最近はお客さんとの勉強会でDockerのドキュメントをつまみ食いして読むというのをやっていますが、改めて最新版を読んでみて、いろいろ思考が整理されました。2020年の20.10のマルチステージビルドの導入で大きく変わったのですが、それ以前の資料もweb上には多数あり「マルチステージビルドがよくわからない」という人も見かけるので過去の情報のアンラーニングに使っていただけるように改めて整理していきます。
仕事でPythonコンテナをデプロイする人向けのDockerfile (1): オールマイティ編で触れた内容もありますが改めてそちらに含む内容も含めて書き直しています。
本エントリーの執筆には@tk0miya氏から多大なフィードバックをいただきました。ありがとうございます。
基本的なメンタルモデル
現代的な使い方を見ていくために「Dockerを使ってビルドする」というのはどのようなものか考えを整理しておきます。
成果物のビルドはdocker build? docker run?
Dockerを理解するには「ビルド時」「実行時」のモードをきちんと理解する必要があると思います。「Dockerでビルドする」という言葉を聞いた時に次のパターンのどれに当たるのかをまず明確化します。
- docker buildで成果物を作る。成果物はDockerイメージ
- docker buildで成果物を作る。成果物はDockerイメージの中に含まれているバイナリを取り出したもの
- docker pull/buildで必要な処理系が入ったイメージをローカルに構築できる。docker runでビルドが実行され、マウントしたフォルダに成果物が出力される
- docker pull/buildで必要な処理系が入ったイメージをローカルに構築できる。docker runでウェブアプリケーションが起動する
これらはすべて「ビルドにDockerを使う」と表現できますが、前2つはdocker buildで成果物が作成され、後者はdocker build/pullでは開発環境が揃うだけで、ビルド自体は「実行時モード」で行われます。
2の「dockerビルドでイメージを作るが成果物はバイナリ」というのは以前にはなかったユースケースで、おそらくは3の「docker runでビルドするときに出力フォルダをマウントしてそこに書き出す」を代わりに使っていたと思いますが、20.10以降に入った(と思われる)local exporterの機能で最終成果物のビルドイメージからファイルを取り出せるようになりました。
docker build --output=. . |
3、4ではファイル変更時の自動ビルドの仕組みが組み込まれることも多かったと思いますが、dev containersの中での開発で、その中でファイル変更検知と自動ビルドやリロードを組み合わせる方が快適かと思います。開発時のローカルファイルシステムとの同期の速度が問題になることがありましたが、最初からDockerの中でファイルを編集するdev containers時代では過去の話です。docker runで成果物を作るというユースケースはVSCodeやJetBrains製IDEを使っている以外ではあまりなさそうです。
マルチステージビルドは当たり前
docker buildで作成する場合はマルチステージビルドが前提となります。マルチステージビルドじゃないDockerfileは、現代においては丁髷を結ってパンツの代わりにふんどしを履いているようなものです。
もう耳タコだと思いますがマルチステージビルドの特徴は以下の通りです。
- メンテナンス性向上: 最終成果物のイメージ以外ではサイズを意識したトリッキーな記述が不要になる
- RUNを無理にまとめて、失敗箇所がわかりにくくなったり、途中のステップでキャッシュが効かなくなることがなくなる
- ビルド速度アップ: 並列化できるステップは並列実行されパフォーマンスが上がる
- ビルド速度アップ: キャッシュやtmpfs、ソースコードの参照など、ファイルシステムの最適化オプションが多い
- セキュリティアップ: クレデンシャル情報を扱う仕組みが整備された
ビルドの流れの整理
マルチステージビルドを活かすためにはまずビルドの処理の流れ・ファイルの流れ・ファイルの特性を整理します。
