
はじめに
TIG/DXユニットの棚井龍之介です。入社以来、Go × AWS でのバックエンド開発を担当しています。
AWSのDBといえば「RDS」が代表格ですが、近年のサーバレス普及に伴い「DynamoDB」が第一選択肢として選ばれる機会が増えています。私の所属するプロジェクトでは、API Gateway, Lambda, DynamoDBのAWSサーバレス3兄弟をメイン利用しているため、メンバーによっては「研修はSQL地獄だったけど、配属後はNoSQLオンリーだ!」という人もいます。
徐々に利用機会が増えているDynamoDBですが、いくつかの「初見殺し」があります。今回はその中での「ページング」について、DynamoDBのデータ格納状況と照らし合わせながら、基本的な仕組みを見ていこうと思います。
DynamoDBの操作経験がある方を想定しているため、まだ一度も触ったことのない方や基本操作に不安のある方は、公式docsや冨山さんの書かれた入門記事をご覧ください。
前提知識
- プライマリーキー
- パーティションキーのみ
- 複合プライマリキー (パーティションキーとソートキー)
- DynamoDB API
- Scan
- Query
DynamoDBの1MB制約
テーブル操作には大きく分けて「Read(読み込み)」と「Write(書き込み)」の2タイプがあります。
このうち、ReadのScanとQueryは、一度のDynamoDB API操作では 1MBが取得上限 です。1MB以上のデータを抜き出したい場合は、ページング処理が必要です。ページング処理の対応実装はシンプルであり、1度誰かが書いたコードをコピー&ペーストで利用できるため、中身を深く理解せずとも使えてしまいます。(Goのサンプルコードは最後に掲載します)
しかし、詳細を理解しないコピー&ペースト実装だと、ちょっと手の込んだ実装などができなくなってしまうため、ページング処理を説明する前にDynamoDBのデータ格納方法を説明します。
DynamoDBのデータ格納方法
