事柄扱うチャンスが今のところないので調べてないですが、もし調べた方はぜひ教えてください。
| クラウドベンダー | サーバーレス方式 | ストレージ | 容量 | バンドル | ファイルアクセス | その他 |
|---|---|---|---|---|---|---|
| GCP | Cloud Run | コンテナイメージにバンドル | 5TB(Cloud Storageに準ずる) | YES | ||
| GCP | GKE Knative | Cloud Storage | 5TB(Cloud Storage参照) | |||
| GCP | GKE Knative | Persistent Volume | 16TB-60TB(File Store), 16TB(Cloud Volumes) | YES | Auto Pilotでは使えず | |
| AWS | Lambda | 標準ランタイム(レイヤー) | 展開後250MB | YES(レイヤーは後付け可) | 専用実装が必要 | |
| AWS | Lambda | コンテナイメージにバンドル | 10GB | YES | 専用実装が必要 | |
| AWS | Lambda | EFS | 48TB(EFS) | YES | ||
| AWS | App Runner | コンテナ | ECR次第? | 実行時間制限など情報なし | ||
| AWS | Lambda/App Runner | S3 | 5TB | 5GB以上は分割アップロードでめんどい |
大きくは外部ストレージサービス利用と、アプリケーションにバンドルしてしまう方式と2つにわかれます。バンドルはデータだけ更新ができないデメリットはありますが、お手軽です。Lambdaはレイヤーを使えば実行プログラムに対して後から追加とかできますが、容量制限が厳しめです。
オブジェクトストレージは比較的お手軽ですが、読み込みしたいライブラリがローカルのファイルシステム前提の場合は使えません。サーバーレスの方式によっては、一度ローカルのファイルシステムに書き出してから利用とかも可能ではありますが、Cloud Runでは8GB(ただし、おそらくtmpfsで書けば書くほどメモリを消費)、Lambdaでは500MBと容量に制限があります。
より巨大な学習済みデータを扱う場合はマネージドNFSサービス系のものを使うのが最終形でしょう。ファイルのサイズ制限もほぼ限界値ですし、ローカルファイルになるのでどんなランタイムでもファイルが利用できます。Cloud Run大好きなのでGKEのKnative + Persistent Volumeを試そうかと思ったのですが、期待の簡易起動のAutopilotではCloud Run相当(Knative)が使えず、いろいろ面倒そう。がんばって試しても良かったのですが、こんな面倒なのはそのうち簡略化されると期待して、強い意志を持ってスルーすることにしました。Dockerのボリュームなみに簡単になって欲しい。