- 変更が少ないものから処理する(処理系→サードパーティライブラリ→自分たちのソースコード)
- ビルドのみ必要なもの、デプロイで必要なものを認識する
言語によって多少の違いはありますが、ジェネリックな感じでかいたのが次の流れの図になります。矢印の方向に処理が順番に流れていきます。そのステップで変更がなければレイヤー単位でキャッシュが利用されるため、変更されたレイヤー以降しか再実行されません。
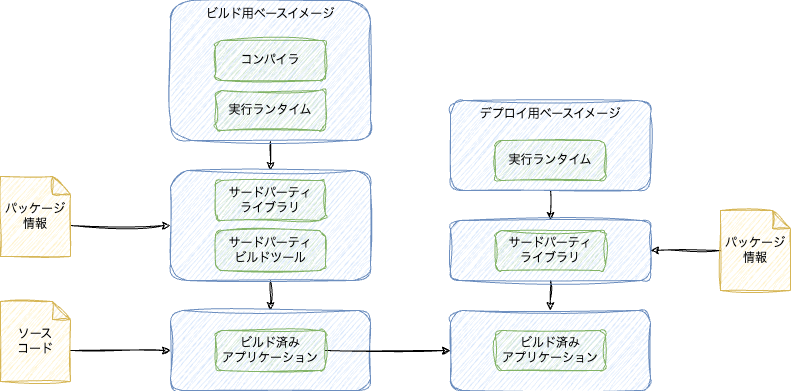
ビルド用ステージのビルドステップとソースと成果物
ビルドの方から見ていきます。
まず処理系(Java JDKとか、Node.jsとか、Pythonとか、Goコンパイラとか)が一番変化が少ないでしょう。これはなるべくベースイメージに焼き込まれたものを使います。そうすればイメージのダウンロードだけで使えます。ビルドのたびにaptで処理系をダウンロードするのは遅くなります。ビルドイメージは最終成果物ではないため、これのサイズを小さくする努力をする必要はありません。
次にパッケージ情報のファイルを使ってビルドに必要なサードパーティのライブラリ、ビルドツールなどをダウンロードします。一番変更が多いアプリケーションのソースコードは最後に取得してビルドします。このような流れにすると、変更が小さいファイルほどキャッシュが使われて実行効率が上がります。
Node.jsはTypeScript利用だとインタプリタであってもビルドが必要かもしれません。Pythonであればビルドは不要ですが、テストだけ実行するとかはあるでしょう。
Node.jsやPythonなどのインタプリタ言語の場合、Cコンパイラが必要な実行用のライブラリ(かつバイナリパッケージが提供されていない場合)はそのインストールにもビルド環境が必要になるため、コンパイラ言語のビルドと同様に、ライブラリのビルドとデプロイ用のステージを分けてインストールされたライブラリ(Pythonだとsite_packages、Node.jsだとnode_modules)を持ってくる必要があります。
デプロイ用ステージのビルドステップとソースと成果物
デプロイ用の方は、コンパイラなどが入っていないランタイムだけの最低限のベースイメージをもとにします。実行用にサードパーティライブラリが必要であればそれをダウンロードします。あとはビルドの結果をビルド用イメージから持ってきます。
Goはデプロイ用の方はライブラリ全部入りのシングルバイナリになるため、デプロイ用のベースイメージはDebian Slim系のシンプルなものを利用できます。サードパーティライブラリはもしかしたらCGO使っているものは実行用の何かしらのライブラリが追加で必要かもしれません。
Javaなんかは最近は必要なライブラリが全部入りのFat JARをビルド時に作成するのでデプロイ用の方にはそのJARファイルをコピーするだけでサードパーティライブラリは不要でしょう。また実行ランタイムはJREを使います。あるいはGraalVMのネイティブビルドだと、Go同様に何もランタイムもないベースイメージに成果物のネイティブバイナリだけ持ってくれば良さそうです(が僕はまだやったことはないです)。
Dockerfileの書き方
COPY/ADDは(コンパイル言語では)もう使わない
Dockerは実行時にローカルの作業フォルダ(コンテキスト)のファイルをがばっと取得します。それを必要に応じてCOPYやADDでビルド用のレイヤーに持ってくるステップがあり、その後ビルドするという流れが過去のDockerの常識でした。
FROM golang:1.22 AS builder |
しかし、bindマウントの登場でそれは過去のものになりました。
| コマンド | 役割 | レイヤー | その他 |
|---|---|---|---|
COPY |
コンテキスト/他のビルドステップからファイルを持ってくる | 残る | |
ADD |
コンテキスト/他のビルドステップからファイルを持ってくる | 残る | 圧縮ファイルを展開したりGitに対応 |
RUN --mount=type=bind |
コンテキストのファイルをそこにあるものとして扱う | 残らない |
