はじめに
システムにおける「区分」とはカテゴライズ可能な値の集合体を表すものであり、「区分値」とはその集合に属する個々の識別子を指します。
たとえば、あるアイテムの「ステータス」という区分には「下書き」「レビュー中」「承認済み」といった区分値が含まれます。
一見すると、こうした区分値は単なるラベルでしかなく、設計の検討余地があまりないように思えるかもしれません。しかし実際には、区分値の扱い方次第で、システムの柔軟性・拡張性・保守性などに大きな差が生まれます。
本記事では、この「区分値」の設計について、あらためて整理し、より優れたアプローチを再考していきます。
本記事の前提
区分値の設計について語る前に、設計の前提となるシステムについて整理しておきます。
本記事では、フロントエンドとバックエンドが分離され、Web API を通じてやりとりする Web アプリケーション(いわゆるモダン Web アプリケーションと言われるもの)を前提とします。さらにフロントエンドとバックエンドの双方が自組織の管理下にあるような状況を想定しています。
このようなシステムにおいて、区分はいろいろなところで登場します。
冒頭で例に挙げた「ステータス」という区分を持つ場合、データベースにはアイテムの属性としてステータスを保持するでしょう。エンドユーザは画面からセレクトボックスなどで検索対象のステータスを選択し、そのステータスは検索条件として Web API のリクエストパラメータで渡されます。Web API サーバはそのステータスを元にデータベースから対象のアイテムだけを選択し結果を返却する、と言った具合です。
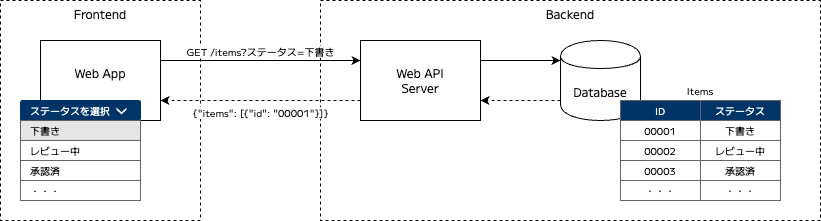
設計上の論点
前置きが長くなりましたが、ここからは区分値の設計について、具体的な論点をもとに説明していきます。
区分値の表現(Symbolic Value vs Semantic Value)
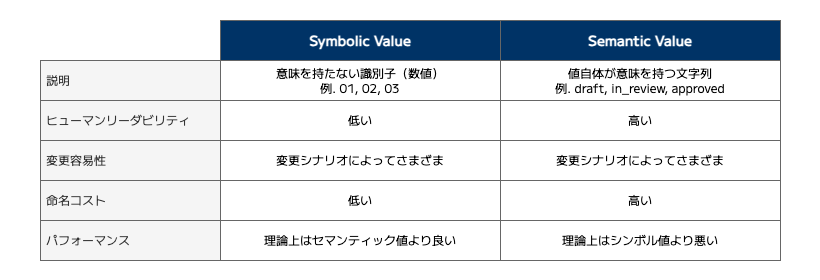
まず最初に、区分値を記号としての数値(Symbolic Value:シンボル値)として表現するか、意味のある文字列(Semantic Value:セマンティック値)として表現するかという設計判断が存在します。たとえば「ステータス」区分を取り上げると、シンボル値では「01(下書き)」「02(レビュー中)」「03(承認済み)」となり、セマンティック値では「draft」「in_review」「approved」となります。
シンボル値による表現は、伝統的な業務システムにおいて長年にわたって広く使われてきた手法ですが、結論から言うと昨今のモダンな開発現場においては 「セマンティック値」での表現を第一に検討することが望ましい と考えます。
2 つの表現の比較
いくつかの観点でこの 2 つの表現を比較してみましょう。
ヒューマンリーダビリティ
セマンティック値はその文字列自体が意味を持つため、値を見ただけで直感的に理解しやすいです。シンボル値はその数字を見ただけでは意味が分かりにくく、別途コード表(区分値とその意味の対応表)を参照するなどして意味を確認する必要があります。
セマンティック値は Web API の利用者や運用保守者にとっても多くの利点があります。たとえば Web API においては、リクエストやレスポンスで意味のある値を直接やりとりできるため、利用者は実装やドキュメントを確認せずとも内容を把握しやすくなります。さらに、ログやデータベース上でも区分値の意味がそのまま伝わるため、運用時の調査や障害対応においても確認がスムーズです。
変更容易性