とりあえず手元のケースでは10GBを超えるようなものはいまのところなかったので、 Lambdaコンテナの10GB制限で十分そうです。ということで、本エントリーではお手軽なLambdaのコンテナランタイムを試してみようと思います。
Lambda + コンテナ
2020/12/1にLambdaがコンテナをサポートしました。今までは特定の言語ランタイムのみが便利に利用可能(いちおうカスタムランタイムもできる)でした。Lambdaのコンテナも特定のベースイメージもしくはランタイムをインストールしたイメージを作って利用なので、自由度という点では今までとそこまで変わるわけではありませんが、10GBまで可能になればできることは大きく増えます。楽しみですね。
| 言語 | イメージ |
|---|---|
| Node.js | ECR, DockerHub |
| Python | ECR, DockerHub |
| Java | ECR, DockerHub |
| Go | ECR, DockerHub |
| .Net | ECR, DockerHub |
| Ruby | ECR, DockerHub |
コンテナになったとはいえ、コードはLambdaの流儀で作る必要があります。GCP Cloud RunやAWS AppRunnerのようにポータブルなどこでも動かせるウェブアプリケーションを実装するのを期待する人がいるかもしれませんが(僕です!)、残念ながらそうではなく、Lambda用のハンドラを定義してあげる必要があります。こんな形です。詳しくは当ブログのServerless連載2: AWS Lambda×Goの開発TipsのLambdaの関数タイプを参照ください。
ミニマムなのはこんな形です。
package main |
これをDockerfileでビルドします。マルチステージビルドしています。あんまり明示的に書くことはないかもですが、M1 Macでビルドすることを考えてGOARCH=amd64を明示しています。最終的なpublic.ecr.aws/lambda/goはlinux/amd64しかないのですが、マルチステージビルドのGoイメージは複数アーキテクチャ対応なのでamd64バイナリができるようにしなければなりません。新しく入ったBuildKitの機能であるbuildxを利用して、docker buildx –platform=linux/amd64でビルドしてもいいのですが、buildxでamd64にするよりも、↓を使った方がちょっと大きいアプリケーションで10倍ぐらい高速(200秒超と20秒)だったので、こちらの方が良いでしょう。