ファイルを持ってくるのはRUNコマンドで必要に応じてコンテキストとのマッピングを行うため、COPYというステップは不要です。下記のサンプルはそこの部分のみのサンプルです(まだこのままでは完全ではなくイメージです)。
# syntax=docker/dockerfile:1 |
COPYが登場するのは、RubyやPythonなど、ソースのファイルそのものを実行環境で使う場合や、マルチステージビルドで、別のステージから成果物のファイルを持ってくる場合のみです。そのままソースやアセットを使う場合をのぞいては、次のように--fromがつくCOPYしかあってはならない、ということになります。
COPY --from=build-server /bin/server /bin/ |
レイヤー自体のキャッシュと、レイヤーをまたいだキャッシュ
Dockerを使わない普通の開発では、サードパーティパッケージのダウンロードなどは、ローカルのダウンロード済みのファイルは再ダウンロードしないような動きをします。毎回全部をダウンロードしたりはしません。今までのDockerではレイヤーのキャッシュであり、1つでも新しいパッケージを追加すると全部がリセットされてしまっていました。
マルチステージビルドのキャッシュはレイヤーごとのキャッシュではなく、実行時のステップでフォルダごとに指定します。同じフォルダを指定するとレイヤーをまたいでキャッシュが共有されます。
RUN --mount=type=cache,target=/go/pkg/mod/,sharing=locked \ |
このキャッシュはイメージの外に作られるのでダウンロードしたパッケージでイメージが増えることもなくなります。
どのフォルダをキャッシュにすべきかは言語処理系とかツールとかによって変わってきます。
apt-getの最新の書き方はこんな感じとのこと。
RUN \ |
docker initコマンドでいくつかの言語は最適な書き方のDockerfileは生成されそうです。例えばNode.jsだと次のような感じ。
RUN --mount=type=bind,source=package.json,target=package.json \ |
Pythonだとこう。
RUN --mount=type=cache,target=/root/.cache/pip,sharing=locked \ |
配布物に入る、実際に実行時に参照されるファイルはキャッシュの外にするようですね。Node.jsだとnode_modulesとか、Pythonだとsite-packagesとか。
なお、キャッシュはデフォルトでは「ターゲットが同じものは同じキャッシュを見ている」とみなされます。id属性をつけると同じパスでも別物としてみなされます。sharing=lockedをつけると同時に同じ参照するとロック状態になってしまうのですが、idをつければ回避可能です。ただ、複数箇所で同じパッケージを利用するならロックになってでも待ったほうが早いかもしれません。
イメージが小さいのは良いことだが…
公式ドキュメントではAlpineを勧めていますが、LinuxのC言語のランタイムのDebianなどが使うglibcとAlpineのmuslを比べると実行性能が3-5割程度変わることがあります。後者はフロッピーディスク向けのサイズ重視の実装で、前者はインテルの開発者がCPUごとに最適化をアップストリームにコミットしてきたものであり、少しでも性能が良くなるように作り込まれてきました。
すでに過去のブログでも書きましたが、Debianベースのイメージを使う方が良いです。
この当時と違うところは、Pythonの場合ではmuslベースのバイナリ形式のライブラリの作れるようにはなったので、muslを使うだけでビルド済みライブラリが使えなくてインストール時間が50倍になるというのはなくなったようです。ただ、実行速度の問題はなくなっていません。
Debian系列だとシェルが存在しなくてセキュリティに強いベースイメージもあります。
Alpineを選んで25MB変わったところでストレージのコストや転送時間は対して変わりませんが、CPU性能が落ちて、その分余計に処理時間が伸びて増えるコストの方が膨大なので、Debian系のベースイメージを使うべきです。
イメージのカスタマイズ