区分値の追加や削除のしやすさを指します。たとえば、先ほどのステータス区分に「レビュー待ち」を追加したくなったケースを考えます。セマンティック値で表現している場合は「ready_for_review」を新たな区分値として追加するだけで済みます。
では、シンボル値の場合はどうでしょうか。単純に 04 を追加すると「01(下書き)」「02(レビュー中)」「03(承認済み)」「04(レビュー待ち)」となり、この順序に違和感を覚える人がいるかもしれません。おそらく多くの人は、「01(下書き)」「02(レビュー待ち)」「03(レビュー中)」「04(承認済み)」のように、ステータスの遷移の順序に沿った並びを期待するでしょう。
このように本来は意味を持たないはずのシンボル値が、暗黙的に「順番」という意味をもってしまうというジレンマが生じます。これに対応しようとすると、シンボル値の先頭桁に意味を持たせてグルーピングする設計(例. 00 ~ 09 は草稿・編集系、10 ~ 19 はレビュー系、20 ~ 29 は承認・公開系など)が検討されることもあります。一見すると拡張性があるように見えますが、この設計は結局のところシンボル値に意味を持たせているにすぎません。セマンティック値に比べて直感的ではなく、むしろわかりづらい意味付けをシンボル値の桁構成に押し込めているだけとも言えるでしょう。
一方で、シンボル値にも一定のメリットがあります。たとえば、当初は「01(下書き)」「02(レビュー中)」「03(承認済み)」という区分だったとしても、あとからより適切な概念(例:01(記事構成案)、02(デスクチェック)、03(掲載許可)など)がプロジェクトの進行に伴って「発見」されるケースがあります。こうした場合、シンボル値であれば論理名(ラベル)だけを変更すれば済み、システム的な影響範囲は小さく抑えられます。
セマンティック値では draft を article_composition_proposal に変更したいとなった場合、物理名の変更が発生し、コード修正や連携先への影響も大きくなる恐れがあります。
命名コスト
命名コストとは、適切な区分値の名前を決めるための時間・労力・議論のコストを指します。
セマンティック値の場合、命名は慎重に行わなければなりません。例として挙げたステータスのようなわかりやすい区分であれば大したコストはかかりませんが、日本のエンタープライズなシステムや業務専門性の高いシステムには、わかりやすい名前を付けることがそもそも難しい区分値(例. 英語での表現が難しい 1 専門用語や概念など)が一定存在します。
このような場合、適切な命名を検討し、チーム内で合意形成をするコストは非常に大きくなる可能性があります。
ただし、シンボル値の場合でも、内部のプログラムとしてはその値に対応する列挙体なり定数なりを定義するはずですので、何かしら命名するという行為とそこにかかるコストは変わらないのかもしれません。
パフォーマンス
パフォーマンスについては、ストレージ・通信効率の観点とクエリ性能の観点の 2 つがあります。
ストレージ・通信効率の観点では、シンボル値(通常 2~3 桁の数字)はセマンティック値と比べてデータ量が小さいため、ストレージや通信の負荷が低くなります。クエリ性能の観点ではリレーショナルデータベースのインデックスを利用したクエリにおいて、固定長数値のシンボル値の方が可変長文字列のセマンティック値よりも高速に動作することが期待できます。
