はじめに
TIG真野です。失敗談をテーマにした連載で、ちょうどプロダクト開発的に良い区切りのタイミングでもあるため、振り返りがてら、DynamoDB,Go,AWS Lambdaの技術要素について自分自身の理解・見込みの甘さについて反省します。
DynamoDBのシステム項目created_atとかupdated_atのタイムゾーンはJSTにすれば良かった
DynamoDBは日付型を直接サポートしておらず、文字列型で保存することになります。
データサイズや諸々の理由でUnixTime 勢力もあるかもしれませんが、アプリケーションから直接参照されず、トレースその他を運用時の利用を目的にしたシステム項目は、可読性が大事なのでRFC 3339ナノ秒で保管していました。RFC 3339ナノ秒は 2022-06-01T03:31:14.6300415Z と言った形式です。
ここまでは良かったのですがタイムゾーンはUTCに統一する方針を取っていたので、JSTではないです。変換するときは常に+9時間することになり激しく反省をしています。少なくてもクライアントのタイムゾーンがJSTであれば、JSTで保存したほうが良かったと考えています。JSTですと次のような形式を想定しています。
2022-06-01T12:31:14.6300415+09:00
ちなみに、AWS SDK for Goを用いると、time.Time型はデフォルトではRFC 3339で保存されます。
time.Timeis marshaled as RFC3339 format.
https://docs.aws.amazon.com/sdk-for-go/api/service/dynamodb/dynamodbattribute/#:~:text=%60time.Time%60%20is%20marshaled%20as%20RFC3339%20format.