Dockerfileの形式のよくないところは、ビルドする人や利用者がカスタマイズできるような自由度を持たせられるのですが、どのような自由度があるのかを利用する側が把握しにくいというものがあります。プログラミング言語だと、関数やメソッドの引数として一箇所に情報がまとまっており、そこを見れば何を与える必要があるのかが解読しやすいのですが、Dockerfileは全体を見ないと引数やカスタマイズポイントがわからないし、場合によってはアプリケーションの中にハードコードされていたりするとDockerfileだけではわからない、ということがあります。
ビルド時の動作のカスタマイズ、実行時のカスタマイズに分けて紹介します。
ビルド時のカスタマイズ: 設定
ビルド時の設定はARGでデフォルト値とともに定義します。環境変数のように命令の一部を書き換えるといった使い方ができます。
ARG GO_VERSION=1.22 |
コマンドラインで実行するときに-build-arg引数で設定できます。
# 単体のイメージのビルド |
composeを使って、サービスごとに設定する、ビルド時には決まっているというのであればcompose.yamlファイルのbuild階層以下のargsに設定が書けます。
services: |
環境変数はDockerfile内にENVで設定できますが、これを実行時に変更する方法はありません。次のようにARGとENVを組み合わせて環境変数のデフォルト値を上書きを行えるようにします。ただし、ENVを使うとイメージに焼き込まれてしまうため、シークレット情報の設定には使わないようにしましょう。
ARG NODE_ENV=production |
--platform引数は特別なARGとして扱われます。次のようなに渡すと、3回ビルドが行われます。すべてLinuxですが、CPUアーキテクチャ違いで3回ビルドされます。TARGETOSはlinuxが、TARGETARCHはそれぞれのビルド時のCPUアーキテクチャが入ります。またベースイメージ選択などはこのパラメータが参照されます。
docker build --platform=linux/amd64,linux/arm64,linux/arm/v7 . |
Goを使っている場合はビルドのクロスコンパイルで利用します。
RUN --mount=type=cache,target=/go/pkg/mod \ |
公式ドキュメントではxxというのが紹介されており、C++コンパイラやらRustやらのクロスコンパイルができます。
ビルド時の成果物
マルチステージビルドはFROM、もしくはCOPY --fromでステージをつなげていきますが、必ずしも最後のステージにつながっていかないといけない、ということはなく、終点がいくつあっても問題ありません。
次のDockerfileはgoプロジェクトに対してdocker initで生成されたものをベースに、(気に入らない実行時のalpineイメージをdebianにしつつ)buildステージをbaseとbuildに分けた上で、vetとtestを追加したものです。順番的にfinalステージが最後というのはそのままです。
# syntax=docker/dockerfile:1 |
図にするとつぎのような流れになっています。
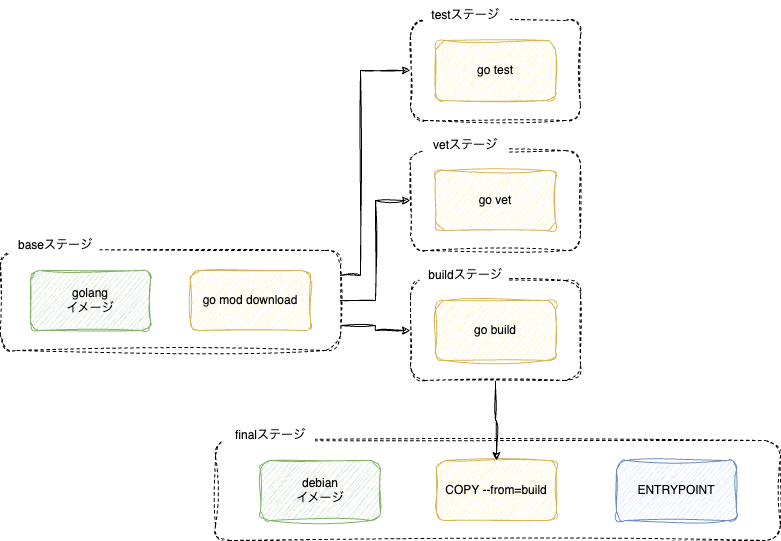
これをそのままビルドすると、最後にあるfinalが実行されます。途中で依存のあるbuildとbaseも実行されますが、finalにつながっていないtestステージとvetステージは実行されません。--targetフラグをつけると最終的に実行されるステージを選択できます。この場合、finalの実行は行われずに、go testだけが行われることになります。
docker build --target=test . |
成果物が微妙に違うDockerfileをたくさん作らなくても良くなると同時に、ちょっとしたサブのタスクをクリーンな環境で行わせることがしやすくなります。
ビルド時のシークレット
ビルド時に、社内のNexusにパッケージを取りに行かないといけない、privateなGitHubへのアクセスが必要と言った場合にシークレットキーですが、イメージの中に書きたくない情報になります。