ただし、この性能差を意識しなければならないほどの性能要件があるシステムはほとんどないでしょう。一昔前のシステムではストレージやメモリが限られていたためデータ量を減らすことが最優先でしたが、クラウド環境や現代のハードウェア性能の向上により、この制約を意識することはほぼなくなりました。また文字列検索の最適化をはじめ、データベースの進化によりセマンティックを採用しても、現実的なデータ量であればクエリ性能に大きな影響を与えないケースが大半です。
結論として、パフォーマンスの差は理論上存在するものの、ほとんどのシステムでは影響が軽微であり、シンボル値とセマンティック値の良し悪しを判断する上で重要な要素にはなりません。
結論どうすべきか
先に記載した通り、Web API を通じたデータのやりとりが主流となっている現代の Web アプリケーションシステムにおいては 「セマンティック値」による区分値の表現を第一に検討すべき だと考えます。
セマンティック値は、開発者、運用保守者の双方に直感的で扱いやすく、可読性・拡張性といった点でシンボル値よりも優れています。
もちろん、命名コストやパフォーマンスといった観点でシンボル値に一定の利点があるのも事実ですが、それらは実際の開発・運用において致命的な差となることはほとんどありません。むしろ、意味を隠蔽したシンボル値を維持することのデメリットの方が、長期的な保守性やチーム内の共通理解の観点から大きな負債となる可能性があります。
もしくは、より可読性の求められる外部向けの表現(Web API のリクエスト・レスポンス)はセマンティック値を利用し、内部向けの表現(データベース)はシンボル値を利用するというハイブリッド設計も考えられるかもしれません。ただし、セマンティック値とシンボル値の管理コストやマッピング(変換)コストを考慮すると、あえて使い分けるメリットはないと考えます。
ただし私も作成に関わった PostgreSQL 設計ガイドライン では、DB としてシンボル値での表現を推奨する形にしており、このあたりはまだまだ議論がありそうです。
シンボル値を使うべきケース
セマンティックな値を定義することによるメリットが極端に少ない、もしくはデメリットが極端に大きいケースが一定存在するのも事実であり、そのような場合はシンボル値を検討すべきです。具体的には次のようなケースが考えられます。
- ビジネスドメインが日本ローカルに特化(例. 官公庁系システムなど)しており、業界特有の専門用語が日本語ベースでしか存在しない(英語で表現しづらい、表現することで返って可読性が低下する恐れのある)場合
- その現場や周辺のシステムにおいて、シンボル値での区分表現が慣例となっており、セマンティック値を用いることで返って混乱を招く恐れがある場合
- 依存するシステムがシンボル値を利用しており、その値を内部のセマンティック値に変換するコストが大きいなど、シンボル値とセマンティック値の混在が避けられない場合
また、少々悩ましいのが ISO 5218 で定められている性別区分など、国際規格としてシンボル値が定められているケースです。シンボル値の利用がデファクトであると考えられるケースにおいてはシンボル値を利用するという判断が考えられます。
どちらの表現を利用するにせよ、これまでの慣習的な設計にとらわれず(言い換えれば思考停止で設計せず)自分たちのシステムにとってより望ましい表現を再検討することは大きな意味を持つと考えます。
いずれにしてもこのような区分を含むデータを、データ基盤などに集約してAIに分析させる、といった未来を予想すると、各システムごとに最適化するよりは、全社的なデータモデルをどうするかが重要であり、シンボル値とセマンティック値のどちらを採用するにせよ組織内で統一することが重要なのかもしれません。
区分値の管理