ちなみに、システム項目に限っていますが、時系列データのソートキーなどもJSTタイムゾーンで保存するほうが日本ユーザーが大半のケースにおいてはベターだと思います。
時系列DBをDynamoDBに貯めるのは良かったけど、分析用のデータストアを最初から分けるべきだった
今回のユースケースとしては、温湿度や移動情報(緯度経度)をそれなりの量と頻度(つまり時系列)で受信するようなタイプです。基本的には全データを利用するというよりは、ときより発生する異常値をトリガーに通知をしたり、ある断面のセンサー値を別システムに連携します。発生するデータ量の将来換算が読みきれずDynamoDBをメインのデータストアに採用したのは良かったのですが、データが蓄積するとちょっとした調査・集計をかなり頻繁に行いたくなりました。
最初はちょっとした集計ですし、簡易なスクリプトを開発していましたが、気づけばチーム全員がちょっとしたスクリプトを開発するのがうまくなっていました。これはこれで悪くないスキルセットかもしれませんが、すこし方向性が異なります。
S3 Export + Athenaで集計しようという方法も部分的に行いましたが、やはり特定の業務キー+年月日でパーティショングしたいということもあり、これについては早期にデータ基盤を整えるべきであったと反省しています。
例えば次のように、DynamoDB Streamsトリガーでデータレイク側に参照したい形式で転送するといったことを早期に行っていれば..という反省があります。
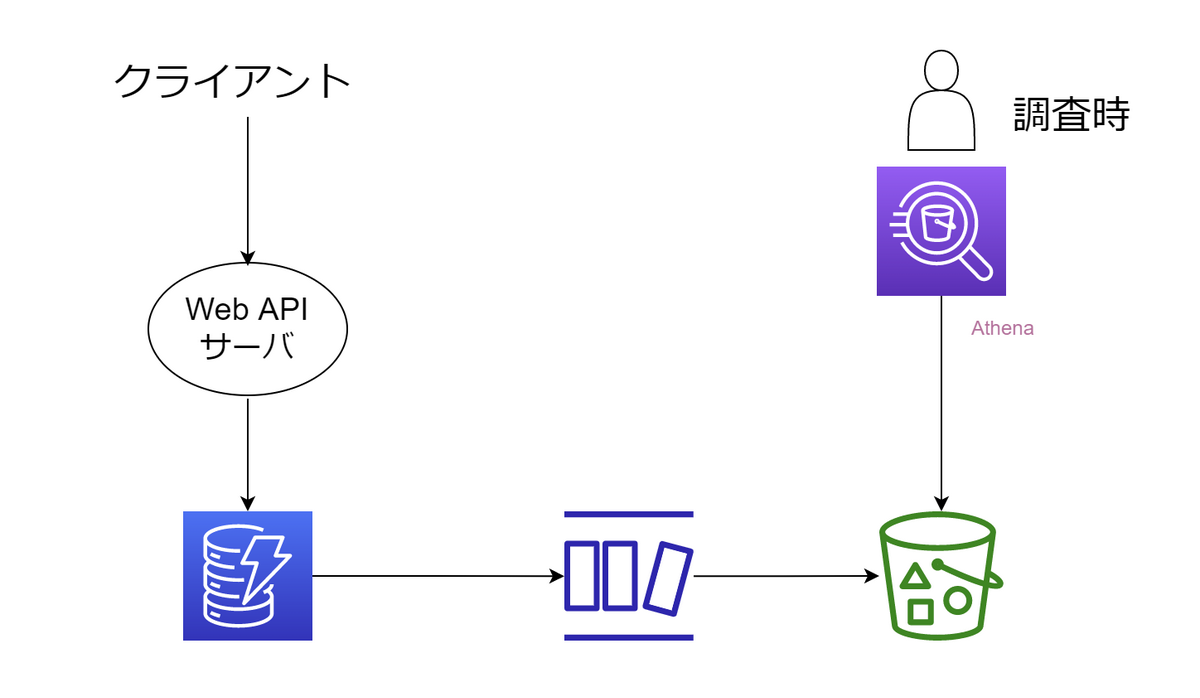
上図はS3に転送していますが、どういったデータストアで投げても良いとは思います。この例では月額コストをなるべく抑えたく、そこまで集計に用いるクエリにレイテンシを求められなかったため、S3+Athenaで済ましています。