あとは、最終的なアプリケーションをLAMBDA_TASK_ROOTという環境変数の場所に置くのがポイントですね。
FROM golang:1.16-buster as builder |
curl -XGET http://localhost:9000 |
このDockerイメージはLambda専用なので、いくつか決まり事があります。
Lambda用のエージェントがイメージのエントリーポイントにいて、そいつが8080ポートで動作していますので、次のようにポートをマッピングして起動します。
docker build -t lambda-test . |
起動すると、/2015-03-31/functions/function/invocationsというパスにトリガーとなるエンドポイントが用意されます。2015年3月31日ってなんやねん、と思われるかもしれませんが、このパス決めうちなので仕方がないのです。追加のパスを投げることもできません。諦めてください。次のコマンドで起動します。-d '{}'は必須です。外すとエラーになります。
$ curl -XGET http://localhost:9000/2015-03-31/functions/function/invocations -d '{}' |
これでテストできますよーとドキュメントにはありますが、半分本当で半分嘘です。というのも、実際にウェブサービスとして起動するには API Gatewayをトリガーに設定して起動します。これがHTTPリクエストをJSONに変換してからlambdaに渡します。このDockerイメージは変換後のJSONを期待しています。本番で次のようにボディとしてJSONを渡したいとします。
パスが固定という説明をしましたが、ローカルではクエリーパラメータを付与してもダメでした。AWS上のLambdaは大丈夫です。
curl http://example.com -d '{"hello": "world"}' |
ローカルでテストするときは、ボディを文字列化し、それをbodyキーに入れたJSONを作って投げる必要があります。このあたりを自動でやってくれるプロキシがあると良さそう。
curl http://example.com -XGET http://localhost:9000/2015-03-31/functions/function/invocations '{body: "{\"hello\": \"world\"}"}' |