区分値自体は Enum なり定数なりで定義する形になりますが、この区分値をクライアント側とサーバ側のどちらで管理するかという設計判断が存在します。
この話はあまりピンとこない方が多いかもしれません。区分値は一覧表示やロジック(例. 条件分岐)などさまざまな用途で使われ、その用途によって考え方が変わるため、一概にどちらとは言えないのですが順を追って説明していきます。
まずは一番単純な例として、ユーザが Web 画面上からセレクトボックスでステータス区分を選択し、その選択した値を Web API のリクエストパラメータとして送信するケースを考えてみましょう。このとき、純粋な区分値の一覧だけではなく、区分値に付随する情報として区分値の表示名や表示順の定義が必要となります。これらの情報の管理には大きく 2 つのアプローチが考えられます。
- クライアント側で管理
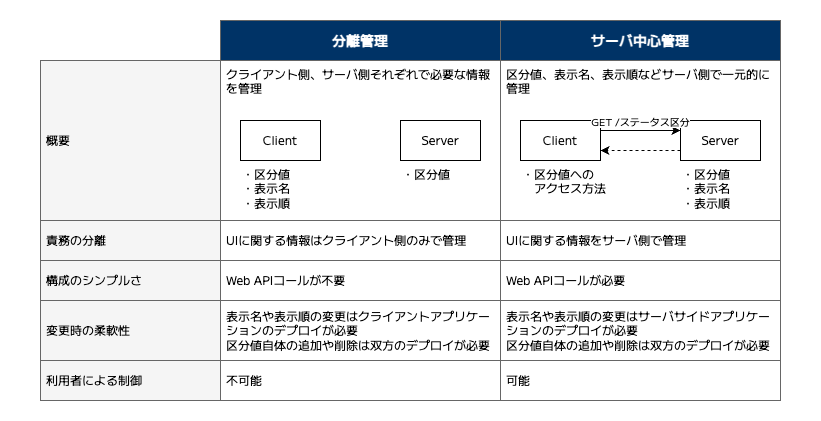
区分値、表示名、表示順の情報をクライアント側に持たせる方式です。
この方式では、クライアント内に定義された情報をもとに、Web API を呼び出すことなく区分の一覧を取得し、セレクトボックスなどの UI を描画できます。 - サーバ側で管理
区分値、表示名、表示順の情報をサーバ側に持たせる方式です。
この方式では、クライアントは初回表示時などに Web API をコールして区分値の一覧を取得し、それをもとにセレクトボックスなどの UI を描画します。
結論だけ先に言うと、区分値はどちらか一方のみで管理できる代物ではないため、責務を意識してそれぞれで分離管理することが望ましいと考えます。
2つの方式の比較
いくつかの観点でこの 2 つの方式を比較してみましょう。

責務の分離
区分値の表示名や表示順といった情報は基本的に UI のみに影響する情報であり、責務の分離という観点ではクライアント側で管理することが望ましいと考えます。
複数のクライアントアプリケーション(Web アプリケーション、モバイルアプリケーションなど)が存在する場合、クライアントごとに表示名や文言表現を変えたいというニーズが発生することもあります。このようなケースでは、サーバ側で一元的に表示名を管理してしまうとクライアントごとの個別表現が難しくなるため、クライアント側で表示情報を持つことでより柔軟な UI 制御が可能になります。
構成のシンプルさ
クライアント側で区分値を管理する場合、画面描画のために区分値取得の Web API を呼び出す必要がありません。非同期処理や取得失敗時の考慮が不要になるため、実装がシンプルになり、画面の描画も高速です。
一方、サーバ側で区分値を管理する場合は、初回表示時に Web API の呼び出しが必要となり、ローディング制御やフォールバック処理など複雑さが大きくなります。待機時間によっては UX が低下する恐れもあるため、キャッシュの活用やプリフェッチの導入、スケルトン UI の表示など、UX への配慮が求められます。
変更時の柔軟性
区分値の追加・削除・変更において、クライアントサイド管理の場合はクライアントアプリケーション、サーバサイド管理の場合サーバアプリケーションのデプロイが必要になります。
この 2 つは大きな差がないように思えるかもしれませんが、次のようなケースにおいてはサーバ側で管理することによる効果が大きくなります。
- 異なるクライアントアプリケーションが複数あり、サーバ側で区分値を中央集権的にコントロールすることで運用・保守コストが小さくなる場合
- クライアントアプリケーションが Web アプリケーションではなくモバイルアプリケーションなどデプロイにかかるコスト(審査コストなど)が大きい場合
利用者による制御