参照Viewを構築するためのDynamoDB Streamsの処理はWeb API側の同期処理に寄せて良かったのでは
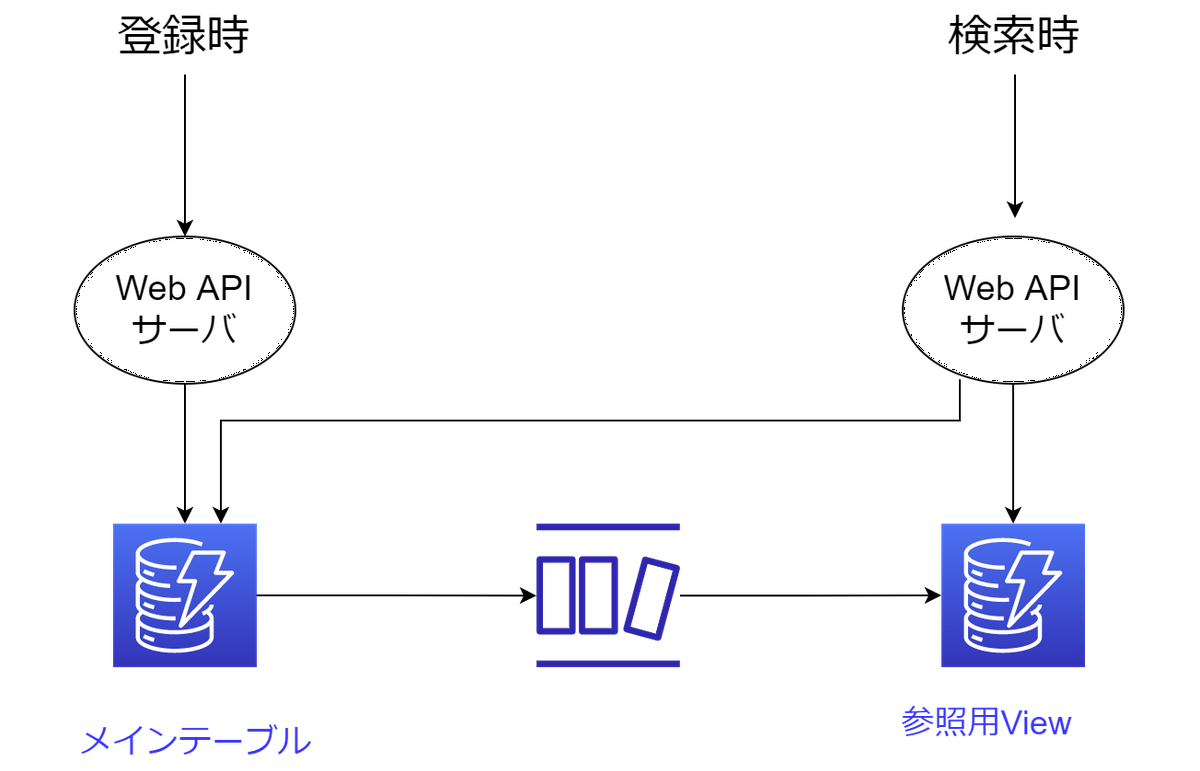
逆に、DynamoDB Streamsを使わないほうが良かったという話です。どうしてもアプリケーション管理画面からの参照要件が耐えられず、メインのテーブルの更新トリガーでLambdaを着火させ、参照のビューテーブルを作成する処理を追加しました。管理画面を作る処理は後々の追加要件であったため、すでに稼働済みのシステムに手をいれることを避け、疎結合に追加したという動きです。
アプリ上は疎結合となりましたが、アプリケーションの構成要素を増やすと後々面倒だなという思いが募ってきました。インフラの監視、運用、リリース。非機能的な性能、障害テストなども手間です。もちろん許容範囲内なので、この件に関してはメインテーブルに書き込みを担当するWeb APIのロジックに追加して良かったのかなと考えています。
元の構成
こうすればよかった
元も思想的には悪くない(DynamoDB Streams部分だけの改修で済むケースもあり影響範囲が限定的だった)ですが、終わってみればやや重厚だった気がします(ローカルの環境で再現するのが面倒で、単体テスト品質が上がりにくいにもあり)。
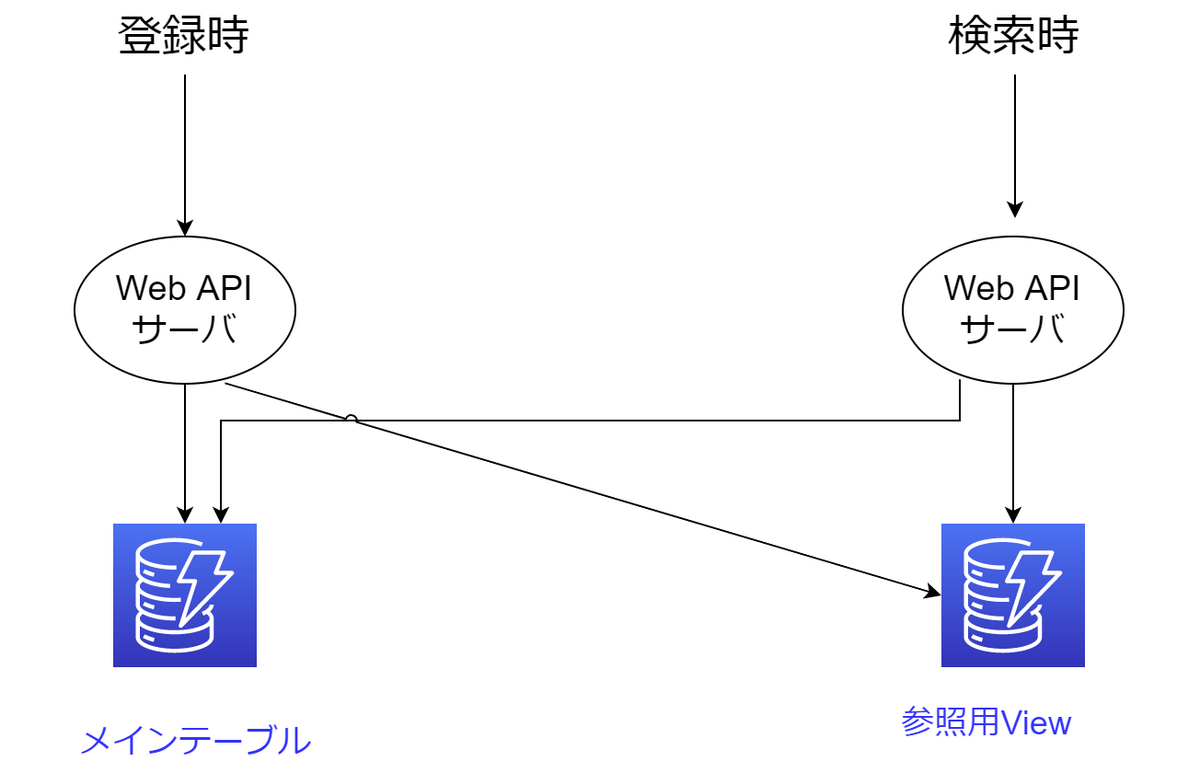
上図のように、同期的に書き込む方式も、既存部分へ手を入れることを過度に恐れず、客観的に判断していこうと思います。
DynamoDBアクセスにAWS SDK for Goを生で使う必要はなかったのでは