samコマンドを使えば、このAPI Gatewayが生成するJSONをローカルで作ってくれるのでテストに使えます。
sam local generate-event apigateway aws-proxy --path hoo/ --body hooo |
検索エンジンをLambdaコンテナにする

ちょっと実践的なサンプルを作ってみました。以前作ったサーバーレス用の検索エンジンwatertowerを改造して、ローカルのインデックスファイルの読み書きに対応しました。今回使ったサンプルは66kB程度の小さいデータファイルですが、心の中でこれが1万倍の大きさだったと想定してお読みいただければと思います。
https://github.com/future-architect/watertower
サーバーレス用ということで、GoCloud.devのdocstoreをストレージに使い、DynamoDBなどのサーバーレス用途で便利なバックエンドを利用する実装にしていました。このdocstoreのバックエンドのうち、memdocstoreはオプションを設定するとローカルファイルに読み書きします。しかし、終了時に強制書き出ししてしまうので、将来的にNFSで共有するときに不便になる気がして、別に実装しました。思ったより大掛かりになってしまったので、今にして思えばdocstoreのローカルファイル拡張として実装した方がよかったように思いました。また、時間があればFlatbuffersにしたかったですね。巨大インデックスでもパースする箇所を最小にできれば起動時間は短くなりますからね。ここは本題ではないのでまあ軽く。
まあ、ローカルに持ったインデックスでの検索ならtantivy使うのも良いと思います。Rust製で高速らしいです。日中韓のトークナイザも付属。
今回は静的なインデックスを作るCLIツールも用意しました。ソースは特定のスキーマで書かれたJSONファイル群です。それがフォルダにまとめて格納されているという想定でそのフォルダをスキャンしてインデックスを作っていきます。ちょうど、サンプルコードの中にHTTPのステータスコードの解説ドキュメントがいたのでこれをインデックス化して利用します。
https://github.com/future-architect/watertower/tree/master/samples/httpstatus/documents