クライアント側で管理している場合、表示内容の調整には開発者によるコードの修正が必要になります。
アプリケーションの管理権限を持った利用者などが、区分値の表示名や表示順を直接コントロールしたい場合は、区分値をサーバ側(データベース)で管理し、管理画面などから編集できるようにしておくのが適しています。
実際は双方での管理が必要
ここまではクライアントサイド管理とサーバサイド管理の違いをわかりやすく伝えるため、区分値の一覧表示というシンプルなケースを取り上げて説明しましたが、実際のところ話はもう少し複雑です。なぜなら区分値は一覧表示だけではなく、ロジックとしての制御にも使用されるからです。
たとえば、クライアント側で区分値を管理した場合でも、その区分値が Web API のリクエストパラメータでサーバに投げられたとき、サーバ側はその区分値が受け入れ可能な値かどうかをチェックするでしょう。場合によっては、区分値の値に応じて条件分岐などが必要になるかもしれません。
このような場合は、サーバ側はロジックを制御するために区分値の列挙体や定数を定義することになります。
// 区分値の定義(列挙体や定数)が必要 |
その逆も然り、サーバ側で区分値を管理した場合でも、クライアント側において画面で選択された区分値の値に応じて条件分岐をする場合などは、クライアント側で区分値に対するアクセッサの定義(サーバから取得した区分値一覧の中から対象の区分値を取得するためのキー定義など)が必要になります。
// サーバから取得した区分値の一覧から特定の区分値を取得するための定義が必要 |
このように、実際のところはどちらか一方で区分値を管理すれば十分、という単純な話ではなく、クライアントとサーバの双方において何らかの形で区分値にアクセス・解釈するケースがほとんどです。そのため、区分値の定義方式はクライアント側とサーバ側のそれぞれで管理する 「分離管理型」 とサーバ側で極力一元的に管理する 「サーバ中心管理型」 の 2 つに分類して考えることができます。
冒頭述べたとおり、基本的には責務を意識して必要な情報をそれぞれ管理することが重要であり、クライアントサイドは区分値の一覧および表示名や表示順を管理、サーバサイドはロジック制御のため区分値の一覧を管理する分離管理方式が望ましいと考えます。
サーバサイドで「一元的にコントロールしたいケース」や「管理権限をもった利用者がコントロールしたいケース」においてのみ、区分値取得の Web API 化するサーバ主体の管理方式を検討すべきです。
ちなみに筆者の観測範囲に限った話ですが、従来のサーバサイドレンダリング / MPA 時代の設計になごりのある組織においては、暗黙的にサーバ中心管理となるケースが多いと感じています。
これは、かつてはサーバ側が UI 表示も含めてすべてを制御していたという背景があることに起因していそうです。SPA への移行後も、既存のロジックやデータ構造を維持する流れで、サーバ側で区分値を一元管理する設計思想が引き継がれているのではないかと考えます。
区分値の定義場所
サーバ側で区分値を定義する場合、ソースコードの列挙体や定数などで区分値を定義するか、データベースのマスタ(例. 区分値マスタ)で区分値を定義するかという設計判断が存在します。
結論から言うとこれは ソースコードで定義する方式 が望ましいと考えます。従来 PL/SQL などでデータベース内にビジネスロジックが実装されていた時代は、区分値をデータベースで保持する形が合理的でしたが、現代のモダンなシステムにおいて、もはやその意味はなくなりました。IDE や型システムによる保管や検出、テスト容易性やデプロイ容易性などさまざまな観点からソースコードで定義するメリットが大きいと考えられます。