GoからDynamoDBアクセスをするためのパッケージは大体3つあるかなと思います。DynamoDB×Go連載を行ったことすらありました。
- AWS SDK for Go
- v1, v2がある
- guregu/dynamo
- Go CDK
AWS SDK for Goですが、記載がやや冗長になりがちでした。条件式もヘルパーパッケージがあるよという記事を書きましたが、やっぱり冗長です。公式提供だけに使えない機能は存在しない安心感はありましたが、guregu/dynamo が優秀すぎるので逆に生でわざわざ使う理由はないかなという印象です。
ちなみに、Go CDKはDynamoDBアクセスもけっこういけるんじゃないか?で1本記事を書きましたが、結局導入に至っていないです。別の機会があればこれはこれでチャレンジしたいと考えています。
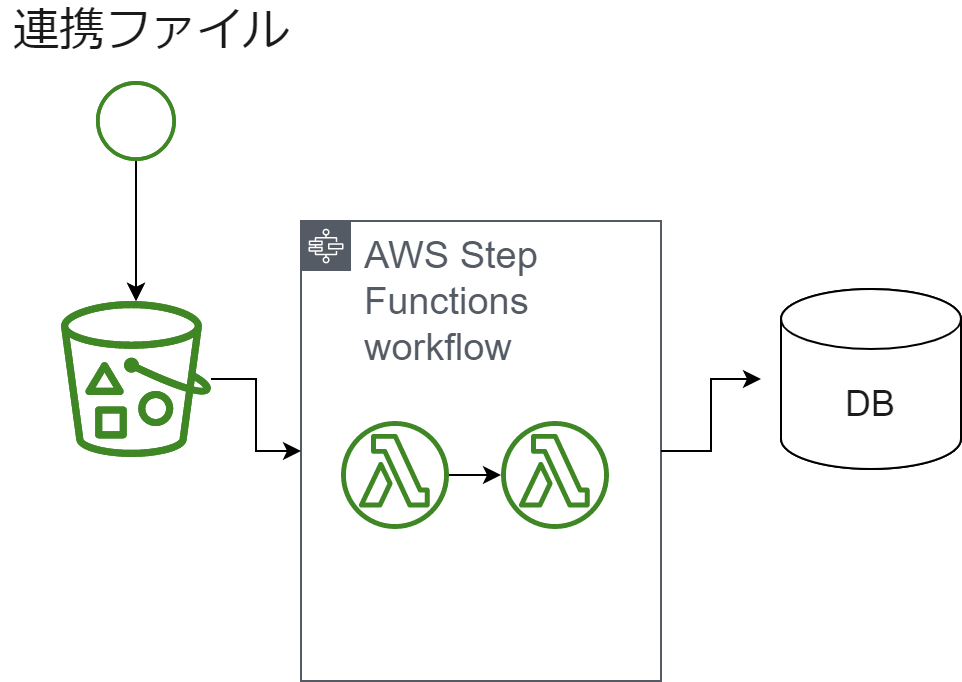
AWS Lambdaのバッチ処理はStep Functionsで必ずラップするルールにすれば良かった
データ量が少ないため、ちょっとしたシステムI/Fでの受信/送信処理は生のLambdaで軽く書いていました。ご存知の通り最大実行時間は2022.6.1時点で15分です。今回の要件では問題なかったのですが、隣のチームに構成を移植された場合にはデータ量が多くなるケースがありタイムアウトが発生。いっそすべてStep Functionsでラップして統一するルールにしても良かったのかなと今では少し思っています。もちろん、ここだけECSやApp Runnerにする形式も面白いと思います。
少し反省している構成
初期移行、リラン、連携先の不具合などで予期せぬデータ量に達した場合は、タイムアウトになりがち。
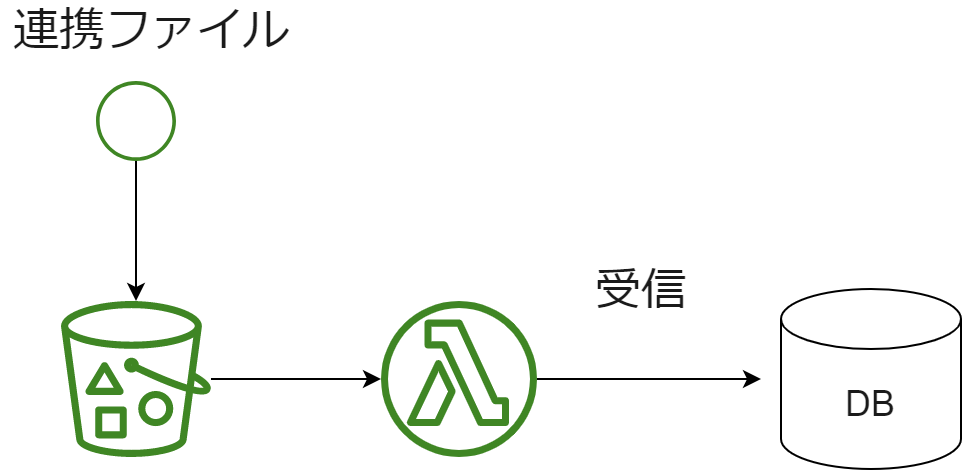
