サーバーレス連載の3回目は検索エンジンを作ってみたお話です。
クラウドサービスが充実してくるにつれて、サーバーレスではいろいろなことができるようになっています。HTTPサーバーは動きますし、RDBやNoSQLなストレージも使えますし、PubSubみたいなサービスも利用できます。これらを駆使するとそこそこ複雑な処理も記述できます。
一方で、上から下までサーバーレスにしようとするとできないものもいくつかあります。例えば、RDBも使えるといっても制約があり、LambdaやCloud FunctionsからRDSやCloudSQLを雑に使うとコネクションを張りすぎる問題があります。LambdaにはRDS Proxyが出始めています。あと、RDBそのものは基本的に常駐型なのでサーバーレスではないです。一応サーバーレスなのもありますが、起動時間が結構かかるらしい(自分ではまだ試してないです)。それ以外にもキャッシュ系のサービスがなかったします。
中でも検索エンジンがない、という話はよく聞きます。Google App Engineの1st Genにはあったのですが、2ndにはなくなりました。これの代替サービスはありません。自前で建てると言えばElasticsaerchですが、ESはオンメモリDBなので、サーバーレスではなくなってしまいます。
ずっと前に、前職の同僚の末永さんから検索エンジン自作入門~手を動かしながら見渡す検索の舞台裏の献本を頂いていて、本の趣旨的には、実装してから感想を書かないといかんな! と思いつつ、なかなかチャンスがなかったのですが、今回この本のロジックを参考にサーバーレス環境用の検索エンジンを作ってみました。コードはGitHubにアップしています。名前はwatertowerです。サーバーレス→略してSLなので、蒸気機関車用語で良さげなのいっぱいあるんじゃないかと思って探したけど、まあ地味に給水塔です。
アーキテクチャ
検索エンジン自作入門をなぞって実装します。サーバーレスでやる以上、ストレージのサイズは小さくしたいところなので、N-Gramではなく形態要素解析を使うことにします。日本語はkagomeを使います。英語は分かち書きは不要ですが、Snowball Stemmerを使ってStemmingをします。TF-IDFによるスコアリング、符号化による圧縮にもチャレンジしてみたいですね。この本ではC言語を使っていますが、Goで実装します。
RDBを使っちゃうとストレージがサーバーレスではなくなってしまうので、DynamoDBとかFirestoreを使うことにしました。GoCloudは以前このブログで連載してとりあげましたが、今回の実装もGoCloudを活用します。同一のコードでGCPでもAWSでもAzureでも柔軟にアクセスできます。
単に自然言語で検索するだけならかんたんですが、実用性を考えると、タグでフィルタリングとかも欲しいですよね。Elasticsearch的にこんな感じのマッピングがハードコーディングされている、という感じのデータ構造にしてみます。Elasticsearchの「検索がめっぽう強いドキュメントDB」みたいなのは良いな、と思ったのでちょっとしたデータを持てるようにしています。
{ |
GoCloudのmemdocstoreを使うと、オンメモリで動作するので、ユニットテストが超高速ではかどります。
実装したのは主に1つの構造体なんですが、長くなったので3分割しています。
- watertower.go: WaterTower構造体の定義と初期化まわり
- database.go: ドキュメントの登録や削除、検索などの
- search.go: 検索してスコアをつけてソートして返す
ユニークなドキュメントIDを振るために、シーケンシャルなカウンターも実装しました。NoSQLだと秒間更新数が決まっていたりするので、10個ぐらいのエントリーに分けてランダムにインクリメントし、最新のIDを取得するにはこの10個の値を合計して返す、みたいな感じです。
検索ロジック
ということで、最初に実装したのは、テーブルが4つある検索エンジンです。
- 単語→Doc IDと登場位置のリスト(ポスティングリスト)
- Doc ID→ドキュメント本体
- ユニークキー→Doc ID
- タグ→Doc IDのリスト
最初の2つが自然言語検索用です。最初のテーブルが、タイトルと本文を形態要素解析した単語をキーにして、ドキュメントと登場位置のインデックスをまとめたものです。検索ワードも同様に形態要素解析してから、このテーブルを引っ張ってきて、Doc IDの積集合を取ると、検索ワードにひっかかった文章がわかるというわけです。これでDoc IDがわかるので、本文を2つ目のテーブルで取得して返せば、検索は完了します。
このシステムをドキュメントDBだとすると、文書を一位に特定するもの、例えばURLだったりから取得できる必要があるため、3つ目のテーブルを用意しています。
最後がタグのフィルタリングです。これも、タグが含まれるDoc IDのリストが取得できるため、この積集合をさらに取れば、自然言語検索の結果を絞り込むことができます。基本的な検索のロジックはこんなところです。
さらなるフィルタリングとしては、フレーズ検索によるフィルタも入れています。3つのキーワードで文章検索したら、その3つのキーワードが登場するだけではなく、検索キーワードと同じ並びで含まれるという単語の登場位置も見ています。
最後にTF-IDFで単語の登場頻度でスコアをつけてソートします。タイトルはちょっとスコアを上げる、みたいなこともしていたかな?