Dockerfileの中では、検索用のプログラムのビルドと、インデックス作成用のCLIツールをビルドし、後者の方ではインデックスファイルの作成まで行っています。最後のデプロイ用のイメージは検索プログラムとインデックスファイルを同一のフォルダに置いて完成です。
FROM golang:1.16-buster as builder |
検索用プログラムは前述のサンプルを膨らませたぐらいで、冗長なので省略します。以下のところでコードは見られます。
https://github.com/future-architect/watertower/tree/master/cmd/watertower-aws-lambda
ローカルでビルド&実行し(前述のコマンドと一緒です)、試してみます。bodyというキーにリクエストを入れないといけないところは要注意。
$ curl -XGET http://localhost:9000/2015-03-31/functions/function/invocations -d '{"body": "{\"query\": \"body\"}"}' |
AWSで動作させてみる
まずはECRのリポジトリを作ります。lambda-testというリポジトリを作りました。右上に「プッシュコマンドを表示」という便利機能があります。イメージのアップロードはこのコマンドをそのままコピー&ペーストして実行すればおしまいです。簡単ですね。aws configureで認証だけはしておく必要があります。
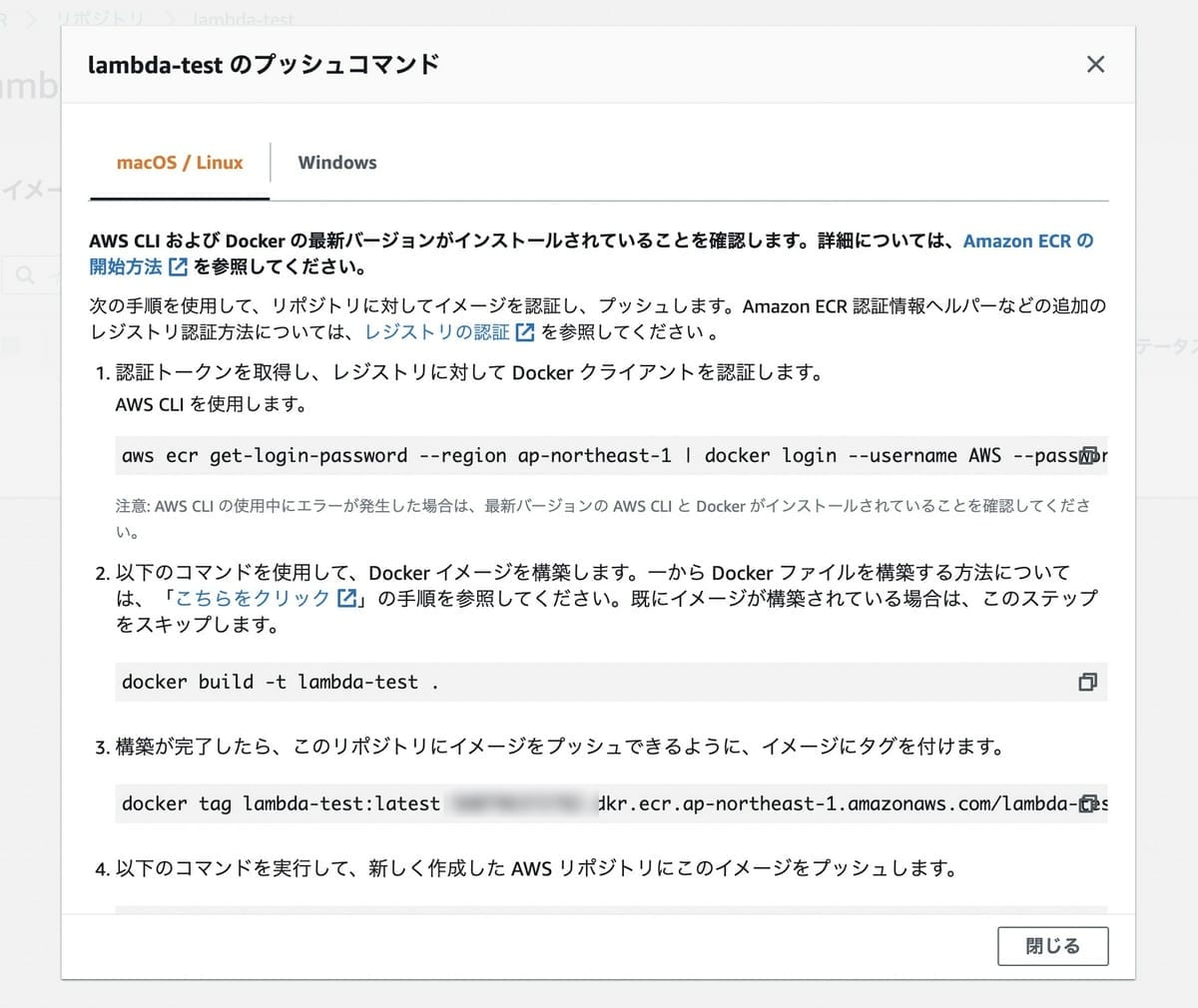
次にLambdaを作成します。最初の作成オプションで「コンテナイメージ」を選択し、その後、コンテナイメージURIでは先ほどアップロードしたイメージを選択します。現在は別のアカウントのイメージの選択はできないそうです。ステージングと本番でアカウントを分けている場合には両方にイメージをアップロードする必要があるとのことです。
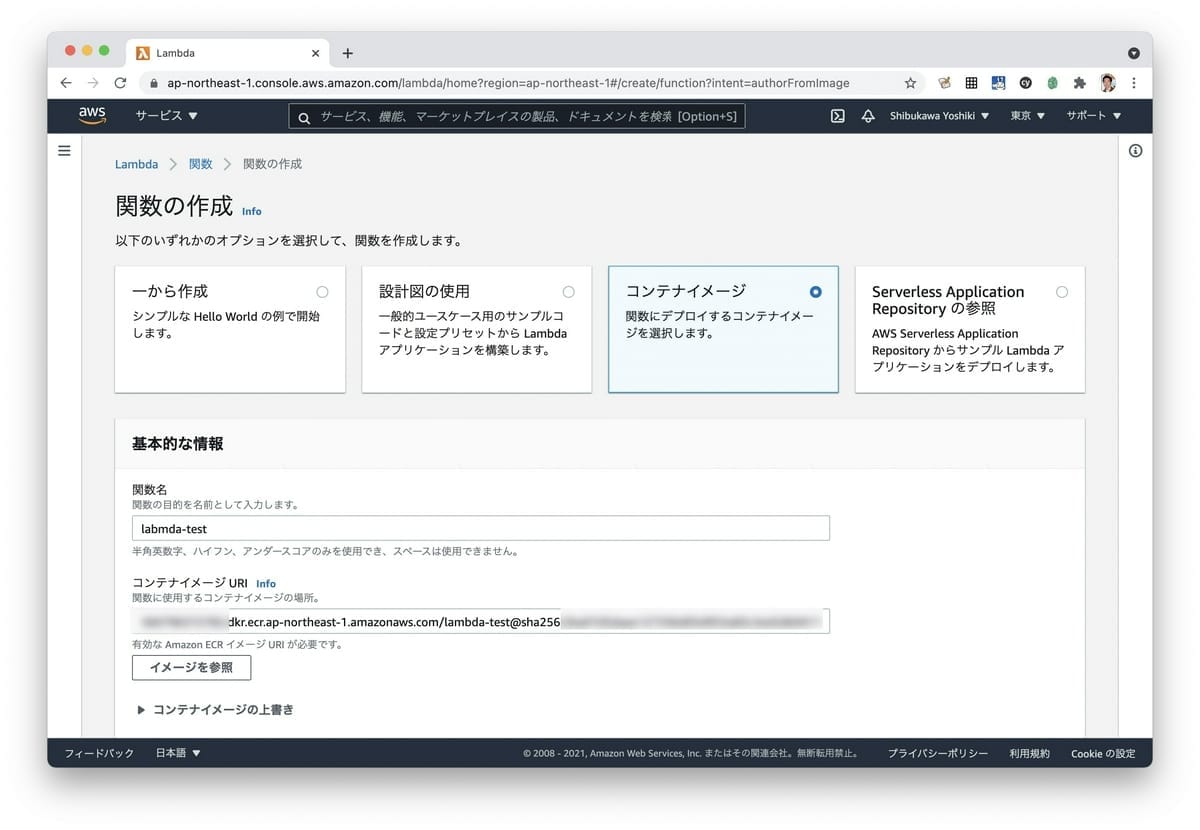
次にトリガーとしてAPI Gatewayを追加します。
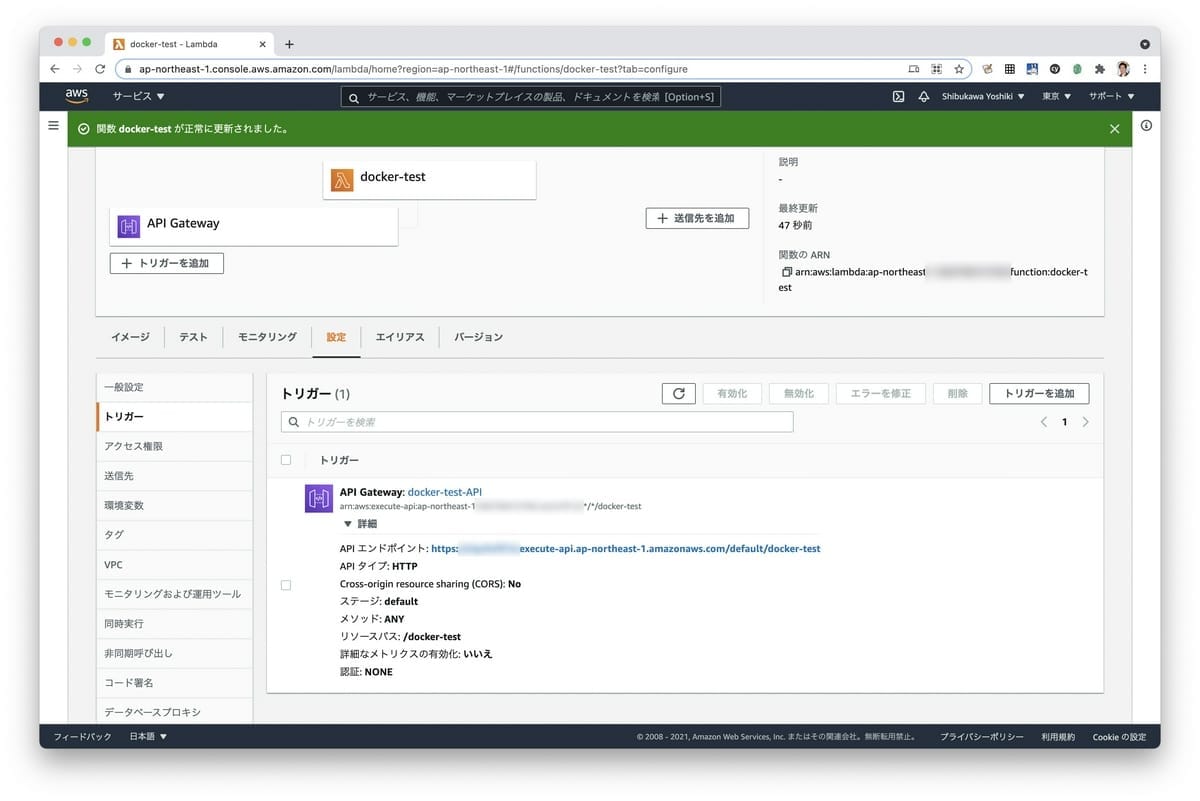
API GatewayのところにURLが書かれているので、ここにアクセスします。本番環境用にクエリーパラメータを受け取って検索キーとして使う様に実装したので、クエリーを付与します。無事一件ドキュメントがマッチして帰ってきました。
$ curl -XGET "https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/default/docker-test?query=body" |
App Runnerはどうか?