DynamoDBのテーブルにItemを格納する場合、プライマリーキーによって格納場所が決まります。
データ格納空間(Key Space)を00~FF、idをHash-Keyとした場合、各Itemは下図のように格納されます。プライマリーキーは重複できないため、新しいデータをid=1でPutItemした場合、データは上書きされます。
table
- Hash-Table
key - Hash-Key: id
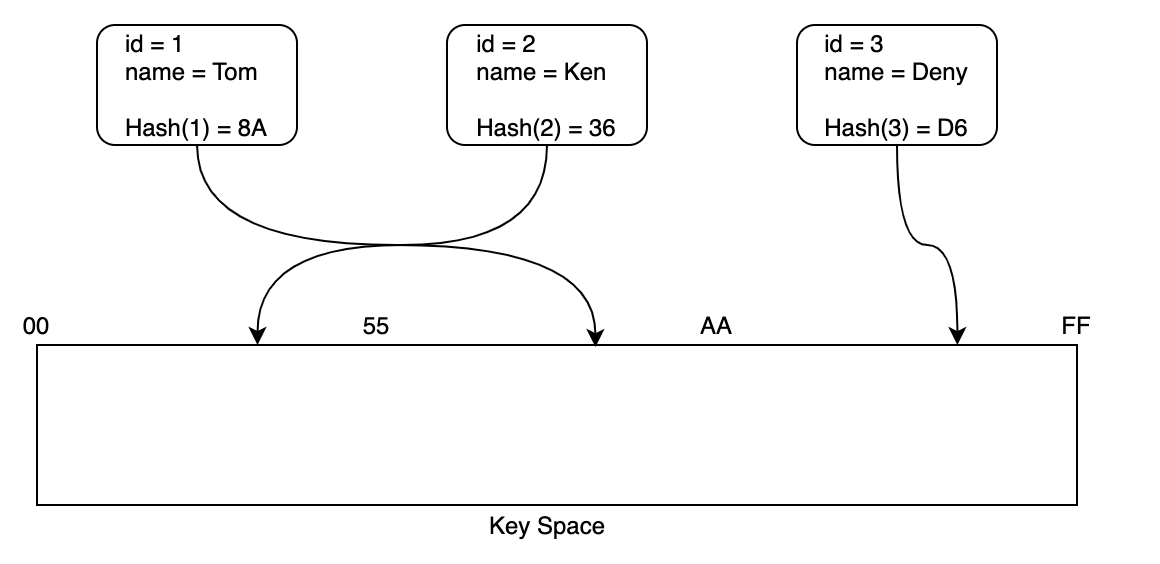
複合プライマリーキーの場合でも同様です。Hash-Keyによりいずれかのパーティションへ割り当てて、同一パーティションに含まれるItemはSort-Key順で格納されます。
table
- Hash-Sort-Table
key - Hash-Key: id
- Sort-Key: order
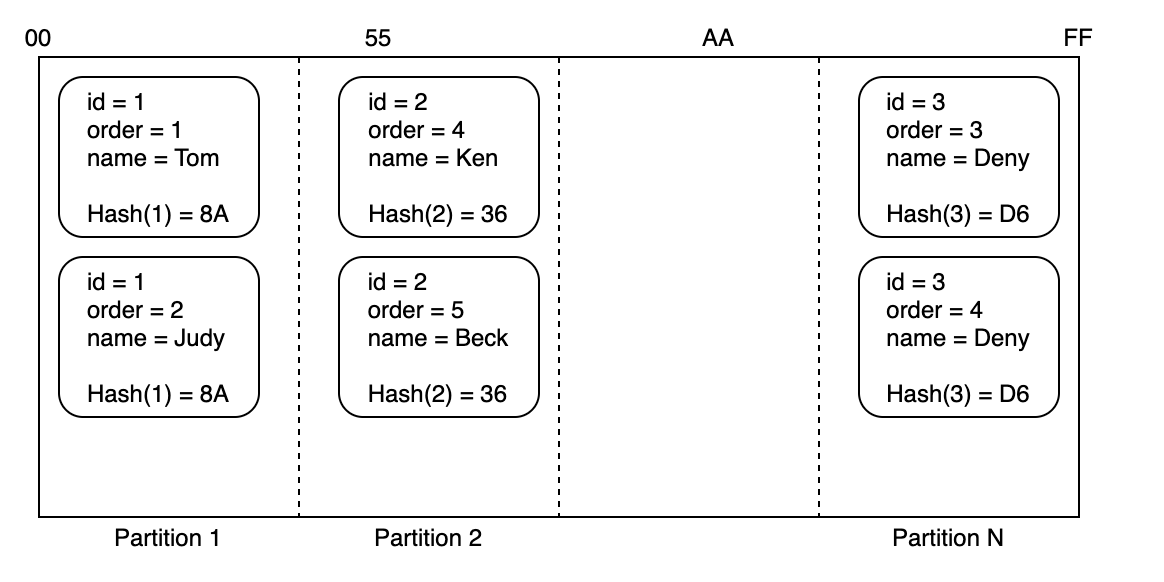
格納場所を特定するKey
DynamoDBは、全てのItemをプライマリーキーでソートした上で保持しています。
したがって、Hash-Tableの場合はプライマリーキーの値が分かれば、Hash-Sort-Tableの場合は複合プライマリーキーの値が分かれば、データの格納場所を一意に特定できます。DynamoDBから1MB以上データを取得するために、この一意となるキー情報を利用します。
1MB以上のデータ取得
- プライマリーキー: Hash-Table
- 複合プライマリーキー: Hash-Sort-Table
で分けて説明します。
Hash-Table
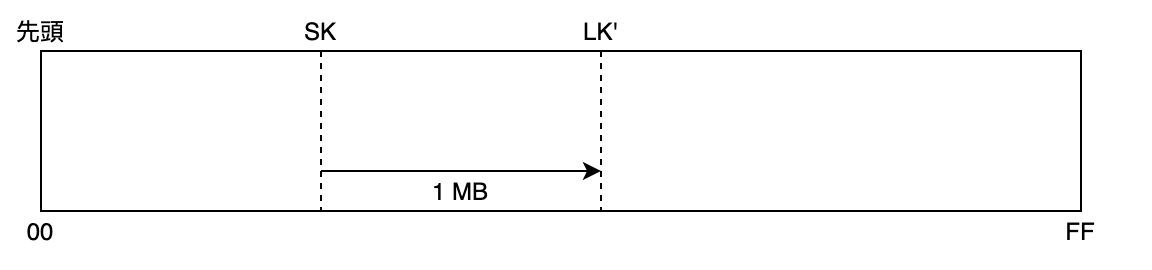
1MB以上のデータを持つテーブルへScanを実行した場合、テーブルの先頭から1MB分のデータと共に、LastEvaluatedKey(LK)が返されます。LKの値は、1MB分取得したデータの、最後のItemのプライマリーキーです。