これらの情報の渡し方として、Twelve-Factor App を引用して、環境変数を使うべしというのもあります。最初に説明した「ビルド時」「実行時」となりますが、ビルド時の環境変数はイメージに書き込まれてしまうためセキュアでなくなってしまいます。
そのような漏れては困る情報を扱う機能がDockerにはあります。ビルド時に活用する方法と、実行時に活用する方法がありますが、本エントリーではビルドの方に絞って紹介します。各シークレット情報はidを持ちます。変数名のようなもので、このidに割り当てしたり、そこから取り出すといったことを行います。ドキュメントで触れられている渡し方は以下のとおりです。
# ファイルからmytokenに設定 |
ビルドを実行するDockerfile側ではこの変数をどこに置くかを決定します。何も書かなくても /run/secrets/[シークレット名]のファイルにシークレット情報が書き出されるので、そこを読み込むと参照できますが、特定のファイルに書き出したり、環境変数に設定できます。これもレイヤーにならないように、マウントの構文を使って行います。
# シークレットの内容をファイルに特定のファイルに出力 |
シークレットはdocker composeにはあります。docker runにはありません。本番環境を見据えた実行モードのDocker Swarm(昔にも同じ名前のものはあったが別物)のdocker service createにはあります。
実行時のカスタマイズ:設定
イメージの利用時には何かしらの追加の設定が必要なことがほとんどでしょう。外部にサービスを提供する場合はポートを開く必要がありますし、データの永続化したり、外部から設定ファイルを一式取り込んだりをするのであればボリュームを作ってマウントする必要がありますし(そうでないとコンテナを終了したら消えてしまう)、動作をカスタマイズするのに環境変数を設定します。
そのような情報はDockerfileだけを見てわかるようにしてあげると良いでしょう。次のディレクティブを明示的に書いておくことでわかりやすくなります。
EXPOSE 80 |
EXPOSEはここで宣言したからといってポートが開くわけではなく、完全に利用者向けの情報提供のディレクティブです。ENVは環境変数を宣言しますが、これはデフォルト値として機能します。
VOLUMEは本来はボリュームを作るディレクティブですが、コンテナクローズ時に消えてしまう無名ボリュームしか作れないためほとんど役に立たないのですが、ECSではここで宣言したボリュームしかマウントできないようになっているなど、EXPOSE同様ラベルとして認知されてきています。
dockerコマンドで実行する場合は次のようにオプションを指定します。現在はボリュームの指定は-vではなく、--mountの方が細かく制御が行えるために推奨されているようです。また、ボリュームがtmpfsの場合も--tmpfsフラグがあるもののSwarmモードで使えなかったりオプションが設定できないなどで--mountの方を推奨していそうな雰囲気があります。また、ホスト側のファイルシステムと共有フォルダを作るバインドマウントのパフォーマンスが少し前までのDockerの話題ではよく出てきていましたが、そもそもなるべく使って欲しくなさそうな雰囲気を出しています。大きなコードベースをDocker内部でビルドする場合はDev Containersの方が良いでしょう。
実際に利用時に設定する方法は次の通りです。
$ docker volume create mydata |
composeで同じことをするのは次の通りです。
services: |
実行時のカスタマイズ:コマンド
Dockerfileで最終的に実行するコマンドはENTRYPOINTとCMDの組み合わせで処理されます。ENTRYPOINTが実行可能なプログラムのパスが入っている場合、CMDはそれに対する引数となります。ENTRYPOINTがない場合はCMDが単独で実行されます。
CMDはdocker container runの引数を渡すことで簡単に上書きできます。Pythonの公式イメージはCMD ["python"]のようなイメージなので、「ちょっと環境調べてみるわ」とbashを起動するには次のようにします。
docker container run --rm -it python:slim bash |