フラグの取り扱い
フラグとは、ある状態や条件を 2 値(true/false)で表すためのものであり、言い換えれば「2 値のみを持つ区分の一種」と言えます。
このフラグに関しては、ほかの区分値にはない設計上の論点がいくつかあります。
詳細な話をする前に、前提として、対象のフラグが本当に 2 値のみで完結するのかどうかを見極めることが重要 2 です。たとえば「有効フラグ」というものが必要になったとき、それは「有効」「無効」の 2 値を表すフラグではなく「有効」「無効」「一時停止」「廃止」など、将来的に選択肢が増える 状態 であるかもしれないと疑ってください。このようなものは初めからフラグではなく区分として取り扱うことが適切です。
フラグ値の表現
区分値の表現 ではシンボル値とセマンティック値の表現パターンが存在することを説明しましたが、フラグ値の表現は一般的に「0/1 による表現」と「真偽値(true/false)による表現」が考えられます。前者がシンボル値、後者がセマンティック値である3ととらえることもできます。
区分値の表現と同様、より意味が明確な「真偽値(true/false)による表現」を推奨します。Web API の外部表現においては真偽値の使用が標準的になっており、内部ロジックの記述性としても真偽値を用いる方がシンプルでわかりやすいと考えます。
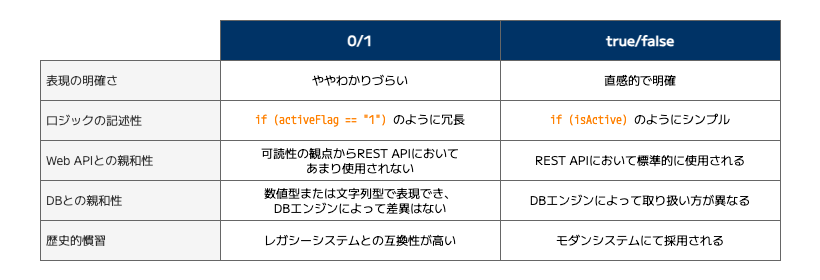
ただし、区分値の表現としてシンボル値による表現を選択した場合は、フラグ値の表現も 0/1 による表現とする方が、設計が統一されるため望ましいと考えます。
フラグ値の個別定義
2 値で表現されるフラグが複数あったときに、各フラグごとに「ON」「OFF」や「有効」「無効」といった値を列挙体や定数で個別定義するのかという論点があります。
個別定義することで、特定のフラグ値の利用箇所がソースコード上検出し易くなったり、区分と同様に各フラグ値に紐づけて表示名や表示順を管理できたりと運用・保守上の効果が期待できます。
ただし、フラグ値を真偽値(true/false)で表現する場合は、ロジックの記述が冗長になる(例. if(isActive == consts.Active) のような真偽値どうしの比較になる)可能性があり、この場合まずは個別定義せず実装をシンプルにするところを意識して始めてみるのがよいのではないかと考えます。
終わりに
本記事では、区分値という一見些細に思えるしくみについて、あらためて設計観点を掘り下げてきました。
区分値の表現方法、管理場所、定義場所、さらにはフラグ値の扱い方に至るまで、多くの選択肢が存在します。そしてそれぞれの選択には、必ずトレードオフがあり、すべての場面で正解となる万能な方式は存在しません。
大切なのは「今までそうしていたから」という慣習に従うのではなく、自分たちのシステムにおいてどのような設計がより適しているのか、今一度考え直してみるきっかけになれば幸いです。
参考
- 1.通常セマンティック値は英語で表現されることが一般的です。日本企業の伝統的なシステムにおいては英語ではなくローマ字で表現する文化もありますが、この場合はそもそもローマ字自体の可読性が高いのかどうかという議論がありそうです。 ↩
- 2.SQL アンチパターン 幻の第 26 章「とりあえず削除フラグ」 でも取り上げられています。 ↩
- 3.フラグ値においては「0=OFF, 1=ON」という暗黙の意味付けがあり、その意味では 0/1 による表現もセマンティックな表現と言えるかもしれません。 ↩