1MB分データとLKを受け取った後、そのまま終わらせずにScanを再実行するのがポイントです
。
Scanの引数ExclusiveStartKey(SK)にLKを渡すと、LK地点から1MB分のデータが取得できます。EKはScanの開始位置をテーブルに伝えるため、プライマリーキーを渡すことにより、前回Scanの終了地点からデータ取得再開が可能となります。
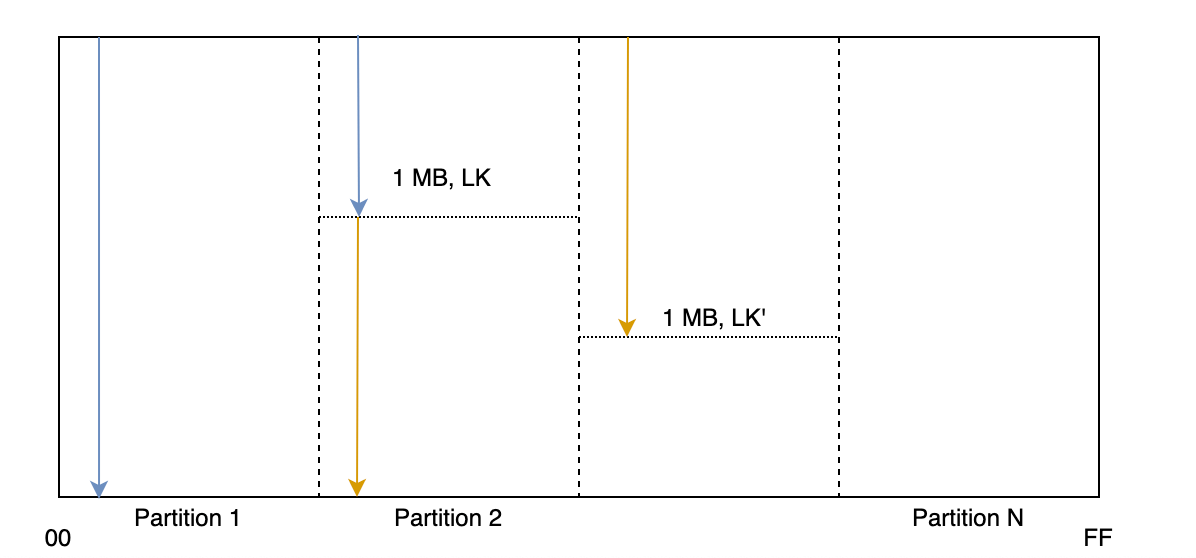
2回目のScanでも、初回と同様に 1MB分のデータ+LK’ が返されます。再度LK’を渡してScanすることにより、次の1MB分データを取得できます。このループを繰り返して、最終的にLKが返ってこなかった(空のLKが返ってきた)とき、テーブルのScanが完了したことになります。
Hash-Sort-Table
複合プライマリーキーの場合も考え方は同じです。
キーによってデータの格納場所が一意に特定されるため
- Scanで1MB分のデータとLKを取得
- 次のScanでLKをEKに代入
を繰り返すことで、全データを取得可能です。
以上で、図によるデータ取得方法の説明は終了です。
次は実装コードを見ていきましょう。
実装コードのサンプル
GoでDynamoDBから1MB以上を取得するコードのサンプルです。
import ( |
初回Scanでは空のEKを渡して、2回目以降はLKを代入します。空のLKが返されるまでループを継続することで、Full Scanが完了します。
まとめ
DynamoDBから1MB以上のデータを取得する方法について、図を多用して説明しました。
データがどのように格納されているのか? をイメージできるようになれば
- テーブル設計力の向上
- 処理コードのボトルネック特定
- 公式ドキュメントのより詳細な理解
につながると思います。
DynamoDBは難しいポイントが多いですが、1つずつ解決していきましょう。
最後まで読んでいただき、ありがとうございました!