samples/httpstatusに、HTTPのステータスコードを検索できるコマンドのサンプルがあります。ユニットテストで便利なmemdocstoreをそのまま使い、起動時にドキュメントを一通り登録してから検索をする、CLIツールです。
ダメダメそんなんじゃダメ
というわけには行かないのがDynamoDB。DynamoDBは起動時間に寄らない課金体系になっていますが、キャパシティユニットというのがあります。キャパシティユニットを増やすと秒間のアクセスできる回数が増えます。しかし、キャパシティユニットはテーブルごと。無料枠もありますが、基本的にテーブルを増やせば増やすほどお金もかかります。
上記のテーブルがどれぐらいアクセスがあるかの比率なんて、使われ方によって変わってきますので、最適なチューニングを目指すのは大変です。チューニングとかしないで利用しただけ課金にしたい、という本来のサーバーレスの趣旨とは反します。
というわけで、全部のデータ構造を1つのテーブルにまとめます。ユニークキーならk、ドキュメントならd、単語ならw、タグはtと主キーにプレフィックスをつけて、1つのテーブルに統合しました。サーバーレスならテーブル一個用意すれば使えます、という手軽さがないと意味がないですからね。手間暇かけるぐらいなら、Elasticsearch使ったほうが良いですし。
というわけで、1つのテーブルで全部のデータを格納するように実装を修正しました。
せっかくならウェブインタフェースも
これで使える検索エンジンはできました。実際にはウェブサービスとしてHTTPサーバーの上で使われるはず。もしかしたら単体のウェブサービスとして起動できたら便利かな? と今週の月曜日にふと思って、ウェブサーバーも実装してみました。
Goの構造体を作ると、そのメソッドがそのままJSON-RPCの外部IFになってくれるgithub.com/semrush/zenrpcか、gRPCか、REST APIかで悩んだんですが、gRPCはウェブ上に記事がいっぱいあるのでやっても面白くないですよね。JSON-RPCはそういう意味ではレアなのでいいのですが、せっかくElasticsearchのようなフレーズ検索もタグ検索も可能な仕組みなので、Elasticsearch互換のREST APIにチャレンジしてみます。
本ブログで、多賀さんと、武田さんがいろいろ紹介してくれていますので、使ってみました。go-swaggerとStopLight Studioを使いました。結果としてはとても良い体験が得られました。
Elasticsearchクローンといっても、全部はできないので、インデックスに対するドキュメントの追加、削除、IDでの取得、検索ぐらいを定義しました(PUTはswagger上では定義したけど本体側に更新のAPI作ってなかったので使えません)。
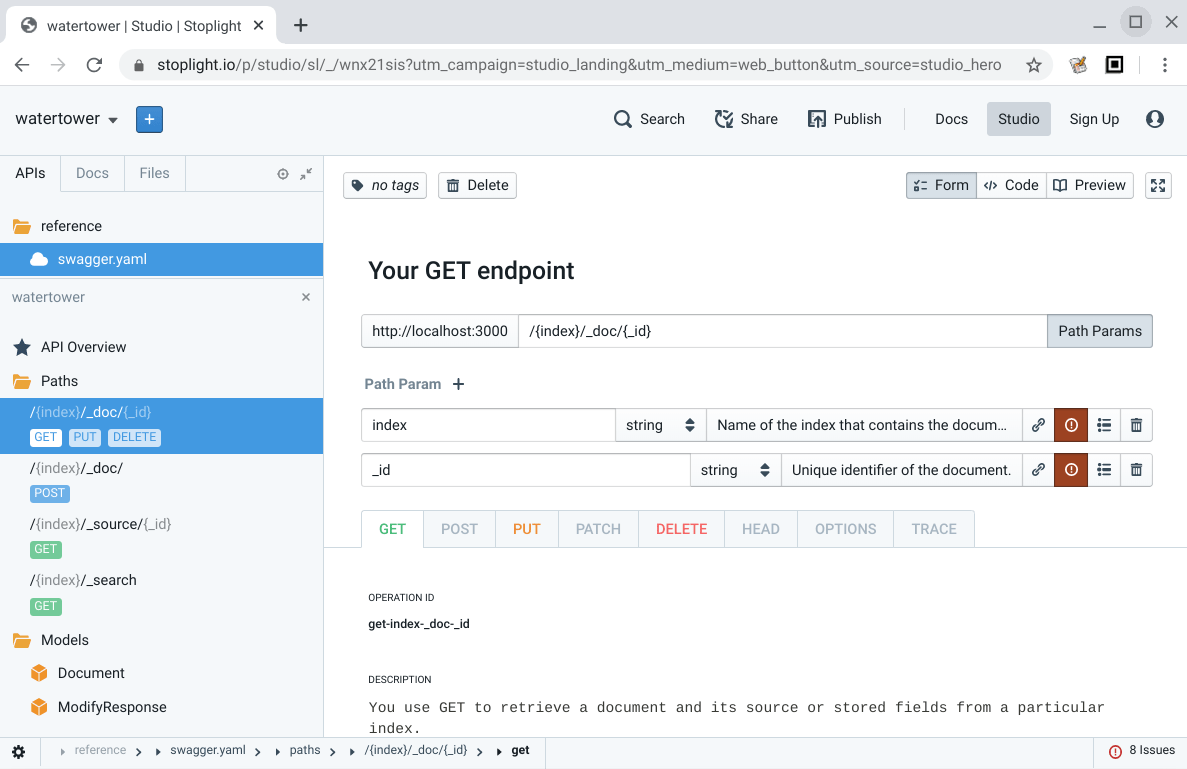
検索は?q=unique_key:ユニークキーの値で、キーでの取得もできるようにしていますが、検索エンジンっぽい検索は、次のようなクエリーだけが処理できるようになっています。今後ももっといろいろ実装したいですね。ちなみに、内部では自然言語検索ではタイトルと本文を両方検索しちゃうので、titleだけに含まれるキーワードの検索とかはできません。
{ |