横展開するのであれば最初から固く作っておいても良かったと思っている構成
連携先の品質その他の制御が取りにくい場合は、自衛的に固く作り込んでおくことが吉。
その他
- go-swaggerも好きですが、 deepmap/oapi-codegen にしておけば良かった
- 別にOpenAPI Specification v2(Swagger)で困ることもなく、v3を使いたいことはなかったのですが…
- go-swaggerで –strict-additional-properties をつけていることを忘れて、項目追加が許容できないため互換性を失い、リリースのときに困った
- 開発時にtypoで誤った項目をcurlなどで呼ばれるよりはつけておいた方が間違いないだろうと考えたが、いつしかクライアントが増え、サーバ・クライアントのリリースサイクルがずれたときに困りました
- スキーマ駆動で自動生成したStructを、アプリ本体で用いるモデルのStructに埋め込めば良かった
- 必ずしもWeb API時の項目とDBカラムが1:1ではないので、埋め込む方向に舵を切るとそれはそれで何か不満が出そうですが、項目詰め替え作業もcopier を導入するのも何だかなと思っていた
- DynamoDBのGSIを用いて重複チェックをアプリ側で実装していましたが、反映まで時間がかかるため同時実行数の制御が必要などモヤるポイントがあった
さいごに
列挙すると事前に回避ないしは途中で方向転換できそうな内容が多く、アーキテクチャ的な意思決定を微修正したり、マネジメントレベルの調整ができてなかったんだなと感じました。
また、こういった振り返りの記事がもっと増えると良いなと思います。
失敗談連載の次は穴井さんのint32 型のサロゲートキーが数年でオーバーフローしそうになった件です。