Cloud RunのAWS版という感じをひしひしと感じるのがApp Runnerです。Google I/O直前という発表タイミングも含めて、王者にのみ許されるミート戦略(ランチェスター戦略)そのものですね。PORT環境変数を渡すからこのポートを開いてね、というところまでそっくりです。ただし、まだ公開された直後で、実行時間制限やSLAなどは情報が掲載されていません。
Lambdaコンテナを今回作ってみて、やはりハンドラを専用に作らなければならないとか、ローカルと本番のAWSで動作が違うのでその吸収とか、やたら面倒でした。App Runnerがそれを解決して、ローカルでもクラウドでも同じように動いてくれるのが実現されたら良いな、と思います。
今後どうなっていくかはまだわかりませんがロードマップがありますので、欲しい機能とかはぼちぼち書いてみると良いようです。「Lambdaとか名乗っているのにcommon-Lispとかのサポート薄いのが許せない」というのも、中の人的には「要望があれば・・・」という噂を聞きました。どしどし要望を上げると良いかと思います。
https://github.com/aws/apprunner-roadmap/issues
まとめ
サーバーレスで巨大ファイルを扱う方法について考察しました。実際にストレージを検討するときは、データの容量だけではなく、読み込みのスループットの速度、スループット向上のための追加課金、ストレージの場所(リージョンやゾーンごとにファイルを用意する/リージョン間転送料金発生の有無)など、さまざまな要件を検討しなければなりません。また、アプリケーションによってはモデルの更新がリアルタイムに頻繁に行われるかどうか、というのもあります。
今回のケースは、インデックス更新の頻度が少なく、容量が比較的小さいテキストの学習モデル(というか検索インデックス)という条件においては最適だとは思いますが、インデックスを動的に追加していくような場合は向きません。アプリケーションの特性によって最適解は変わってきます。アーキテクトとしての腕の見せ所でしょう。
NFS利用のケースは、もっともっと簡単になって欲しいですね。Dockerのボリュームマウントぐらいの気軽さで、読み込み専用と読み書き両用が気軽に選べて・・・となったら素敵だなと思います。
なお、ローカルのテストがしにくい点は要注意です。最初はswaggerを用意してあった実装済みのサーバー版を動かせばいいや、と思っていたのですが、実際にテストしたら動かず、最終的にLambdaコンテナ用に別にアプリケーションを作りました。クエリーとかボディはなんとかなりそうですが、パスを変更できないのはかなり厳しい。このブログの記事、さっさと仕上げようと思ったのですが、検索エンジン自体の改造に1週間、Lambdaのローカルとの互換性の調査だけで3日ぐらい溶けた気がします。
コンテナ化に対応したことで、利用できるファイルサイズが250MBから10GBと、Lambdaができることは増えました。ですが、今後、App Runnerの改善や、コンテナのファイルシステムサポートが充実したらさらにいいな、というのが感想ですね。