cmd/watertower-server以下に実装があります。次のように起動します。WATERTOWER_INDEXES環境変数でカンマ切りで指定するとインデックスを増やせますが、デフォルトはindexとなります。WATERTOWER_DOCUMENT_URL環境変数で、保存先を設定します。デフォルトのmem://でオンメモリ動作します。dyanamo://とか、firestore://とか、mongo://とかも使えるはずです(localStackのDynamoしかテストしてないですが)。
./watertower-server --port=8888 |
あとはcurlでいつものElasticsearchのように使えます。
# ドキュメントの登録 |
動きました。めでたしめでたし。Elasticsearch IFは後付けだったので、タイトルの文字列のスコアのBoostingはクエリー側で重みを設定できたりできないとかありますが、そのうちなんとかするかも。
まとめ
まだ実用的に使ってみてはないのですが、これでサーバーレスなサービスでも検索ができるようになります。今回は保存と検索を両方ともアクティブに行う前提でNoSQLなストレージを選択しました。まあ、うちの会社だとRDBを常時起動するケースがほとんどなので、RDBバックエンドも選べるようにしても良かったかもなぁ、と作ってから思いました。それ以外のケースで、更新頻度が少ないのであれば、バッチで転置インデックスを作成してS3に置いて、フロント側は読み込み専用で使う、みたいなのもあってもいいかもなぁ、と思いました。ブログみたいに誰かが更新しない限りインデックスも変更されないような場合ですね。
静的な検索だけしかしない、というユースケースを想定するなら、インデックスを検索エンジンのバイナリに書き込んでしまって、WebAssemblyにしてしまうというのも手です。なんか、今どきのCDNはWebAssemblyが動くらしいですし、CDN上で走らせても面白いんじゃないかと。Goはバイナリが大きいのでGo製のWebAssemblyバイナリはブラウザで動かすのはダウンロードのオーバーヘッドが大きくて、どこで使えばいいのか悩んでいましたが、エッジで動くならぜんぜんありですね。
互換インタフェースをつけてみたとはいえ、絶対的な検索速度の性能だけじゃなくて、台数を増やせば増やすほどスケーリングする点、マッピングの柔軟性、運用ノウハウetcな点では圧倒的にElasticsearchのほうが上です。たまーにしか使わない管理画面とかにも検索機能つけたらよくね? ぐらいな気持ちで作り始めたので、常時起動してもきちんと使われるとかであればElasticsearchを使うほうが良いです。
本を頂いてから6年越しになってしまって非常に申し訳なかったのですが、ようやく実装できました。「サーバーレスでやる!」というコンセプトが決まってしまったら、あとはスムーズにできました。とても良い本です。実装の仕方の本ですが、Elasticsearchとかも基本的には同じ転置インデックス型のはずなので、今まで既製の検索エンジンを使うだけだった人も、より詳しくなってElasticsearchの気持ちを理解するには良い本じゃないかと思います。
今週末は都心近くの人はみんなお出かけはしないでしょうし、何か暇つぶしを探している方は、ぜひ検索エンジンを作ってみると良いと思います。
検索エンジン自作入門以外にも手を動かす系書籍の[ゲーム&モダン JavaScript文法で2倍楽しい]グラフィックスプログラミング入門も杉本さんから献本を頂いてしまっているので、今度は一年以内には・・・
サーバレス連載の3本目でした。次は佐藤さんのFirebase CrashlyticsでAndroidアプリのエラーログをさくっと収集するです。