Pythonの場合は本番イメージではgunicornを起動コマンドとして使ったりして必ずしもPythonが起動コマンドでなかったりするため、CMDだけ指定すると利用者は便利です。Rubyはデフォルトでirbが起動するようにCMDに設定されています。
ENTRYPOINTを指定すると、CMDは引数でしかなくなるため、container runの引数ではコマンドは上書きできなくなります。絶対に指定されたコマンド以外起動させないぞというサーバープログラムなんかはENTRYPOINTで起動コマンドを指定すると良いかもしれません。手元にあったイメージだとJaegerはENTRYPOINTで起動するようになっていました。
あと、PostgreSQLはdocker-entrypoint.shがENTRYPOINTになっており、CMDがpostgresとなっています。これは実行前のスキーマやデータ投入のスクリプトを実行してからDBを起動するためにこうなっていますが、docker container run postgres psqlでpsqlコマンドも起動できるようになっています。このように、ENTRYPOINTとCMDの組み合わせで、イメージの柔軟性をあげられます。
成果物をビルドするbuildの仕方
最初にdocker runで成果物をビルドするのは今時のDockerの流儀ではなさそうというのを紹介しました。--outputをつけてビルドを行うことで特定のステージの任意のファイルを取り出せます。
docker build --output=bin --target=final . |
落ち穂拾い
最後におまけでよく知られていそうな新旧の差分を軽く紹介します。
- docker runではなく、docker container run
- Dockerfileにはフォーマット指定コメント(
# syntax=docker/dockerfile:1)を入れる - DockerでRUNをまとめた方が良いとは限らない
当社のブログの「個人的docker composeおすすめtips 9選」も参照してください。こんな感じの変更がありました。それ以外のも便利機能がいくつか紹介されています。
- docker-composeではなくdocker composeサブコマンドを使う
- docker-compose.yamlではなく、compose.yamlファイルを使う
- compose.yamlファイルの先頭のバージョン指定(
version: '3')は書かない。 - depends_onを使って依存関係を記述する(linksは使わない)と、ヘルスチェックの結果を待って正しい順序で起動できる
ただし、Dev Containers(公式ドキュメント見てもTitle Case, 大文字小文字がぶれているので正式な名前はわからない)では旧来のdocker-composeコマンドを使うのでdocker-compose.yamlじゃないと(あるいは設定で明示的に指定する)だめそうで、新しい機能も使えないかもしれない点には注意です。
まとめ
このような古い情報は世の中に溢れていて、実際、マルチステージビルドがリリースされた後も古い記事がたくさんあり、記事の日付を見ても区別がつきませんが、この記事の内容を把握したら、そのような記事を見ても、生成AIが古臭いコードを生成してきても判断できるようになるでしょう。
Dockerの使い方を紹介する中で、macはバインドマウントが遅いというのをよく見かけましたが、そもそもDockerのメンタルモデルとしてはそのような使い方は想定外ということがわかります。ツールの想定通りの使い方をして正しくDockerのパフォーマンスを引き出したいものです。
今回紹介しなかったものにBakeというexperimentalなツールがあります。ビルド時のパラメータが複数あって組み合わせも登場するとなると、それをオーケストレーションするツールが欲しくなります。bashとかMakefileでもいいとは思いますが、Docker公式では新たなツールを提供してくれています。マトリックスで組み合わせが設定できたり、複数ターゲット向けに多数のバリエーションを提供している人には便利そうです。
まだドキュメントリーディングは途中ですので、また新たなテクとか考え方が出てきたら適宜更新版を出していこうと思っています。